이번 5월부터 Google Cloud Professional Data Engineer을 취득하기 위해 준비하면서 공부하는 내용들을 틈틈히 포스팅 해보려고 합니다.
이전에도 Dataflow를 포스팅한 적이 있는데, 그 당시에는 1.x 버전 이었고, 현재는
2.x 버전이 나와서 최신 버전인 2.x버전을 가지고 포스팅하도록 하겠습니다.
Dataflow가 크게 지원하는 언어가 Java, Python 두 가지라 두 버전으로 동일한 내용에
대해서 포스팅을 해보려고 합니다. 이번 포스팅은 Java 버전으로 진행해보겠습니다.
좀 더 자세한 내용을 알고 싶으면 Apache Beam Programming Guide를 참고하세요
Cloud Dataflow란?

Cloud Dataflow는 스트리밍 및 배치 처리를 지원하는 오토 스케일링 데이터 파이프라인 서비스입니다.
오픈소스인 Apache Beam과 동일한 솔루션으로 데이터의 변경을 각각의 파이프로 만들어서 변화를 줄 수 있고
사용량에 따라서 자동으로 Auto Scailing을 지원합니다
서버리스 서비스이기 때문에 서버유지에 대한 리소스를 줄일 수 있는 장점이 있습니다.
그 이외에도 GCP 서비스들 (ex - BigQuery, GCS, PubSub, BigTable 등) 과 손쉬운 연동을 지원합니다.
Support Language
Bounded data vs Unbounded data
- Bounded data : 데이터가 저장되고 더 이상 증가나 변경이 없이 유지되는 데이터
- ex) 1월 정산 데이터
- Unbounded data : 데이터의 수가 정해져있지 않고 계속해서 추가되는 데이터 (=스트리밍 데이터)
- ex) SNS 타임피드, 증권 거래, 로그…
Maven에 Dataflow 적용하기 (pom.xml)
SDK는 크게 Google Dataflow SDK, Apache Beam SDK 두 가지가 있습니다.
Google Dataflow SDK
<dependencies>
<dependency>
<groupId>com.google.cloud.dataflow</groupId>
<artifactId>google-cloud-dataflow-java-sdk-all</artifactId>
<version>[2.4.0, 2.99)</version>
</dependency>
</dependencies>
Apache Beam SDK 버전
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.4.0</version>
<scope>runtime</scope>
</dependency>
</dependencies>
Dataflow Contents

- Pipeline : 데이터 처리를 위한 큰 흐름
