이번 5월부터 Google Cloud Professional Data Engineer을 취득하기 위해 준비하면서 공부하는 내용들을 틈틈히 포스팅 해보려고 합니다.
오늘 포스팅할 내용은 Dataproc에 대한 간단한 소개를 하려고 합니다.
Dataproc 이란?
구글의 하둡 에코 시스템으로 Hadoop, Spark, Hive 등을 이용할 수 있는 서비스 입니다.
실습
구글 클라우드 콘솔에 들어가서 좌측 상단 메뉴 - Dataproc을
누릅니다.
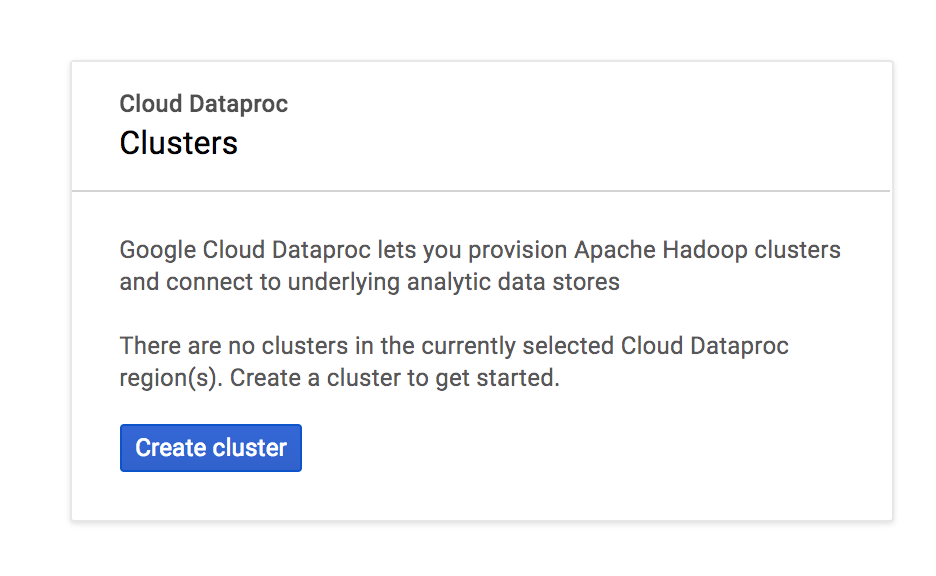
먼저 Cluster 부터 만들어보도록 하겠습니다. Create Cluster를 누릅니다.
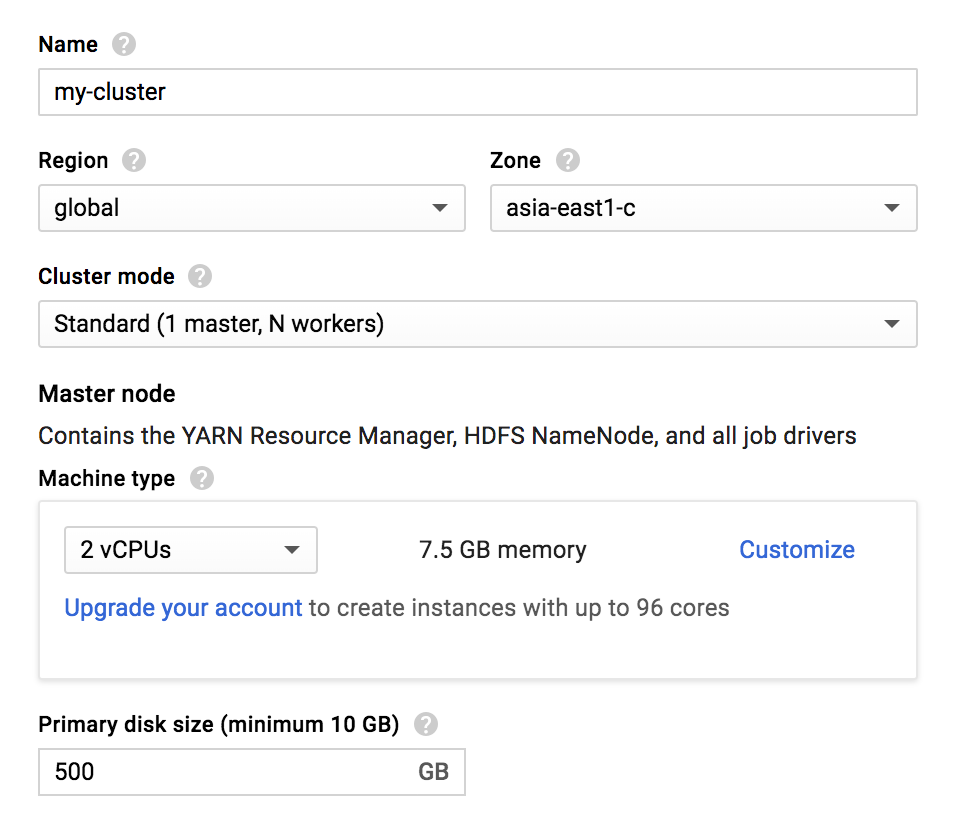
먼저 Master Node에 대한 설정입니다.
