이번 5월부터 Google Cloud Professional Data Engineer을 취득하기 위해 준비하면서 공부하는 내용들을 틈틈히 포스팅 해보려고 합니다.
오늘 포스팅할 내용은 BigQuery에 대한 간단한 소개를 하려고 합니다.
BigQuery는 Data Wareouse로 사용에 적합하며, 여러곳에서 모은 데이터를 한곳에 모을때 사용하면 좋습니다.
BigQuery의 특징은 다음과 같습니다.
빅쿼리 특징
- 페타 바이트 데이터베이스의 분석이 가능
- SQL 2011 지원
- 데이터를 import/ export / transform을 할 수 있는 다양한 방법 지원
- 자바스크립트로 UDF 설정 가능
- 데이터 스토리지 저렴
- 사용한 만큼 지불
Bigquery의 구조
빅쿼리는 다른 데이터베이스와 같은 관계형 데이터베이스가 아니라 컬럼기반의 데이터 베이스입니다.
기본적으로 관계형 데이터베이스는 아래와 같이 데이터가 저장이 되는데,
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
빅쿼리는 컬럼기반의 데이터 베이스라 실제로는 아래와 같이 저장이 됩니다.
파일1 : 001:A001, 002:A002, 003:A003 파일2 : 001:PEN, 002:CANDY, 003:BOOK 파일3 : 001:3, 002:1, 003:8
그리고 내부적으로 다음과 같은 계층 구조를 가지고 있습니다.
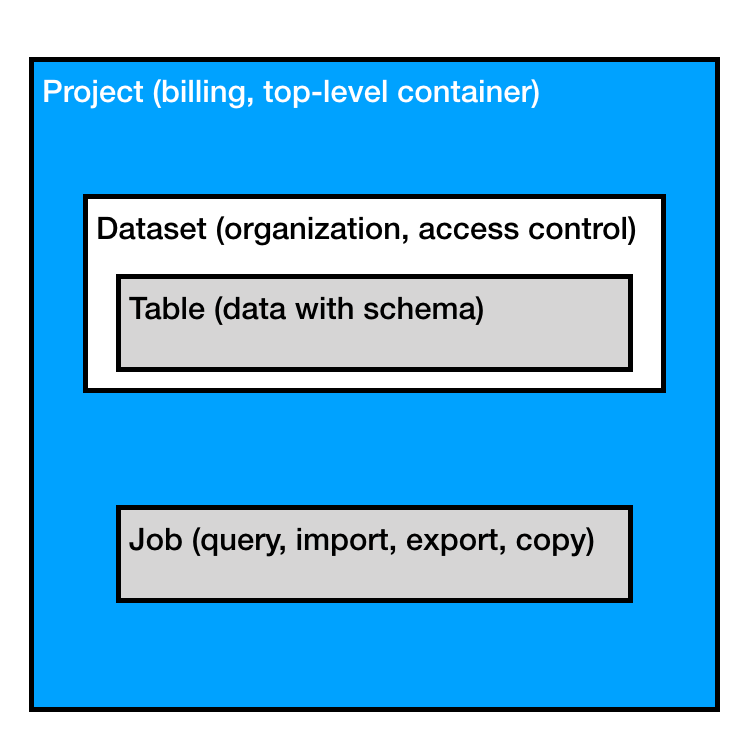
- Project : 여러 데이터셋을 담을 수 있는 최상위 개념
- Dataset : 테이블이 모여있는 데이터베이스같은 역할
- Table : 데이터베이스의 테이블과 같은 개념으로 실제 데이터를 담는 부분
- Job : 명령에 대한 부분은 이쪽에서 관리를 함
BigQuery의 데이터 안전성
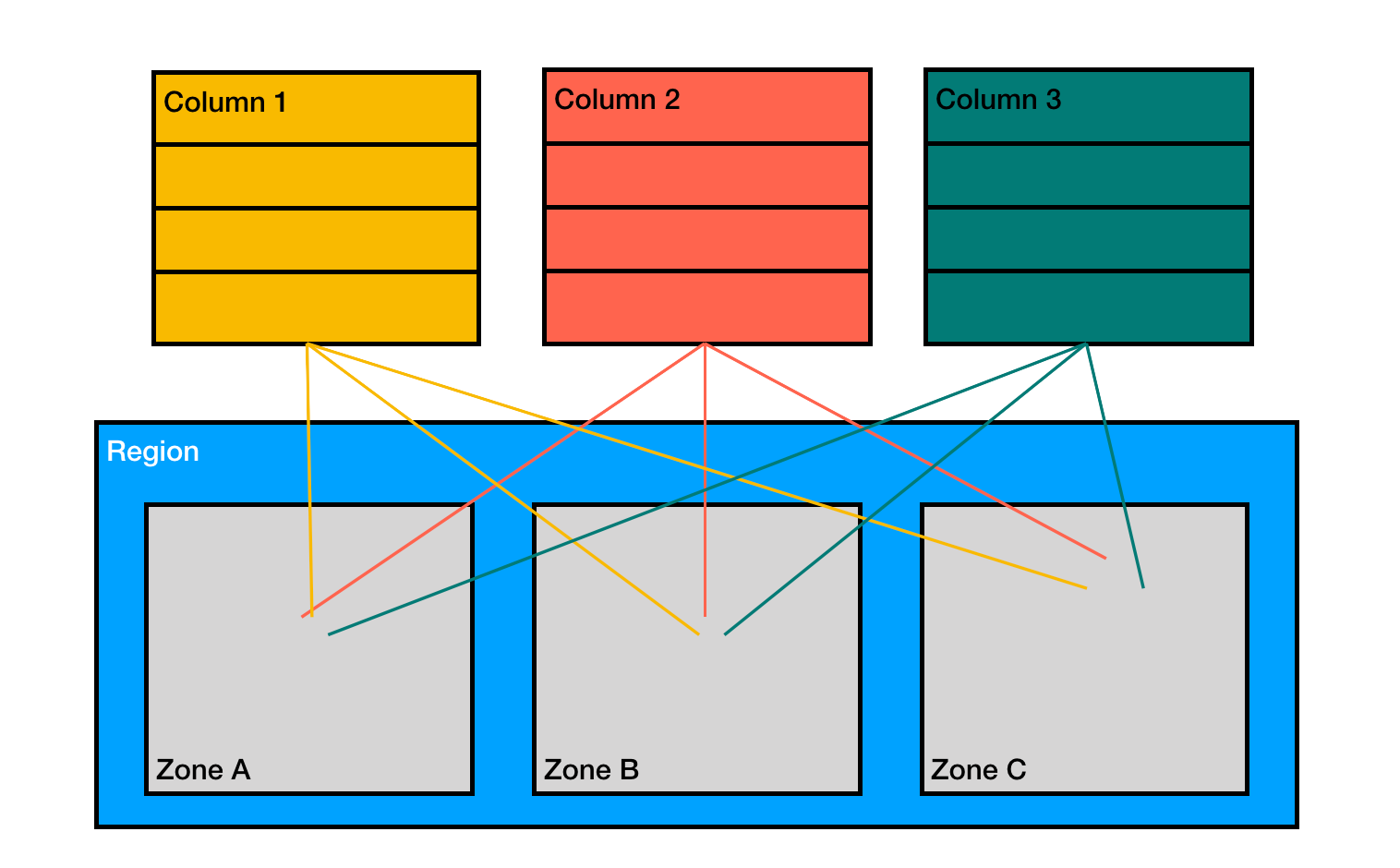
빅쿼리는 데이터의 안정성을 위해서 3개의 데이터센터에 나눠서 데이터를 저장하는데, 위와 같이 각 컬럼을 담은 파일의 복제본이 총 3개씩 만들어져 각 데이터센터에 저장된다.
BigQuery 기본 사용법
Big Query에서 사용하는 문법은 크게 Legacy SQL와 Standard SQL이 있는데,
LegacySQL은 Big Query 초기부터 사용되던 문법이나 2.0 이후에 Standard SQL이 지원되었기 때문에,
여기서는 Standard SQL 기준으로 포스팅하도록 하겠습니다.