- Pipeline I/O : 데이터의 Input과 Output을 위한 부분
- Transforms : 데이터의 변환 및 가공, 변경한 데이터는 PCollection에 저장
- PCollection : 처리된 데이터 저장을 위한 데이터 타입
Dataflow의 흐름
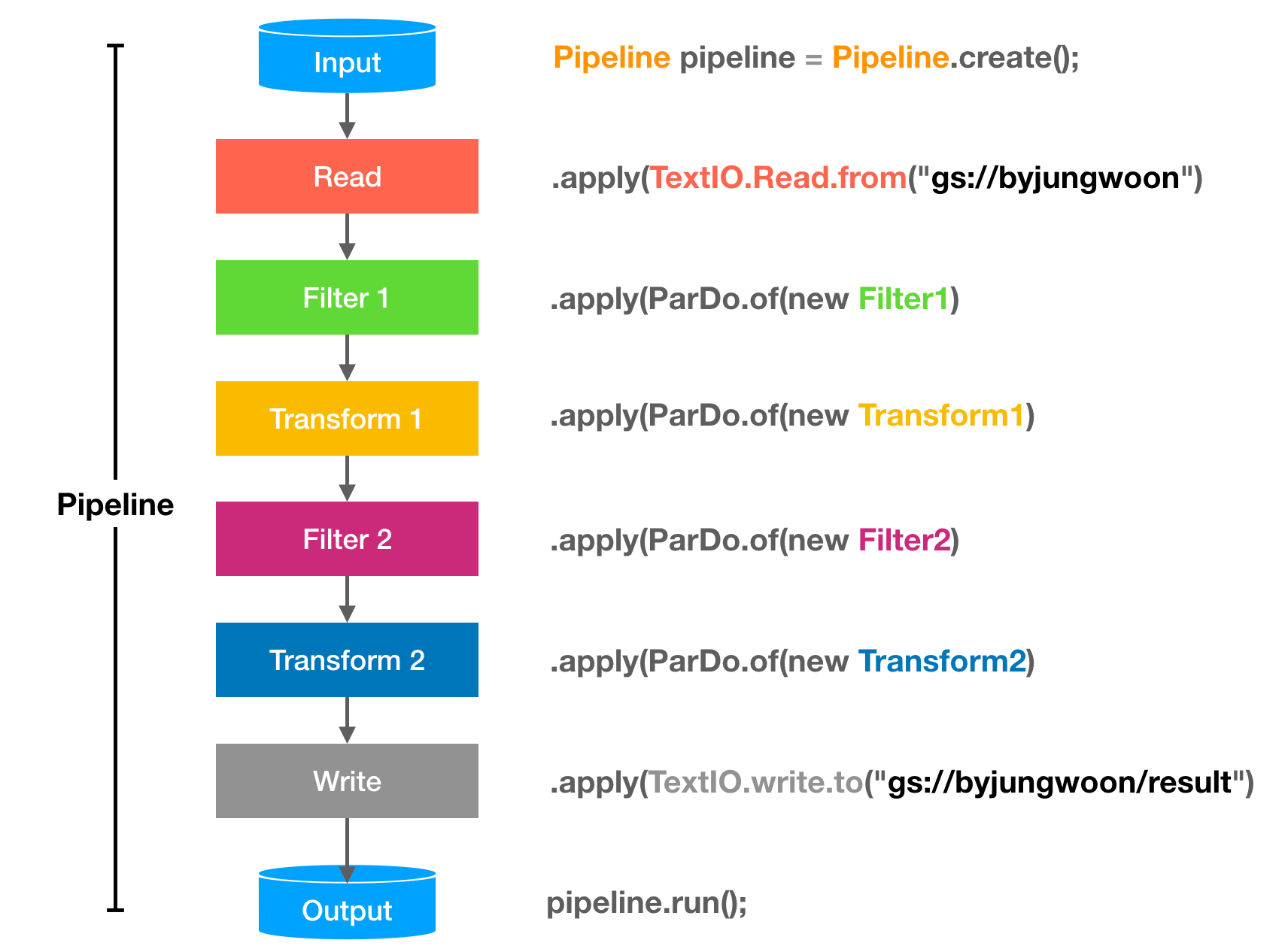
Pipeline생성Pipeline I/O를 이용하여 데이터 읽기Transform을 통해서 데이터 가공 후PCollection으로 만들기 * nPipeline I/O를 이용하여 데이터 결과 저장 위치 지정Pipeline실행
Pipeline
파이프 라인은 처음부터 끝까지 전체 데이터 처리 작업을 캡슐화합니다. 여기에는 입력 데이터 읽기, 해당 데이터 변환 및 출력 데이터 쓰기가 포함됩니다. 모든 dataflow 프로그램은 파이프 라인을 생성해야합니다. 파이프 라인을 생성 할 때 파이프 라인에 실행할 위치와 방법을 알려주는 실행 옵션도 지정해야합니다.
파이프 라인 옵션에 관한 자세한 설명은 Pipeline Options를 참고해보세요
PipelineOptions로 처리하는 방법
final String MY_PROJECT = "by-jungwoon"; // 본인의 GCP 프로젝트 ID를 입력
final String MY_GCS_FOR_STAGING = "gs://by-jungwoon"; // 본인의 GCS 버킷 주소를 입력
// Google Dataflow 관련 내 정보를 가진 옵션을 생성
DataflowPipelineOptions options = PipelineOptionsFactory.as(DataflowPipelineOptions.class);
options.setProject(MY_PROJECT);
options.setStagingLocation(MY_GCS_FOR_STAGING);
options.setRunner(DataflowRunner.class);
// 위의 옵션으로 파이프라인 생성
Pipeline pipeline = Pipeline.create(options);
실행시 option에 대한 정보를 넣어주지 않아도 된다
$ mvn compile exec:java \
-Dexec.mainClass=com.byjw.dataflow.WordCount
Argument로 Option을 받아서 처리하는 방법
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().create();
Pipeline pipeline = Pipeline.create(options);
}
대신에 실행시 option에 대한 정보를 넣어줘야 한다
.withValidation을 추가하면 필수 명령 인자를 확인하게 됩니다.