- Name : 클러스터의 이름
- Region : 클러스터가 설정될 Region
- Zone : 클러스터가 설정될 Zone
- Cluster mode : Master Node와 Worker Node에 대한 구성을 선택
- 단일 노드(마스터1, 작업자 X)
- 표준(마스터1, 작업자 N)
- 고가용성(마스터3, 작업자 N)
- Machine type : 하드웨어 설정을 선택
- Primary disk size : Master node에서 사용할 디스크 사이즈를 설정
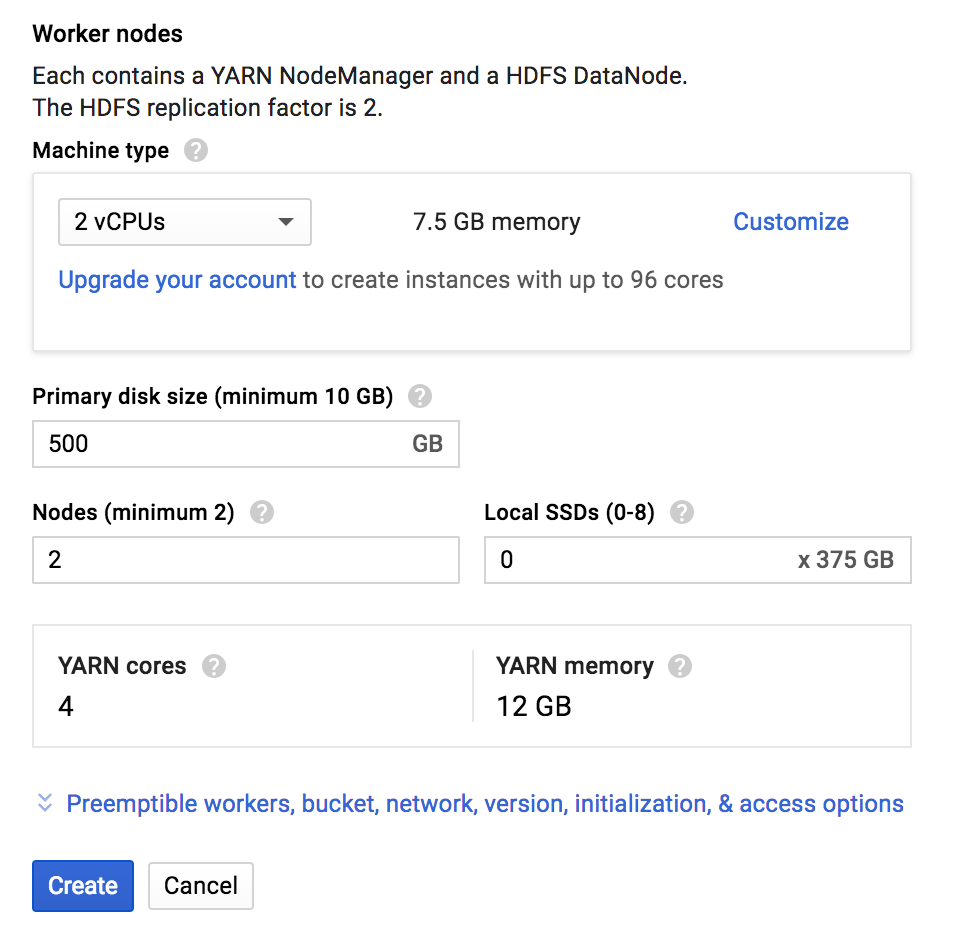
다음 Worker Node에 대한 설정입니다.
- Machine type : 하드웨어 설정을 선택
- Primary disk size : Worker nodes에서 사용할 디스크 사이즈를 설정
- Nodes : Worker node의 개수 설정
(최소 2개 이상) - Local SSDs : 각 SSD(Solid State Disk)는 375GB의 빠른 로컬 저장소를 제공합니다. SSD를 1개 이상 연결하면 HDFS 데이터 블록 및 로컬 실행 디렉토리가 SSD 디스크에 분산됩니다. HDFS는 선점형 노드에서 실행되지 않습니다.
` ** YARN(MapReduce v2) : 하둡 클러스터 내의 자원을 중앙 관리하고, 그 위에 다양한 애플리케이션을 실행 및 관리가 가능하도록 확장성과 호환성을 높인 하둡 2.x의 플랫폼 `
설정을 끝내고 Create 버튼을 누릅니다.
그럼 다음과 같이 생성이 시작됩니다.