(좀더 자세히 알고 싶으신 분들은 구글 문서를 참조하시기 바랍니다)
BigQuery Mate 설치
먼저 추천드리는 Chrome Extension이 있습니다
Chrome으로 BigQuery Mate에 들어가서 설치를 해줍니다
그럼 자동으로 자동완성같은 부분이 지원이 되어서 문법적으로 틀릴일이 많이 줄어들 수 있습니다
기본 구성
BigQuery를 열면 다음과 같은 화면을 볼 수 있습니다
여기서 좌측 상단의 COMPOSE QUERY를 열면 오른쪽에 Query 입력창을 볼 수 있습니다 이제 여기다가, 쿼리를 입력해서 실행을 시키면 됩니다
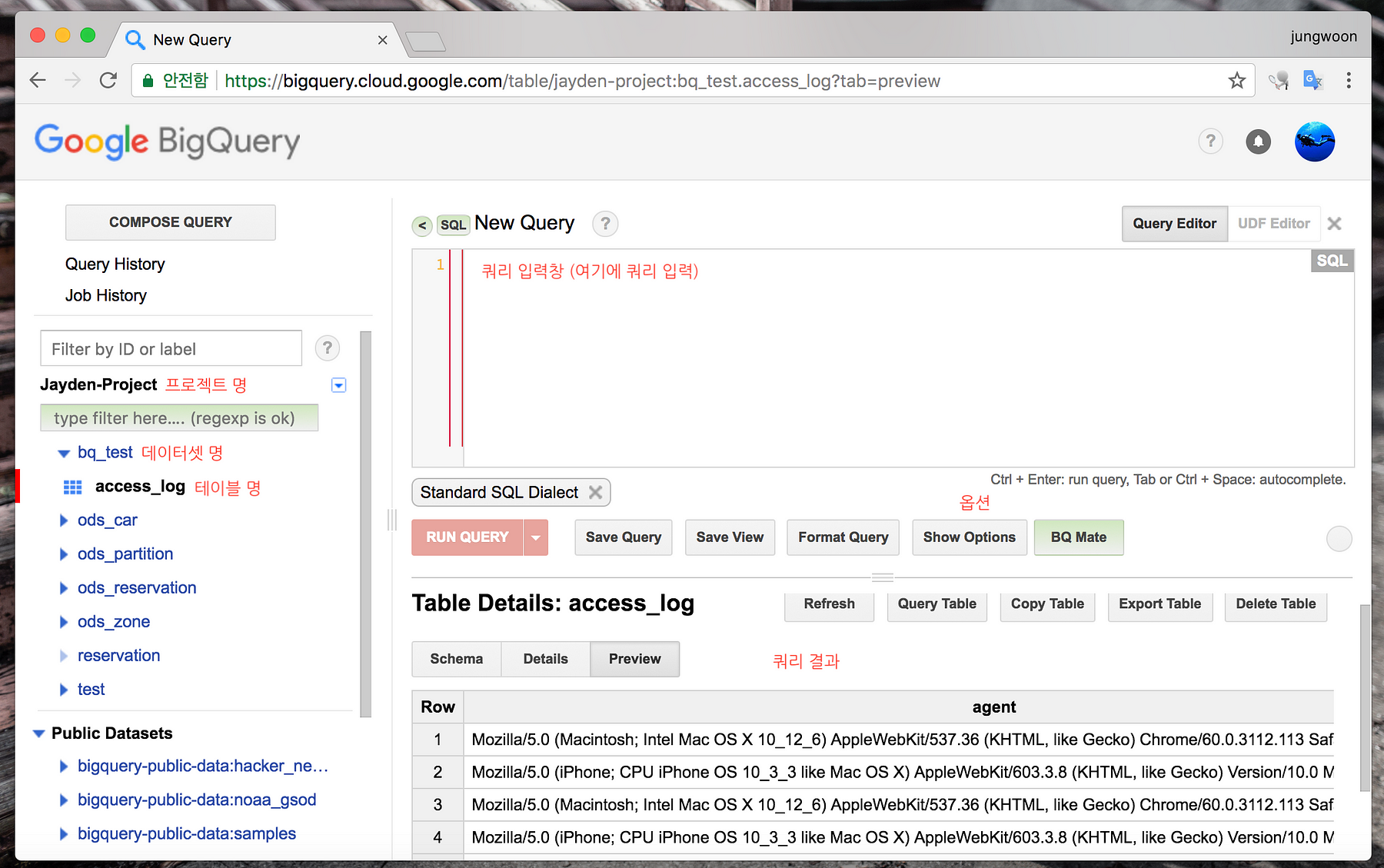
- Project : 데이터를 담는 최상위 개념이며, 하나의 프로젝트에 여러개의 데이터셋이 들어갈 수 있습니다
- Dataset : RDB에서 Database의 개념이며, 하나의 Dataset에 여러개의 테이블이 들어갈 수 있습니다
- Table : RDB의 테이블과 동일한 개념입니다.