$ mvn compile exec:java \
-Dexec.mainClass=com.byjw.dataflow.WordCount \
-Dexec.args="--project=by-jungwoon \
--stagingLocation=gs://dataflow-byjw/staging/ \
--runner=DataflowPipelineRunner"
Pipeline I/O
다양한 외부 스토리지 시스템에 데이터를 읽거나 쓰는 라이브러리가 있습니다.
지원하는 언어에 따라 지원하는 라이브러리가 다르므로 아래 내용을 참고해야 합니다.
자세한 내용은 Built-in I/O Transforms를 참고하세요
Java- File-Based
- File IO
- AvroIO
- TextIO
- TFRecordIO
- XmlIO
- TikaIO
- ParquetIO
- Messaging
- Amazon Kinesis
- AMQP
- Apache Kafka
- Google Cloud Pub/Sub
- JMS
- MQTT
- Database
- Apache Cassandra
- Apache Hadoop Input Format
- Apache HBase
- Apache Hive
- Apache Solr
- Elasticsearch(v2.x and v5.x)
- Google BigQuery
- Google Cloud Bigtable
- Google Cloud Datastore
- Google Cloud Spanner
- JDBC
- Mongo DB
- Redis
- File-Based
Python- File-Based
- avroio
- textio
- tfrecordio
- vcfio
- Messaging
- Google Cloud Pub/Sub
- Database
- Google BigQuery
- Google Cloud Datastore
- File-Based
Pipeline I/O 사용 예제
inputData.txt로부터의 내용을 읽어서 PCollection에 저장하는 부분
PCollection<String> lines = pipeline.apply(
"ReadMyFile", TextIO.read().from("protocol://path/to/some/inputData.txt"));
PCollection
PCollection은 Dataflow pipeline이 작동하는 분산 데이터 세트를 나타냅니다. 일반적으로 파이프 라인은 외부 데이터 원본에서 데이터를 읽음으로써 초기 PCollection을 생성하지만 드라이버 프로그램 내의 메모리 내 데이터에서 PCollection을 만들 수도 있습니다. 거기에서 PCollections는 파이프 라인의 각 단계에 대한 입력과 출력입니다.
PCollection은 데이터 플로 파이프라인 내에서 데이터를 저장하는 개념으로 한번 생성이 되면 그 데이터는 수정이 불가능하다
데이터를 변경하거나 수정하기 위해서는 PCollection을 새로 생성해야 한다
PCollection<데이터 타입> collection = [PipelineI/O or Transforms로 생성]
Dataflow Runners
- DirectRunner : 로컬에서 돌릴때 사용
- ApexRunner : Apache Apex를 돌릴때 사용
- Flink Runner : Apache Flink를 돌릴때 사용
- Spark Runner : Apache Spark를 돌릴때 사용
- DataflowRunner : Cloud Dataflow 이용시 사용 (Gooogle Cloud Platform이 전체 서비스를 매니징 함)
- GearpumpRunner : Apache Gearpump를 돌릴때 사용
Transforms
PTransform은 파이프 라인에서 데이터 처리 작업 또는 단계를 나타냅니다. 모든 PTransform은 하나 이상의 PCollection 객체를 입력으로 가져와 해당 PCollection의 요소에 제공하는 처리 기능을 수행하고 0 개 이상의 출력 PCollection 객체를 생성합니다.
데이터를 변경할때 사용하는 부분으로 아래 형태를 지원합니다.
ParDoGroupByKeyCoGroupByKeyCombineFlattenPartition
기본 형태
하나의 PCollection 데이터를 하나의 Transform으로 변경하는 경우
[Output PCollection] = [Input PCollection].apply([Transform])
하나의 PCollection 데이터를 서로 다른 Transform을 이용하여 두개의 서로 다른 Transform으로 변경하는 경우
[Output PCollection 1] = [Input PCollection].apply([Transform 1])
[Output PCollection 2] = [Input PCollection].apply([Transform 2])
ParDo
ParDo는 Parallel(병렬처리)를 지원하는 기능으로 아래와 같이 사용합니다.