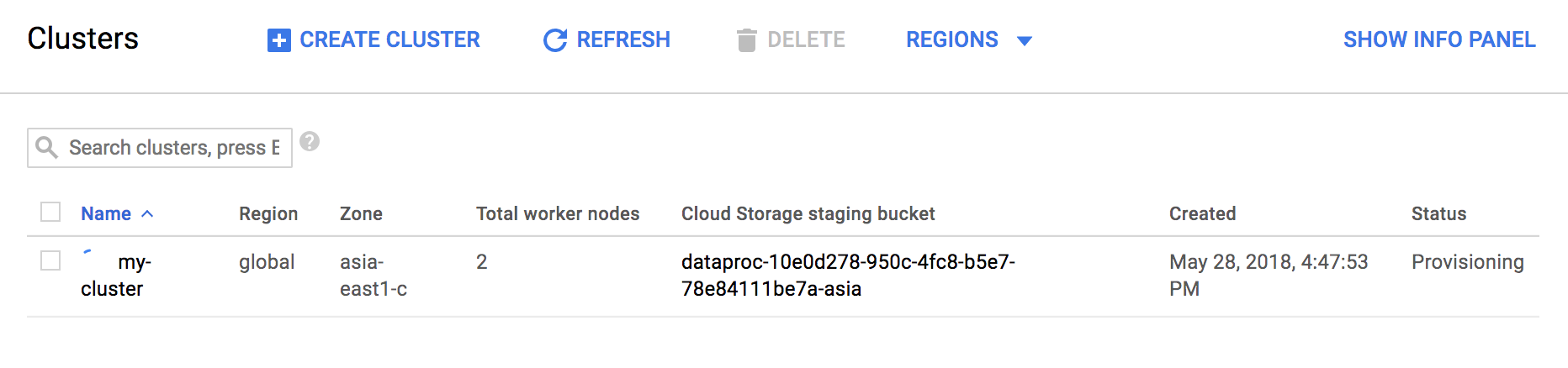
생성이 완료되면 아래와 같이 누를 수 있습니다.
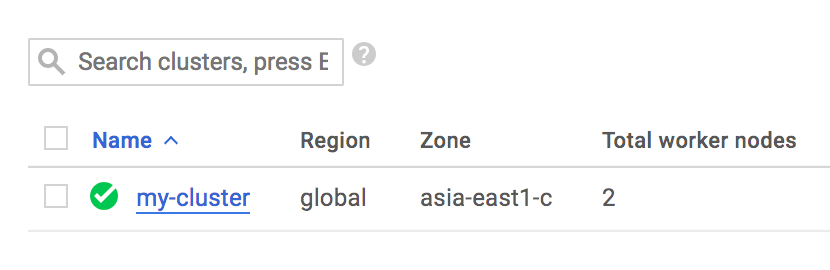
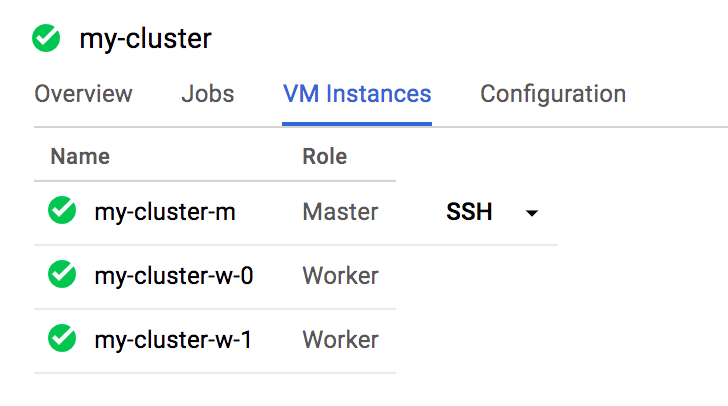
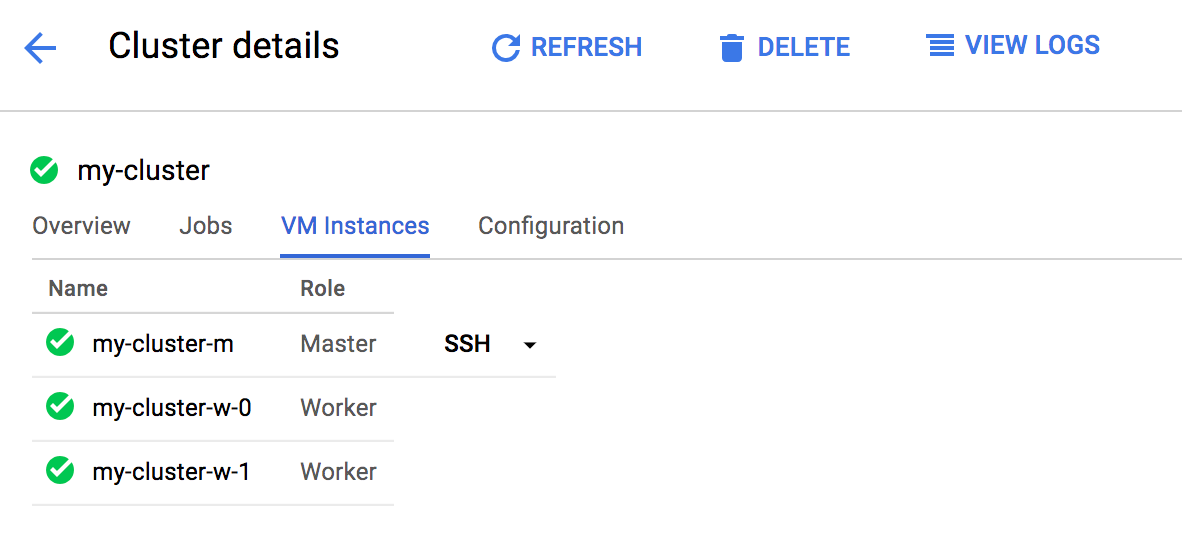
안쪽에 들어가서 VM Instances를 보면 생성된 Master node와 Worker nodes를 볼 수 있습니다.