- Job : BigQuery에 내리는 모든 명령을 Job이라 합니다
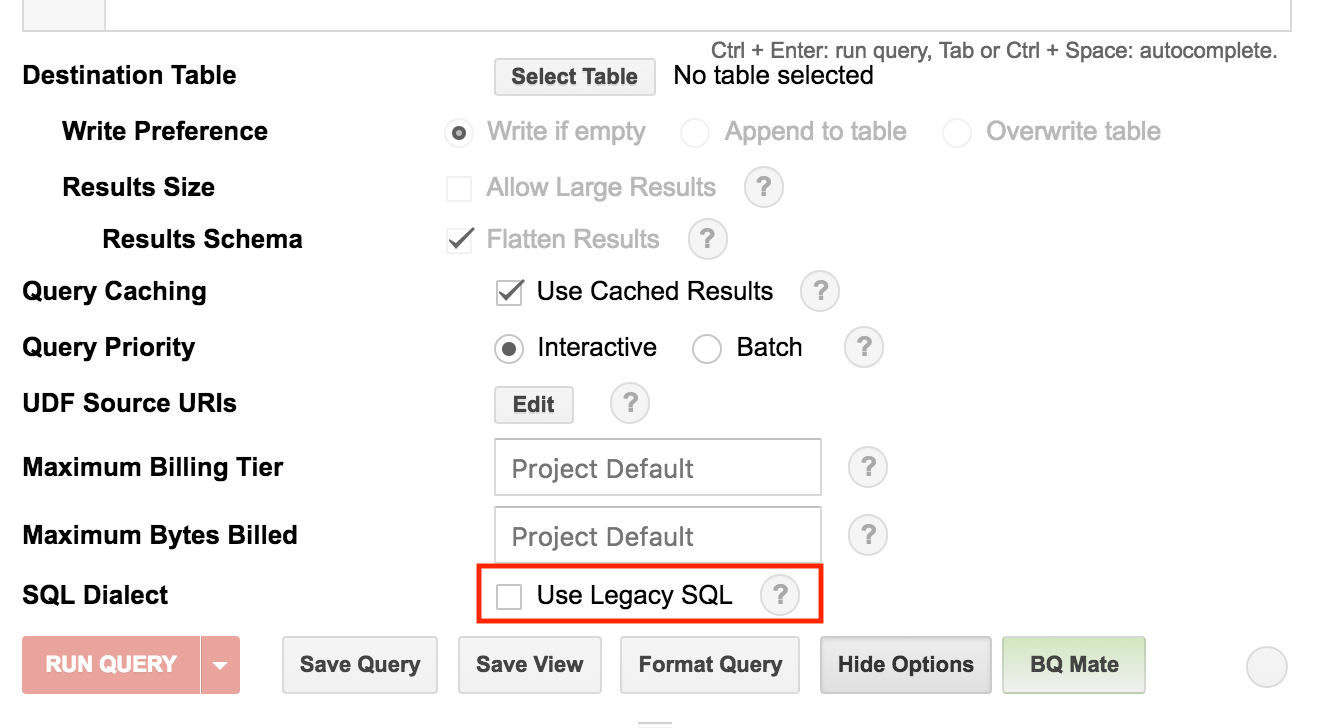
Standard SQL설정 하기
저희는 Standard SQL로 설정을 하기 위해 우측 하단의 Show Options를 클릭하여 옵션을 봅니다
그럼 아래와 같이 화면이 나올텐데, 아래 표시한 Use Legacy SQL의 체크를 해제해주면 Standard SQL을 사용할 수 있게 됩니다
밑에 공간을 차지하니 우측 하단에 Hide Options를 눌러서 옵션 화면을 숨깁니다
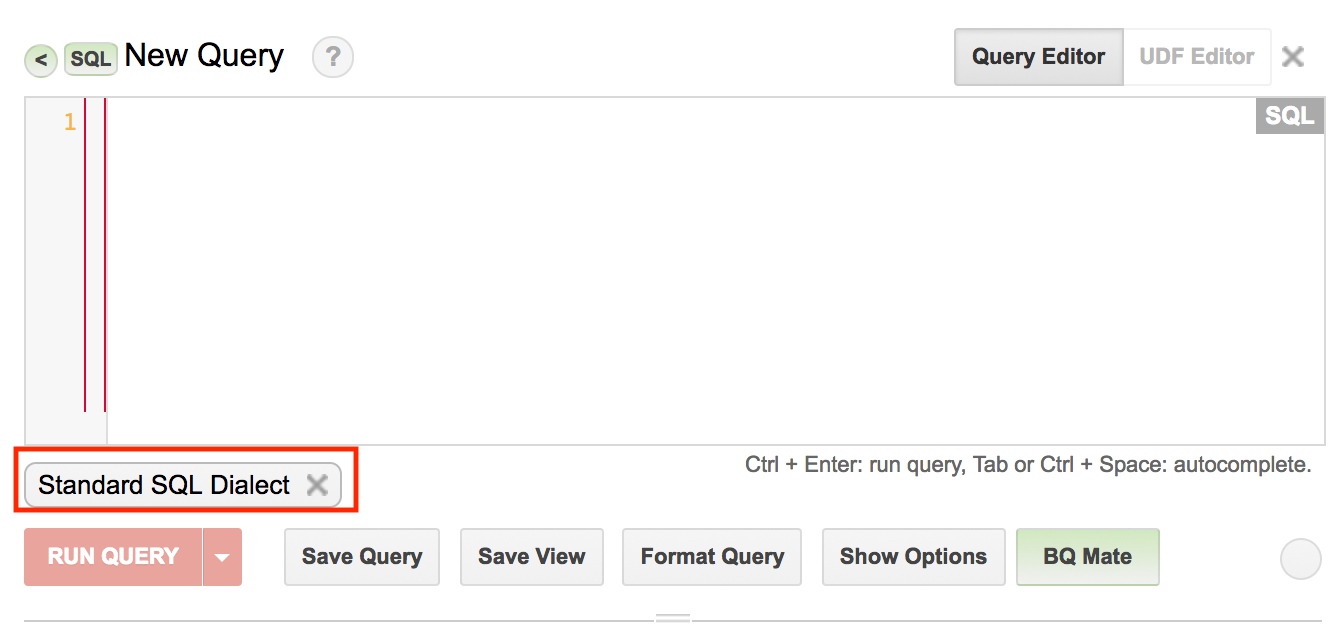
여기까지 잘 따라왔으면 아래에 Standard SQL Dialect 이란 박스가 생긴것을 확인할 수 있습니다, 이제부터 Standard SQL를 사용할 수 있습니다
쿼리를 날릴때의 기본 구성
예제로 대략적인 형태를 보여드리고 설명을 하도록 하겠습니다
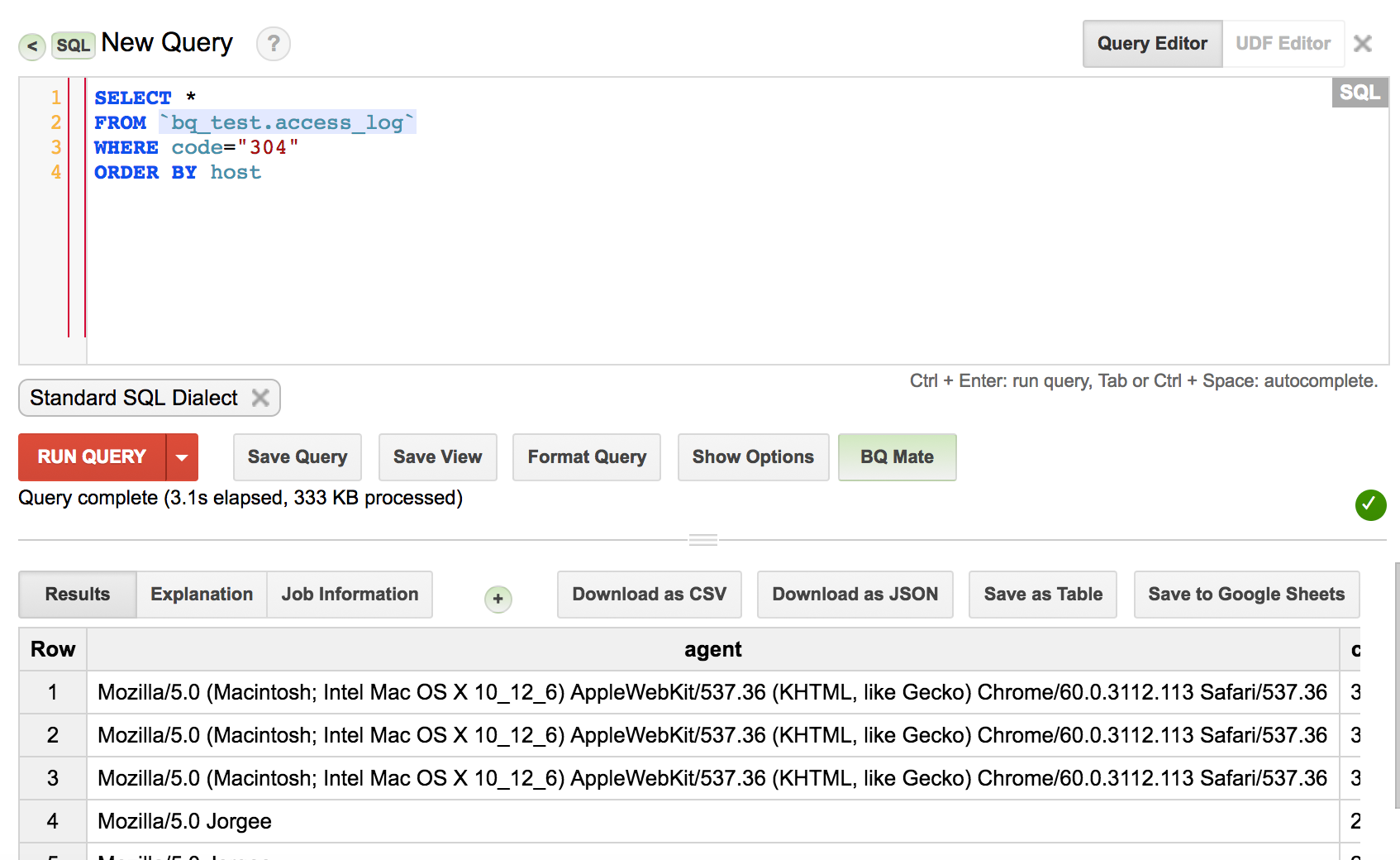
제가 제일 햇갈렸던 부분은 FROM 다음에 `사이에 프로젝트명, 데이터셋 테이블이름이 들어가는 문법이었습니다
아래는 Legacy SQL과 Standard SQL의 문법이 달라서 넣어봤습니다
| Legacy SQL | Standard SQL | |
|---|---|---|
| 문법 | [프로젝트명:데이터셋.테이블명] | `프로젝트명.데이터셋.테이블명` |
| 예시 | [jayden-project:bq_test.access_log] | `jayden-project.bq_test.access_log` |
SELECT *
FROM `프로젝트명.데이터셋.테이블이름` -- 프로젝트명 생략 가능
WHERE 조건
ORDER BY 컬럼
BigQuery에서 지원하는 자료형
| 타입 | 이름 | 설명 |
|---|---|---|
| INTEGER | INT64 | 정수 |
| FLOAT | FLOAT64 | 실수 |
| BOOL | BOOL | 불 대수 |
| STRING | STRING | 문자열 |
| BYTES | BYTES | 바이트 |
| DATE | DATE | 포맷 : YYYY-[M]M-[D]D |
| DATETIME | DATETIME | 포맷 : YYYY-[M]M-[D]D[( T)[H]H:[M]M:[S]S[.DDDDDD]] |
| TIME | TIME | 포맷 : [H]H:[M]M:[S]S[.DDDDDD] |
| TIMESTAMP | TIMESTAMP | 포맷 : YYYY-[M]M-[D]D[( T)[H]H:[M]M:[S]S[.DDDDDD]][time zone] |
| ARRAY | ARRAY | 배열 |
| STRUCT | STRUCT | 포맷 : STRUCT<T> |
기본 문법
여기서는 빅쿼리에서 사용하는 기본 문법에 대해서 한번 살펴보도록 하려고 합니다. 위에서 말했던거처럼 Standard SQL을 기준으로
진행하겠습니다 기본 SQL에서 많이 사용할만한 부분을 하고 추후에 이건 정말 좋다 싶은건 계속 업데이트 해서 진행하도록 하겠습니다
관련해서 좀 더 궁금하신 분들은 Query Syntax에서 좀 더 자세히 확인할 수 있습니다
SELECT
테이블 내용 보기 위한 쿼리
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product`;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
SELECT expression.*