ParDo 안에 DoFn을 담는 형태입니다
Pipeline pipeline = Pipeline.create(options);
pipeline.apply("Transform 이름", ParDo.of(
new DoFn<입력 데이타 타입 , 출력 데이타 타입>() {
@ProcessElement
public void processElement(ProcessContext processContext) {
String result = processContext.element(); // 입력 데이터 타입으로 정의된 입력 데이터를 꺼냄
... // 여기서 데이터들의 처리를 합니다.
processContext.output(result); // 파이프 라인상의 다음 컴포넌트로 데이터 전달
}
}
))
중요한 메서드
processContext.element() : 위에 흐름에서 전달받은 데이터를 가져옴
processContext.output(result) : 처리한 result를 다음 흐름으로 전달
만약 Key-Value 형태의 PCollection이면 아래와 같이 받을 수도 있습니다.
processContext.element().getKey() : 위에 흐름에서 전달받은 데이터의 Key를 가져옴
processContext.element().getValue() : 위에 흐름에서 전달받은 데이터의 Value를 가져옴
DoFn 클래스
위에서는 ParDo를 생성할때 DoFn도 같이 만드는 형태이고 아래와 같이 미리 DoFn으로부터 상속받은
클래스를 만들어서 사용할 수 있습니다.
DoFn안에 실제 데이터 처리 로직이 들어가게 됩니다
class MyFunction extends DoFn<{입력 데이타 타입},{출력 데이타 타입}> {
@ProcessElement
public void processElement(ProcessContext processContext) {
String result = processContext.element() // 입력 데이터 타입으로 정의된 입력 데이터를 꺼냄
... // 여기서 데이터들의 처리를 합니다.
processContext.output(result); // 파이프 라인상의 다음 컴포넌트로 데이터 전달
}
}
// 여기서 MyFunction은 위에서 만들어놓은 DoFn(=MyFunction()) 입니다.
pipeline.apply("toUpper", ParDo.of(new MyFunction());
MapElements
PCollection의 요소에 간단한 함수를 매핑하기위한 PT 변환입니다.
public static void main(String[] args) {
// Google Dataflow 관련 내 정보를 가진 옵션을 생성
DataflowPipelineOptions options = PipelineOptionsFactory.as(DataflowPipelineOptions.class);
options.setProject("by-jungwoon");
options.getGcpTempLocation();
options.setRunner(DataflowRunner.class);
// 위의 옵션으로 파이프라인 생성
Pipeline pipeline = Pipeline.create(options);
pipeline.apply(TextIO.read().from("gs://apache-beam-samples/shakespeare/kinglear.txt")) // 데이터 읽어옴
.apply("Test", MapElements // 새로운 PTransform
.into(TypeDescriptors.strings()) // Output Type을 지정
.via((String word) -> word.toUpperCase())) // Input / Output Type을 지정, 대문자로 바꾼 결과
.apply(TextIO.write().to("gs://by-jungwoon/hello.txt")); // 변경된 결과를 GCS에 저장
pipeline.run().waitUntilFinish();
}
FlatMapElements
PCollection 요소에 iterable을 반환하고 결과를 병합하는 간단한 함수를 매핑하기위한 PTransform 입니다.
apply("ExtractWords", FlatMapElements
.into(TypeDescriptors.strings())
.via((String word) -> Arrays.asList(word.split("[^\\p{L}]+"))))
GroupByKey
Key를 가지고 Grouping을 해주는 기능입니다.
cat, 1
dog, 5
and, 1
jump, 3
tree, 2
cat, 5
dog, 2
and, 2
cat, 9
and, 6
...
GroupByKey를 사용하면 아래와 같이 가능합니다.
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
...
아래와 같이 사용할 수 있습니다.