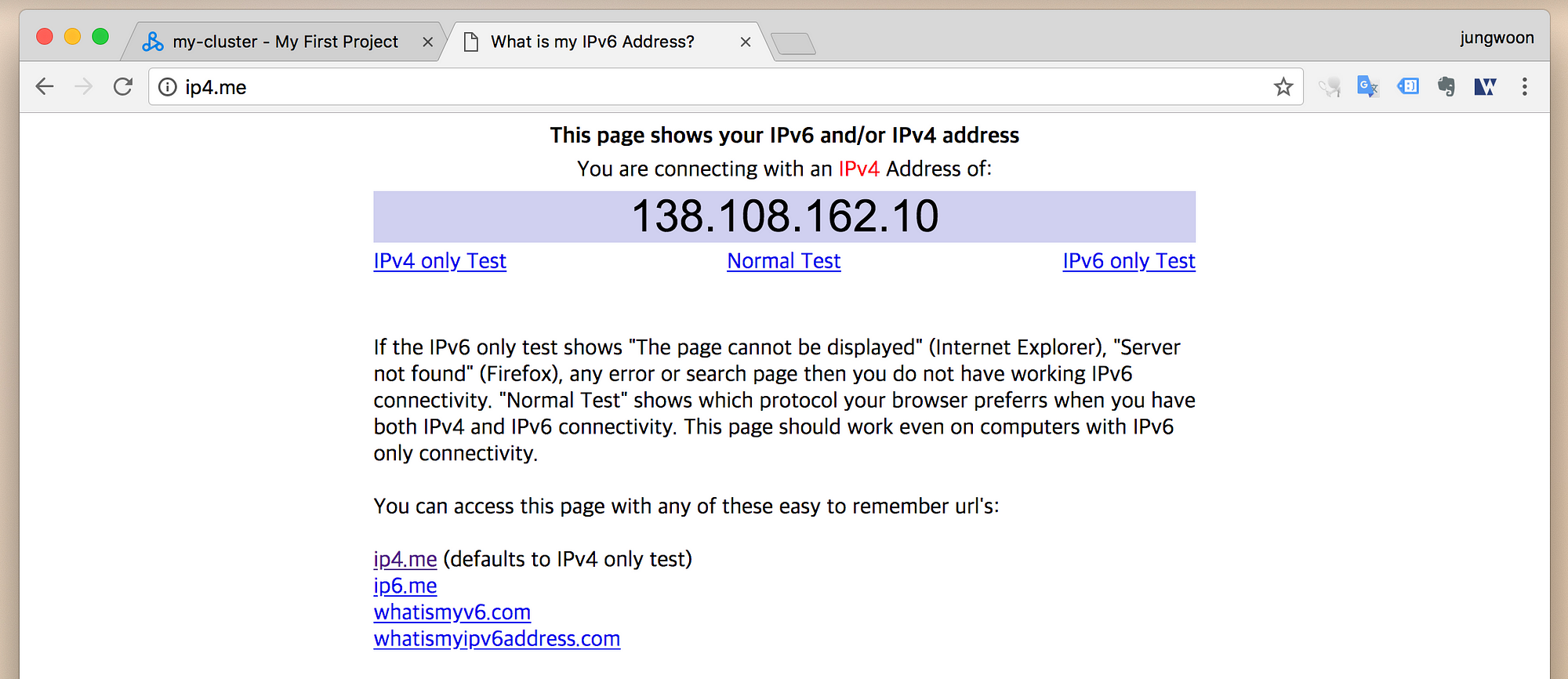
기본적인 방화벽 설정때문에, 현재 내 아이피(클라우드 말고 현재 접속하는 로컬 IP)를 등록해야 합니다.
먼저 ip4.me 에 들어가서 본인의 IP를 확인합니다.
방화벽 설정을 위해서 메뉴 - VPC network를 누릅니다.
그 다음 좌측 메뉴에서 Firewall rules를 클릭합니다.
그럼 다음과 같은 화면을 볼 수 있습니다. 상단의 CREATE FIREWALL RULE을 클릭합니다.
