구글에서 진행했던 조대협님의 텐소플로우 강의와 김성 교수님의 강의를 듣고 개인적으로 공부하면서 정리한 내용입니다
아래 소스는 김성 교수님 강의의 소스를 그대로 가져왔고, 수업을 들으면서 주석으로 정리한 부분입니다
MNIST
그 유명한 MNIST 데이터셋을 이용하여 손글씨 데이터를 통해서 손글씨 숫자를 예측하는 부분을 학습해 보도록 하겠습니
epoch / batch_size
epoch : 전체 데이터 셋을 한 번 돈 것을 1 epoch이라고 한다 batch_size : 한번에 돌리는 데이터 사이즈
ex) 1 epoch : 1000개의 트레이징 데이터를 500개의(=batch_size)로 2번(=iterations) 돌았을때
import tensorflow as tf
import random
import matplotlib.pyplot as plt
tf.set_random_seed(777) # for reproducibility
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # Y값을 One Hot으로 읽어오게 됩니다
nb_classes = 10 # 0~9개라 총 10개
X = tf.placeholder(tf.float32, [None, 784]) # MNIST data 이미지 모양 28 * 28 = 784 (입력값)
Y = tf.placeholder(tf.float32, [None, nb_classes]) # 0 ~ 9개라 10개의 값을 예측 (출력값)
W = tf.Variable(tf.random_normal([784, nb_classes])) # [입력값, 출력값]
b = tf.Variable(tf.random_normal([nb_classes])) # [출력값]
# Hypothesis (softmax를 이용)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
# Cost 함수 구하기
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# Test model
is_correct = tf.equal(tf.arg_max(hypothesis, 1), tf.arg_max(Y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
# parameters
training_epochs = 15
batch_size = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 위에서 변수를 사용하기 위해서 변수를 초기화 함
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # batch_size만큼씩 읽어라
c, _ = sess.run([cost, optimizer], feed_dict={X: batch_xs, Y: batch_ys})
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print("Learning finished")
# Test the model using test sets
print("Accuracy: ", accuracy.eval(session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
# 임의의 한 값을 가져와서 예측하기
r = random.randint(0, mnist.test.num_examples - 1) # 랜덤하게 1개를 읽어옴
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r:r + 1], 1)))
print("Prediction: ", sess.run(tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r:r + 1]}))
plt.imshow(
mnist.test.images[r:r + 1].reshape(28, 28),
cmap='Greys',
interpolation='nearest')
plt.show()
결과
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Extracting MNIST_data/train-images-idx3-ubyte.gz
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
('Epoch:', '0001', 'cost =', '2.826302762')
('Epoch:', '0002', 'cost =', '1.061668980')
('Epoch:', '0003', 'cost =', '0.838061326')
('Epoch:', '0004', 'cost =', '0.733232757')
('Epoch:', '0005', 'cost =', '0.669279898')
('Epoch:', '0006', 'cost =', '0.624611847')
('Epoch:', '0007', 'cost =', '0.591160363')
('Epoch:', '0008', 'cost =', '0.563869000')
('Epoch:', '0009', 'cost =', '0.541745187')
('Epoch:', '0010', 'cost =', '0.522673601')
('Epoch:', '0011', 'cost =', '0.506782345')
('Epoch:', '0012', 'cost =', '0.492447660')
('Epoch:', '0013', 'cost =', '0.479955851')
('Epoch:', '0014', 'cost =', '0.468893684')
('Epoch:', '0015', 'cost =', '0.458703497')
Learning finished
('Accuracy: ', 0.8951)
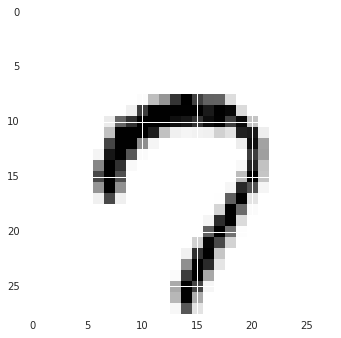
('Label: ', array([7]))
('Prediction: ', array([7]))
결과 이미지
Tips
머신러닝 중에 주의해주어야할 부분들이 다음과 같이 있습니다.
Trainig & Test datasets
전체 데이터가 10이 있다면 7은 학습에 사용하고, 3은 학습이 끝나고 테스트에 사용합니다.
학습에 사용한 데이터는 테스트때 사용하지 않습니다.
Learning Rate
cost 함수에서 변화하는 정도라고 생각하면 됩니다 (=기울기의 크기)
- learning rate가 너무 크면
- 결과 : Overshooting
- 증상 : NaN이 나온다
- learning rate가 너무 작으면
- 결과 : 학습이 더디고, Local Minimum에 걸려서 제대로 된 최소값을 구하지 못하게 됩니다.
- 증상 : Cost 변화값이 너무 적게 변화한다.
Non-normalization
주어진 데이터들 중에 너무 큰 값들이 중간 중간 들어 있으면, InF나 NaN 에러들이 발생합니다.
이를 해결해주기 위해서 input data를 Normalized를 해줍니다.
xy = MinMaxScaler(xy)
print(xy)