List<KV<String, Integer>> wordAndNumber = Arrays.asList(
KV.of("cat", 1),
KV.of("dog", 5),
KV.of("and", 1),
KV.of("jump", 3),
KV.of("tree", 2),
KV.of("cat", 5),
KV.of("dog", 2),
KV.of("and", 2),
KV.of("cat", 9),
KV.of("and", 6)
);
PCollection<KV<String, Integer>> objects = pipeline.apply("CreateObjects", Create.of(wordAndNumber));
PCollection<KV<String, Iterable<Integer>>> groupedWords = objects.apply(GroupByKey.create());
CoGroupByKey
서로 다른 Key-Value를 하나로 조인할때 사용 (Key를 기준으로)
// Key-Value 리스트1
final List<KV<String, String>> emailsList = Arrays.asList(
KV.of("amy", "amy@example.com"),
KV.of("carl", "carl@example.com"),
KV.of("julia", "julia@example.com"),
KV.of("carl", "carl@email.com"));
// Key-Value 리스트2
final List<KV<String, String>> phonesList = Arrays.asList(
KV.of("amy", "111-222-3333"),
KV.of("james", "222-333-4444"),
KV.of("amy", "333-444-5555"),
KV.of("carl", "444-555-6666"));
// 각각 PColection으로 형변환
PCollection<KV<String, String>> emails = p.apply("CreateEmails", Create.of(emailsList));
PCollection<KV<String, String>> phones = p.apply("CreatePhones", Create.of(phonesList));
// 각 리스트별로 Tag를 달아줌
final TupleTag<String> emailsTag = new TupleTag<>();
final TupleTag<String> phonesTag = new TupleTag<>();
// 실제 연산
PCollection<KV<String, CoGbkResult>> results =
KeyedPCollectionTuple
.of(emailsTag, emails)
.and(phonesTag, phones)
.apply(CoGroupByKey.create());
PCollection<String> contactLines = results.apply(ParDo.of(
new DoFn<KV<String, CoGbkResult>, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
KV<String, CoGbkResult> e = c.element();
String name = e.getKey();
Iterable<String> emailsIter = e.getValue().getAll(emailsTag);
Iterable<String> phonesIter = e.getValue().getAll(phonesTag);
String formattedResult = Snippets.formatCoGbkResults(name, emailsIter, phonesIter);
c.output(formattedResult);
}
}
));
결과
"amy; ['amy@example.com']; ['111-222-3333', '333-444-5555']"
"carl; ['carl@email.com', 'carl@example.com']; ['444-555-6666']"
"james; []; ['222-333-4444']"
"julia; ['julia@example.com']; []
Combine
데이터에서 여러 요소들을 결합할때 사용합니다. 기본적으로 Sum, Min, Max 등은 제공하며,
복잡한 함수는 CombineFn을 이용하여 서브 클래스를 작성해야 합니다.
// Sum.SumIntegerFn() combines the elements in the input PCollection. The resulting PCollection, called sum,
// contains one value: the sum of all the elements in the input PCollection.
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(
Combine.globally(new Sum.SumIntegerFn()));
public class AverageFn extends CombineFn<Integer, AverageFn.Accum, Double> {
public static class Accum {
int sum = 0;
int count = 0;
}
@Override
public Accum createAccumulator() { return new Accum(); }
@Override
public Accum addInput(Accum accum, Integer input) {
accum.sum += input;
accum.count++;
return accum;
}
@Override
public Accum mergeAccumulators(Iterable<Accum> accums) {
Accum merged = createAccumulator();
for (Accum accum : accums) {
merged.sum += accum.sum;
merged.count += accum.count;
}
return merged;
}
@Override
public Double extractOutput(Accum accum) {
return ((double) accum.sum) / accum.count;
}
}
Flatten
여러개의 PCollection을 하나의 PCollection으로 병합합니다.
// Flatten takes a PCollectionList of PCollection objects of a given type.// Fla
// Returns a single PCollection that contains all of the elements in the PCollection objects in that list.
PCollection<String> pc1 = ...;
PCollection<String> pc2 = ...;
PCollection<String> pc3 = ...;
PCollectionList<String> collections = PCollectionList.of(pc1).and(pc2).and(pc3);
PCollection<String> merged = collections.apply(Flatten.<String>pCollections());
Partition
PCollection을 고정 된 수의 작은 PCollection으로 분할 합니다.
PCollection<Student> students = ...;
PCollectionList<Student> studentsByPercentile =
students.apply(Partition.of(10, new PartitionFn<Student>() {
public int partitionFor(Student student, int numPartitions) {
return student.getPercentile() // 0..99
* numPartitions / 100;
}}));
// You can extract each partition from the PCollectionList using the get method, as follows:
PCollection<Student> fortiethPercentile = studentsByPercentile.get(4);
Windowing
Unbounded Data(=Streaming Data)같은 경우에는 데이터가 끊이지 않고 들어오기 때문에,
결과를 내보내야 하는 타이밍을 잡기 애매합니다. 이를 위해서 시간을 기준으로 작업을 끊어서 처리
하는데 이를 Windowing이라고 합니다.