별칭을 주고 *를 붙임으로써 전체 데이터를 확인할 수 있습니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT HELLO.*
FROM `jayden-project.my_dataset.product` AS HELLO;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
SELECT * EXCEPT
전체 데이터에서 특정 컬럼명 제외하고도 산출할 수 있습니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT * EXCET (PRODUCT_ID)
FROM `jayden-project.my_dataset.product`;
Result)
| PRODUCT | PRICE |
|---|---|
| PEN | 3 |
| CANDY | 1 |
| BOOK | 8 |
| CUP | 5 |
| USB | 20 |
SELECT * REPLACE
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT * REPLACE (PRICE * 0.8 AS PRICE)
FROM `jayden-project.my_dataset.product`;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 2.4 |
| A002 | CANDY | 0.8 |
| A003 | BOOK | 6.4 |
| A004 | CUP | 4 |
| A005 | USB | 16 |
Query)
SELECT * REPLACE ("SOLD OUT" AS PRODUCT)
FROM `jayden-project.my_dataset.product`;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | SOLD OUT | 3 |
| A002 | SOLD OUT | 1 |
| A003 | SOLD OUT | 8 |
| A004 | SOLD OUT | 5 |
| A005 | SOLD OUT | 20 |
FROM
어떤 테이블에서 데이터를 가져올건지 명시하기 위한 문법입니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT * FROM `product`;
or
SELECT * FROM `my_dataset.product`;
or
SELECT * FROM `jayden-project.my_dataset.product`;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
WHERE
특정 조건에 해당하는 데이터만 산출할 때 WHERE를 통해 조건을 줄 수 있습니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product, producer
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product`
WHERE PRICE >= 5
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
GROUP BY
중복을 제거하고 특정 필드의 값들을 보고 싶을때 이용하며, 문법상 GROUP BY에서 명시하는 것은 SELECT 에서도 명시를 해야합니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | BOOK | 20 |
| A006 | BOOK | 43 |
Query)
SELECT PRODUCT
FROM `jayden-project.my_dataset.product`
GROUP BY PRODUCT