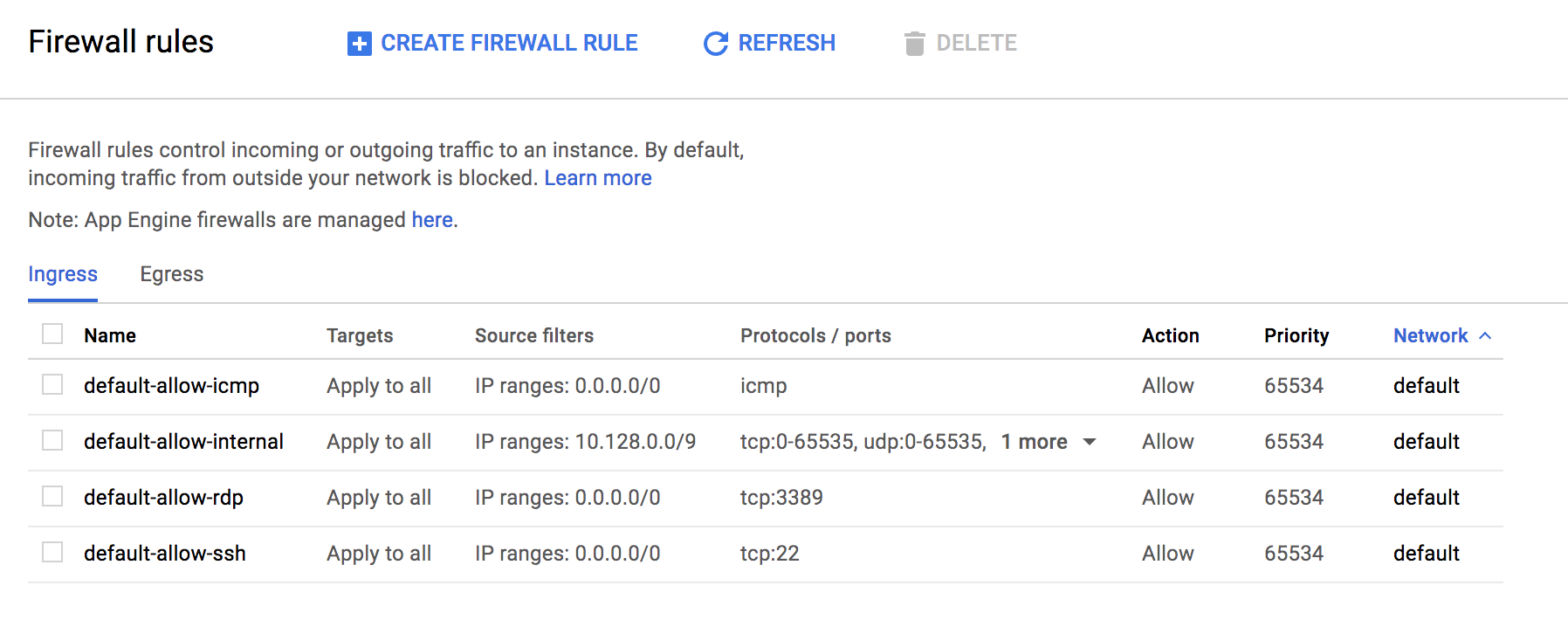
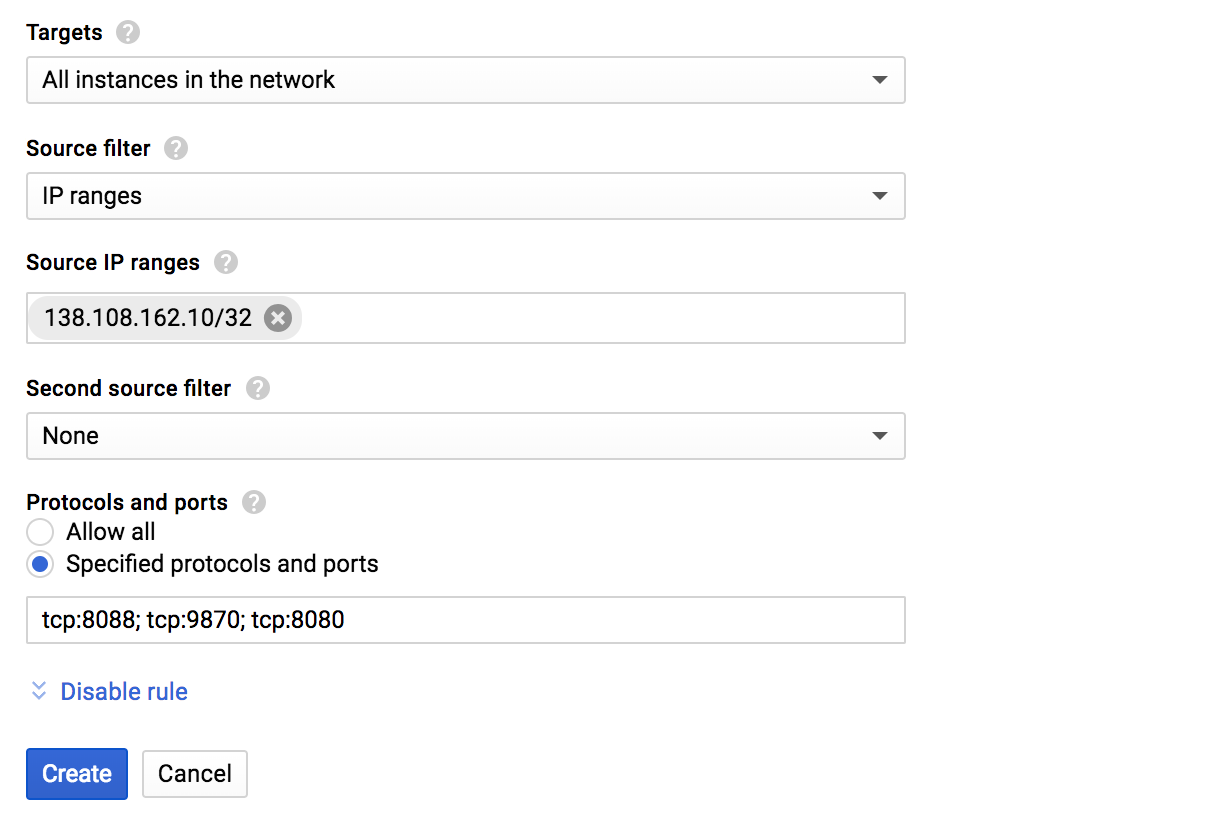
그럼 새로운 방화벽 규칙을 넣을 수 있습니다. 나머지는 다 기본값으로 두고 아래 언급한 내용만 수정 하도록 합니다.