- Windowing : 일정 시간 간격으로 처리하는 방법
- Fixed Time Window : 정확하기 일정 시간 단위로 시간 윈도우를 쪼개는 개념
- Sliding Time Window : 현재시간으로부터 +- N 시간의 데이터를 특정 시간마다 추출하는 방식
- Session Windows : 사용자가 일정 기간동안 데이터를 보내고 일정시간 동안 데이터 없는 동안을 윈도우로 묶는 개념
- Single Global Window :
- Calendar-based Windows :
Fixed Time Windows
고정된 시간을 가지고 처리하는 경우 아래 이미지에서는 30s가 윈도우 길이가 됩니다
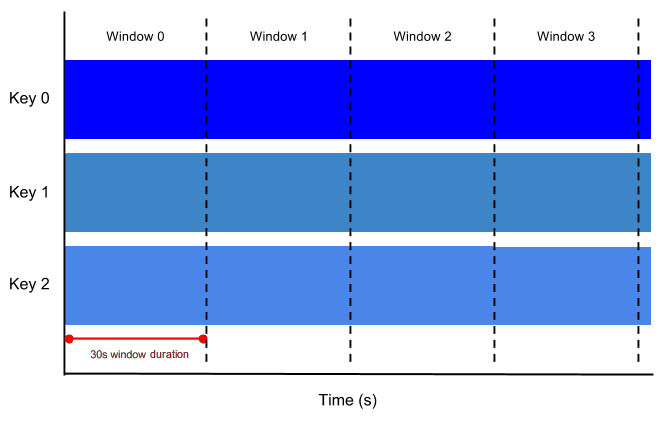
PCollection<String> items = ...;
PCollection<String> fixedWindowedItems = items.apply(
Window.<String>into(FixedWindows
.of(Duration.standardSeconds(30))));
Sliding Time Windows
다른 윈도우와 중첩되는 윈도우를 슬라이딩 윈도우라고 합니다.
아래 이미지에서는 다음과 같습니다.
- 윈도우 길이 : 60s (한 윈도우의 길이)
- 윈도우 간격 : 30s (새로운 윈도우가 생기는 시간 간격)
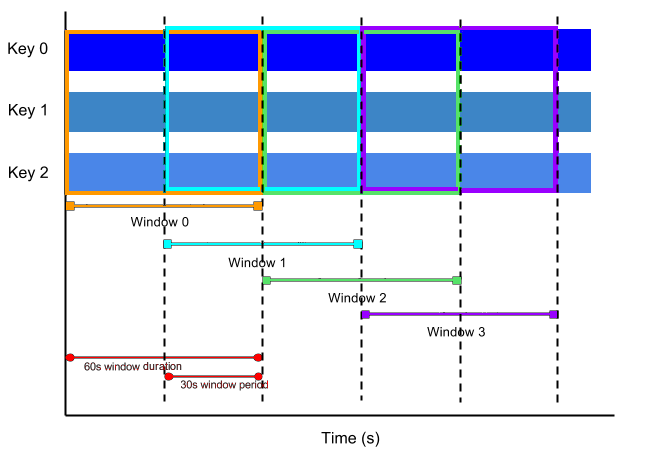
PCollection<String> items = ...;
PCollection<String> slidingWindowedItems = items.apply(
Window.<String>into(SlidingWindows
.of(Duration.standardSeconds(60)) // 윈도우 길이 60초
.every(Duration.standardSeconds(30)))); // 윈도우 간격 30초
Session Windows
세션은 사용자가 시스템을 사용한 후 사용이 끝날때까지의 기간을 정의 하며, 시간에 따라 불규칙하게 분산 된 데이터 처리에 유용합니다.
Duration Gap Time을 지정해놓고 지정해놓은 Time만큼 사용이 없으면 Session이 끊어지며,
Window가 분리가 됩니다.
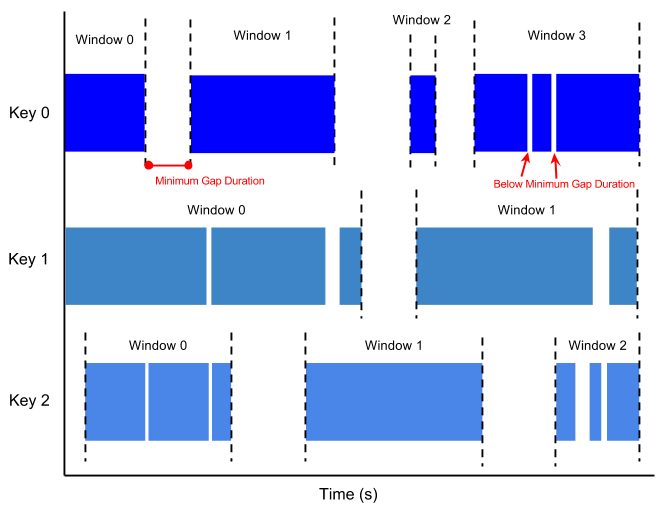
아래 코드는 세션 타임 갭을 10분으로 한 코드 입니다.