Result)
| PRODUCTD |
|---|
| BOOK |
| CANDY |
| CUP |
| PEN |
ORDER BY
특정 컬럼을 기준으로 정렬을 할때 이용하며, 기본은 오름차순이며 DESC를 붙이면 내림차순이 됩니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A002 | CANDY | 1 |
| A001 | PEN | 3 |
| A004 | CUP | 5 |
| A003 | BOOK | 8 |
| A005 | BOOK | 20 |
| A006 | BOOK | 43 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product`
ORDER BY PRODUCT_ID
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | BOOK | 20 |
| A006 | BOOK | 43 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product`
ORDER BY PRODUCT_ID DESC
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A006 | BOOK | 43 |
| A005 | BOOK | 20 |
| A004 | CUP | 5 |
| A003 | BOOK | 8 |
| A002 | CANDY | 1 |
| A001 | PEN | 3 |
SUBQUERIES
개인적으로 생각했을때 StandSQL에서 가장 강점인 기능중 하나로
쿼리 안에 또 다른 쿼리를 넣을 수 있는 기능으로 ()안에 내부 쿼리를 넣어 사용합니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
SELECT TEMP.*
FROM (
SELECT
FROM `jayden-project.my_dataset.product
WHERE PRICE >=5`
) AS TEMP;
Result)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
CROSS JOIN
JOIN은 기본적으로 여러개의 테이블의 데이터를 합칠때 사용하며,
CROSS JOIN은 공통 필드가 없을때 합치는 용도로 사용합니다
CARTESIAN JOIN을 고려해야 합니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
- Project Name : jayden-project
- Dataset : bq_test
- Table : access_log
Origin)
| agent | code | host | method | path | referer | size | user | time |
|---|---|---|---|---|---|---|---|---|
| Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/PMA2014/ | - | 0 | - | null |
| Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/PMA2013/ | - | 0 | - | null |
| Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/db/phpMyAdmin3/ | - | 0 | - | null |
Query)
SELECT *
FROM `jayden-project.my_dataset.product` CROSS JOIN `jayden-project.bq_test.access_log`