- Name : default-allow-dataproc-access (원하는거 아무거나 가능)
- Targets : All instances in the network
- Source IP ranges : 위의
ip4.me에서 알게된 IP주소 / 32 (ex - 138.108.162.10/32) - Protocols and ports
- Specified protocols and ports
tcp:8088;tcp:9870;tcp:8080
다 되면 Create를 누릅니다.
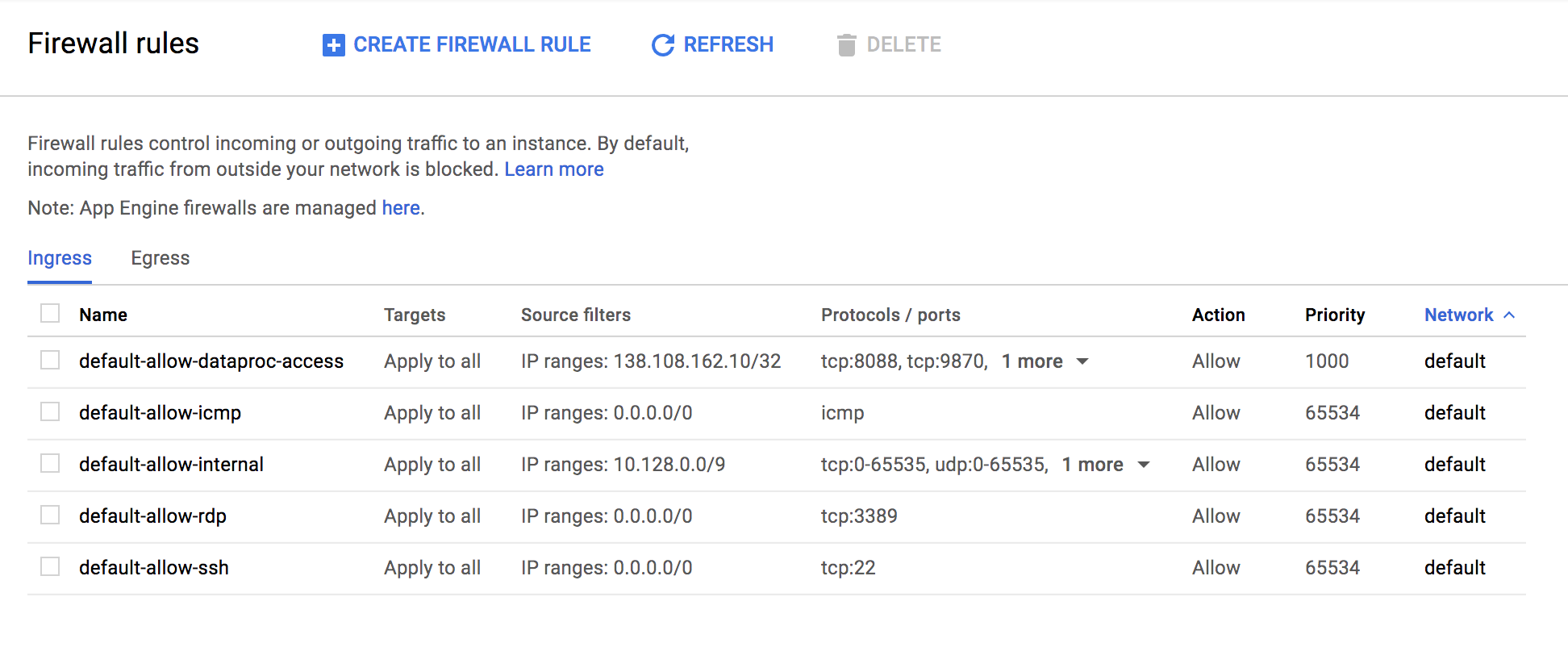
그럼 아래와 같이 새로운 규칙이 추가된것을 확인할 수 있습니다.
다시 메뉴 - Dataproc - Clsters를 누릅니다.