PCollection<String> items = ...;
PCollection<String> sessionWindowedItems = items.apply(
Window.<String>into(Sessions.withGapDuration(Duration.standardMinutes(10))));
지연데이터와 Water Mark
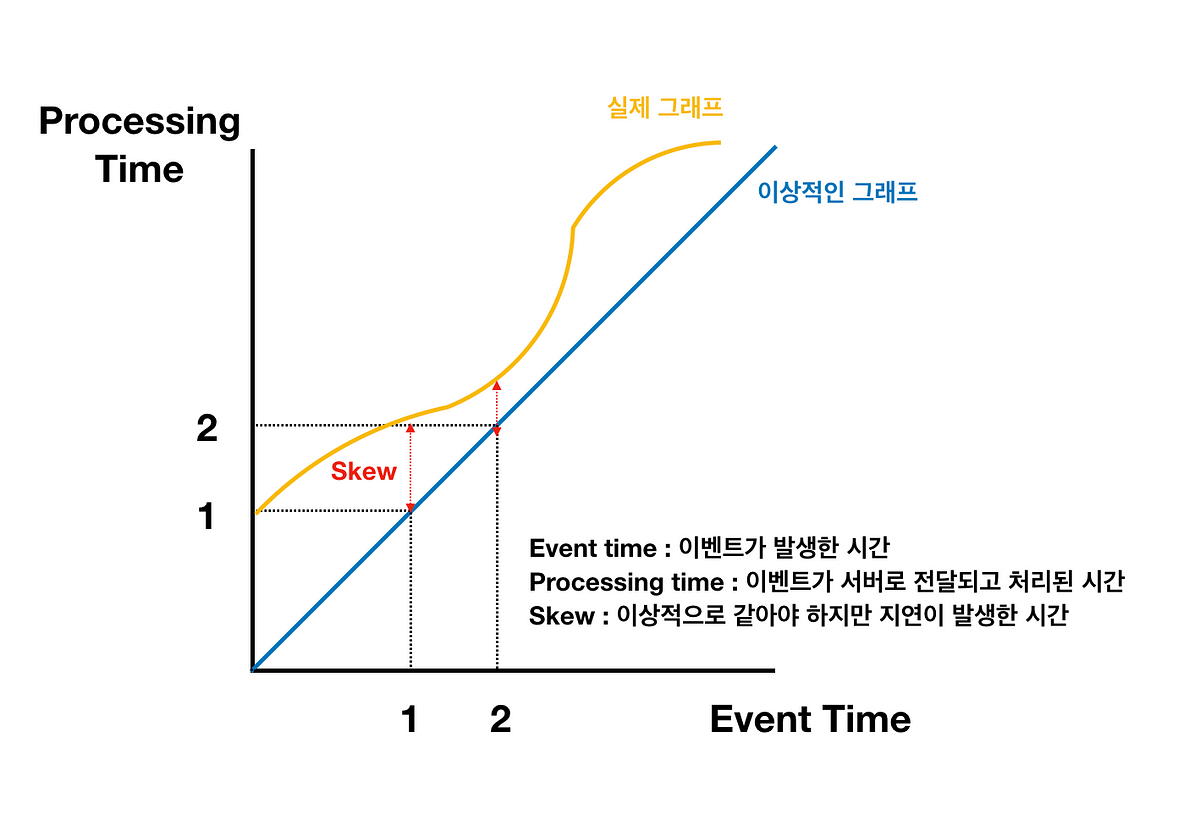
실제 데이터들이 발생한 시간과 서버에 도착하는 시간에는 차이가 발생할 수 있기 때문에, 어느 시점까지 데이터를 기다렸다가 처리해야 하는지에 대한 고민이 생길 수 있습니다.
이럴때 실제 데이터가 시스템에 도착하는 시간을 예측해야 하는데 이를 Water Mark라고 합니다.