Result)
| PRODUCT_ID | PRODUCT | PRICE | agent | code | host | method | path | referer | size | user | time |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A003 | BOOK | 8 | Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/PMA2014/ | - | 0 | - | null |
| A004 | CUP | 5 | Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/PMA2013/ | - | 0 | - | null |
| A005 | USB | 20 | Mozilla/5.0 Jorgee | 404 | 2 | 213.135.229.55 | http://130.211.208.3:80/db/phpMyAdmin3/ | - | 0 | - | null |
LEFT JOIN
JOIN은 기본적으로 여러개의 테이블의 데이터를 합칠때 사용하며,
LEFT JOIN은 USING에서 지정한 컬럼을 기준으로 데이터를 합치며,
왼쪽에 지정한 테이블 기준으로 JOIN을 하며 오른쪽 테이블에 데이터가 없으면
오른쪽에 지정한 테이블의 값을 null로 넣습니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product, producer
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
| A006 | EARPHONE | 10 |
Origin)
| PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|
| A001 | ASA | 2 |
| A002 | ASA | 1 |
| A003 | HG | 4 |
| A004 | HG | 3 |
| A005 | HG | 12 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product` LEFT JOIN `jayden-project.my_dataset.producer`
USING (PRODUCT_ID);
Result)
| PRODUCT_ID | PRODUCT | PRICE | PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|---|---|---|
| A001 | PEN | 3 | A001 | ASA | 2 |
| A002 | CANDY | 1 | A002 | ASA | 1 |
| A003 | BOOK | 8 | A003 | HG | 4 |
| A004 | CUP | 5 | A004 | HG | 3 |
| A005 | USB | 20 | A005 | HG | 12 |
| A006 | EARPHONE | 10 | null | null |
RIGHT JOIN
JOIN은 기본적으로 여러개의 테이블의 데이터를 합칠때 사용하며,
LEFT JOIN은 USING에서 지정한 컬럼을 기준으로 데이터를 합치며,
오른쪽에 지정한 테이블 기준으로 JOIN을 하며 오른쪽 테이블에 데이터가 없으면
왼쪽에 지정한 테이블의 값을 null로 넣습니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product, producer
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
Origin)
| PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|
| A001 | ASA | 2 |
| A002 | ASA | 1 |
| A003 | HG | 4 |
| A004 | HG | 3 |
| A005 | HG | 12 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product` LEFT JOIN `jayden-project.my_dataset.producer`
USING (PRODUCT_ID);
Result)
| PRODUCT_ID | PRODUCT | PRICE | PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|---|---|---|
| A001 | PEN | 3 | A001 | ASA | 2 |
| A002 | CANDY | 1 | A002 | ASA | 1 |
| A003 | BOOK | 8 | A003 | HG | 4 |
| A004 | CUP | 5 | A004 | HG | 3 |
| A005 | null | null | A005 | HG | 12 |
INNER JOIN
JOIN은 기본적으로 여러개의 테이블의 데이터를 합칠때 사용하며,
INNER JOIN은 USING에서 지정한 컬럼을 기준으로 데이터를 합치며,
양쪽 테이블 모두 있는 데이터만 산출합니다
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product, producer
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
Origin)
| PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|
| A001 | ASA | 2 |
| A002 | ASA | 1 |
| A003 | HG | 4 |
| A004 | HG | 3 |
| A005 | HG | 12 |
Query)
SELECT *
FROM `jayden-project.my_dataset.product` LEFT JOIN `jayden-project.my_dataset.producer`
USING (PRODUCT_ID);
Result)
| PRODUCT_ID | PRODUCT | PRICE | PRODUCT_ID | PRODUCER | UNIT_COST |
|---|---|---|---|---|---|
| A001 | PEN | 3 | A001 | ASA | 2 |
| A002 | CANDY | 1 | A002 | ASA | 1 |
| A003 | BOOK | 8 | A003 | HG | 4 |
| A004 | CUP | 5 | A004 | HG | 3 |
WITH
WITH 절은 서브 쿼리와 비슷한 문법으로 미리 WITH절과 별칭으로 만들어 놓고
다른 쿼리에서 미리 만들어 놓은 쿼리에 참조를 할 수 있습니다.
- Project Name : jayden-project
- Dataset : my_dataset
- Table : product
Origin)
| PRODUCT_ID | PRODUCT | PRICE |
|---|---|---|
| A001 | PEN | 3 |
| A002 | CANDY | 1 |
| A003 | BOOK | 8 |
| A004 | CUP | 5 |
| A005 | USB | 20 |
Query)
WITH temp AS (
SELECT *
FROM `jayden-project.my_dataset.product
WHERE PRICE >=5`
)
SELECT *
FROM temp;