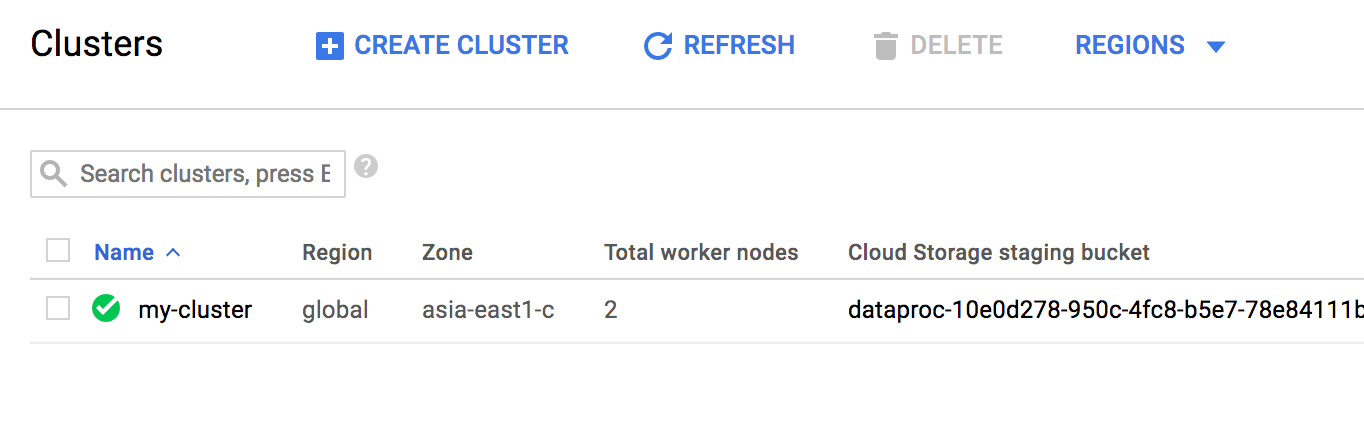
그럼 다음과 같이 좀 전에 만들었었던 my-cluster를 눌러서 상세 페이지로 들어갑니다
VM Instances를 누르고 Master node를 눌러서 상세 페이지로 들어갑니다.
그럼 다음과 같은 페이지가 나오는데 여기서 스크롤을 조금 더 내립니다.
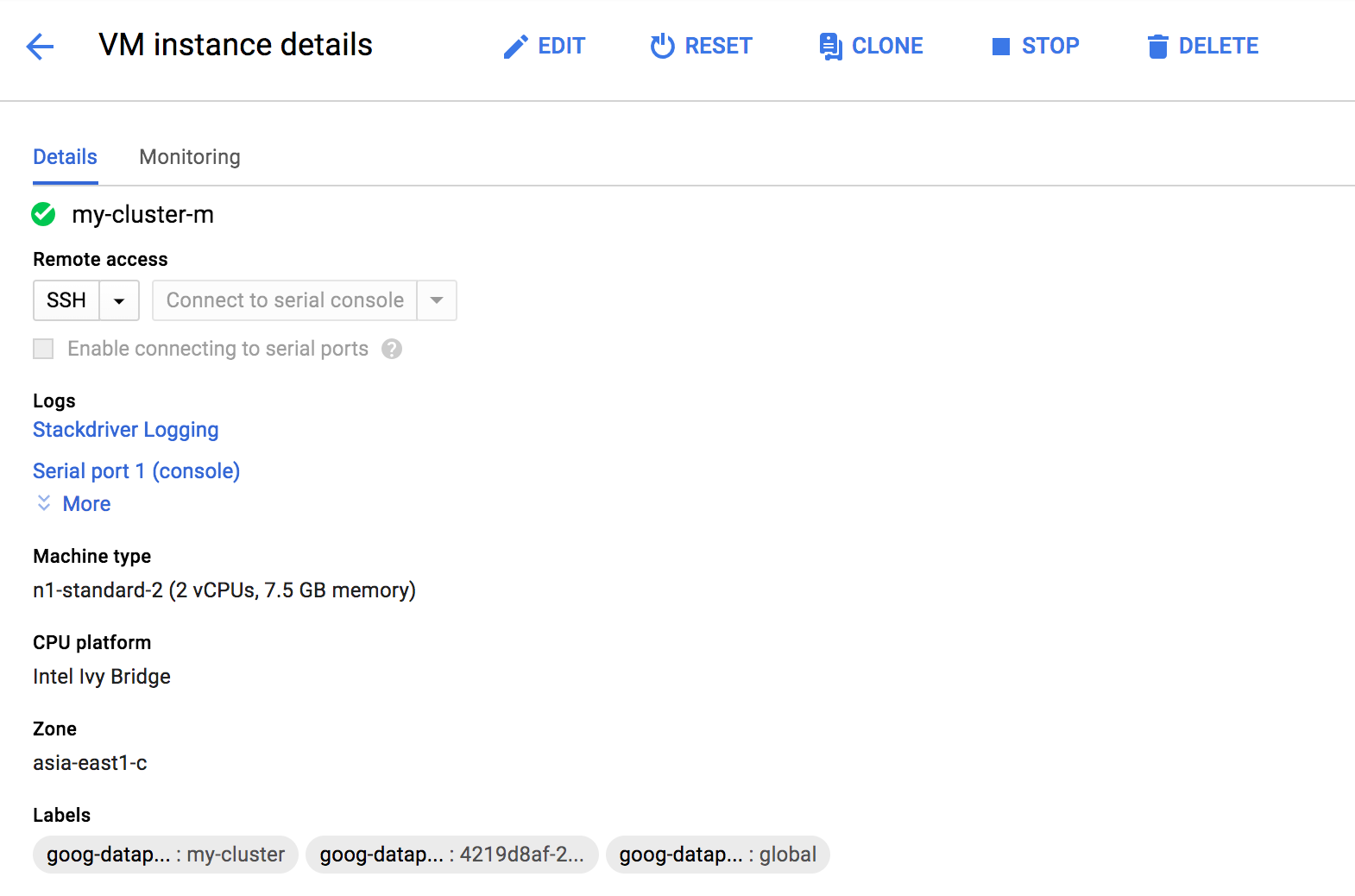
그럼 External IP에 대한 정보가 나오는데 해당 IP를 복사해놓습니다.