Water Mark를 기반으로 윈도우의 시스템상의 시작 시간과 종료 시간을 예측하게 됩니다.
위의 노란색 그래프를 Water Mark라고 봐도 됩니다
지연된 데이터들의 처리를 위해서 윈도우 생성시 withAllowedLateness라는 옵션을 이용하면
늦게 도착하는 데이터에 대한 처리 기간을 정의할 수 있습니다
PCollection<String> items = ...;
PCollection<String> fixedWindowedItems = items.apply(
Window.<String>into(FixedWindows.of(Duration.standardMinutes(1)))
.withAllowedLateness(Duration.standardDays(2)));
Trigger
Trigger는 처리중인 데이터를 언제 다음 단계로 넘길지를 결정하는 개념입니다.
만약 윈도우가 1시간이라면 실제 결과를 1시간 뒤에나 볼 수 있는데, 이 경우에는 실시간 데이터 분석이라고 보기 애매한 상황이 발생합니다.
대신 윈도우가 끝나기 전에 중간 계산한 값들을 보여줄 수 있는데, 이때
이용하는것이 Trigger 입니다
- Trigger 종류
- Time triggers : 특정 이벤트 시간에 작동합니다 (예 - 1분 단위, 윈도우 시작 후 1번, 윈도우 종료 후 1번 등)
- Element count triggers : 데이터의 개수를 기반으로 작동합니다(예 - 데이터 100개마다)
- Punctuations triggers : 특정 데이터가 들어오는 순간에 트리거링 하는 방법 (예 - flag에 a 가 들어올때)
- Composite triggers : 여러가지 triggers를 합한 형태
- Trigger 조합
- AND : 2개 이상의 트리거 조건이 만족해야 트리거링이 되는 형태
- ex) Time trigger가 1분 / Element trigger가 10개이면 1분 후 데이터 개수가 10개면 트리거링
- OR : 여러 조건중에 하나만 만족해도 트리거링 되는 형태
- ex) Time trigger가 1분 / Element trigger가 10개이면 1분이 되거나 데이터 개수가 10개면 트리거링
- Repeat : 특정 반복 개수마다 트리거링 하는 경우
- ex) 반복 개수가 10개 이면 10개마다 트리거링
- Sequence : 조건이 만족하면 순차적으로 트리거링 되는 형태
- ex) Time trigger가 1분, Element trigger가 10개 이렇게 순차적으로 등록이 되어 있으면 1분 후 트리거링이 먼저 되고 그 뒤에 데이터가 10개가 들어오면 트리거링 되고 종료가 됩니다.
- AND : 2개 이상의 트리거 조건이 만족해야 트리거링이 되는 형태
Trigger 누적
트리거링이 될때마다 전달 되는 데이터는 과연 이전 데이터를 처리할까? 처리하지 않을까? 라는 의문이 있을 수 있습니다.
Accumulating mode란 옵션을 이용하여 누적할건지 안할 건지 선택할 수 있습니다.
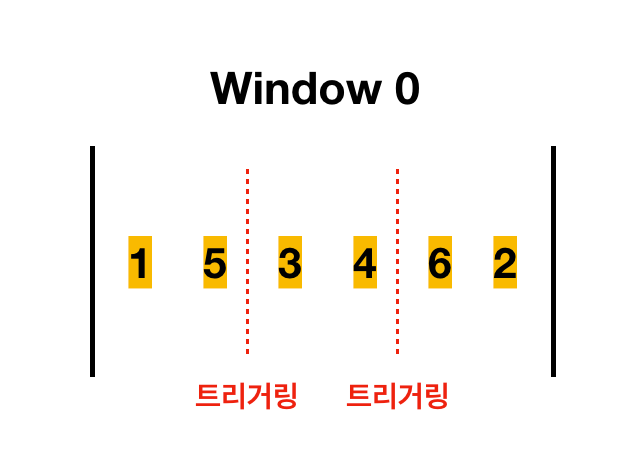
위의 그림에서의 차이
- Accumulating mode : True
- 첫번째 트리거링 : 1, 5
- 두번째 트리거링 : 1, 5, 3, 4
- 세번째 트리거링 : 1, 5, 3, 5, 6, 2
- Accumulating mode : False
- 첫번째 트리거링 : 1, 5
- 두번째 트리거링 : 3, 4
- 세번째 트리거링 : 6, 2