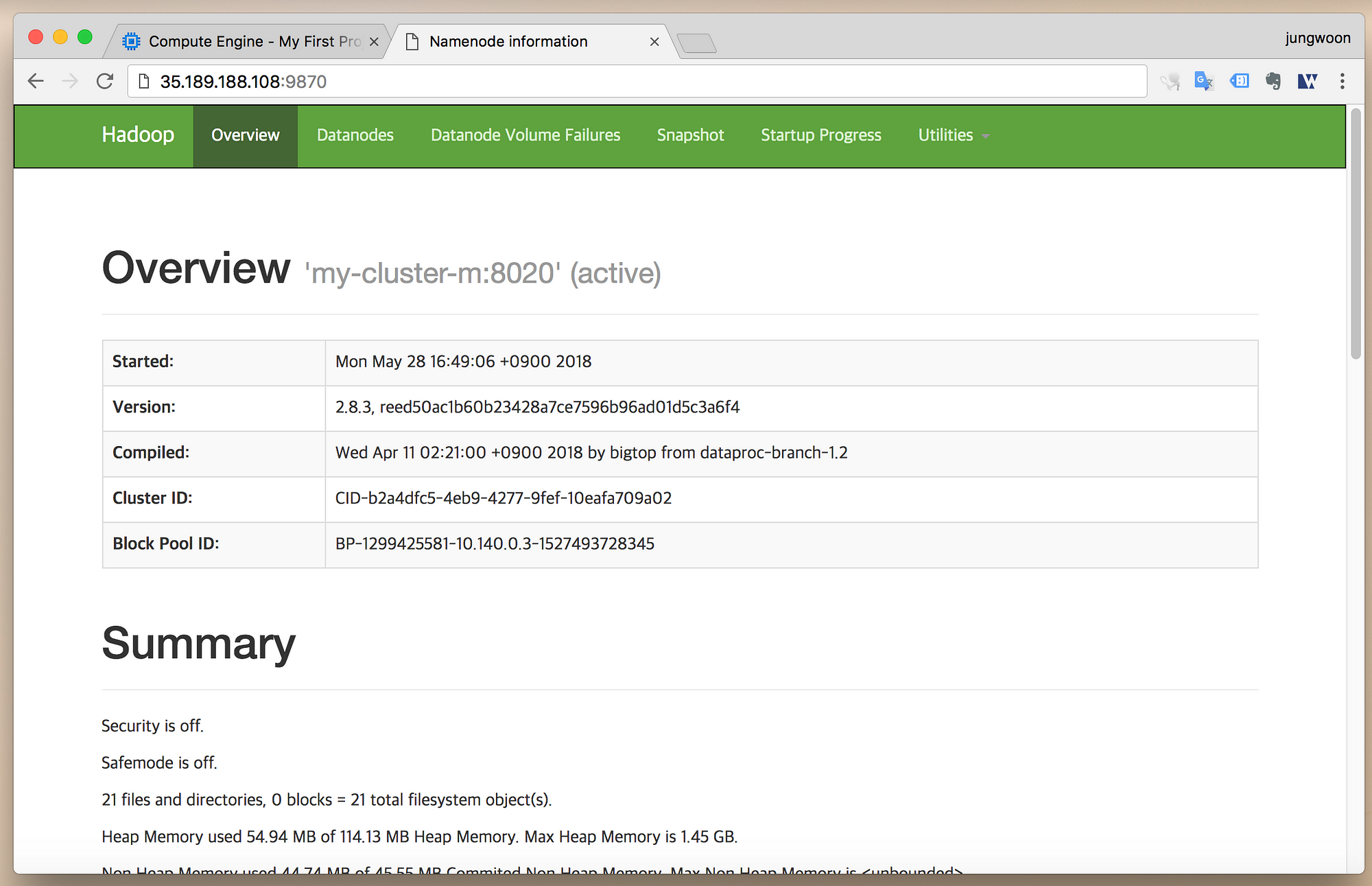
웹 브라우저의 주소창에 External IP:9870 (ex - 35.189.188.108:9870)를
입력하면 다음과 같이 Hadoop의 NameNode UI 관리 페이지를 볼수 있습니다.
(위의 방화벽 설정을 하지 않으면 접속이 되지 않습니다)
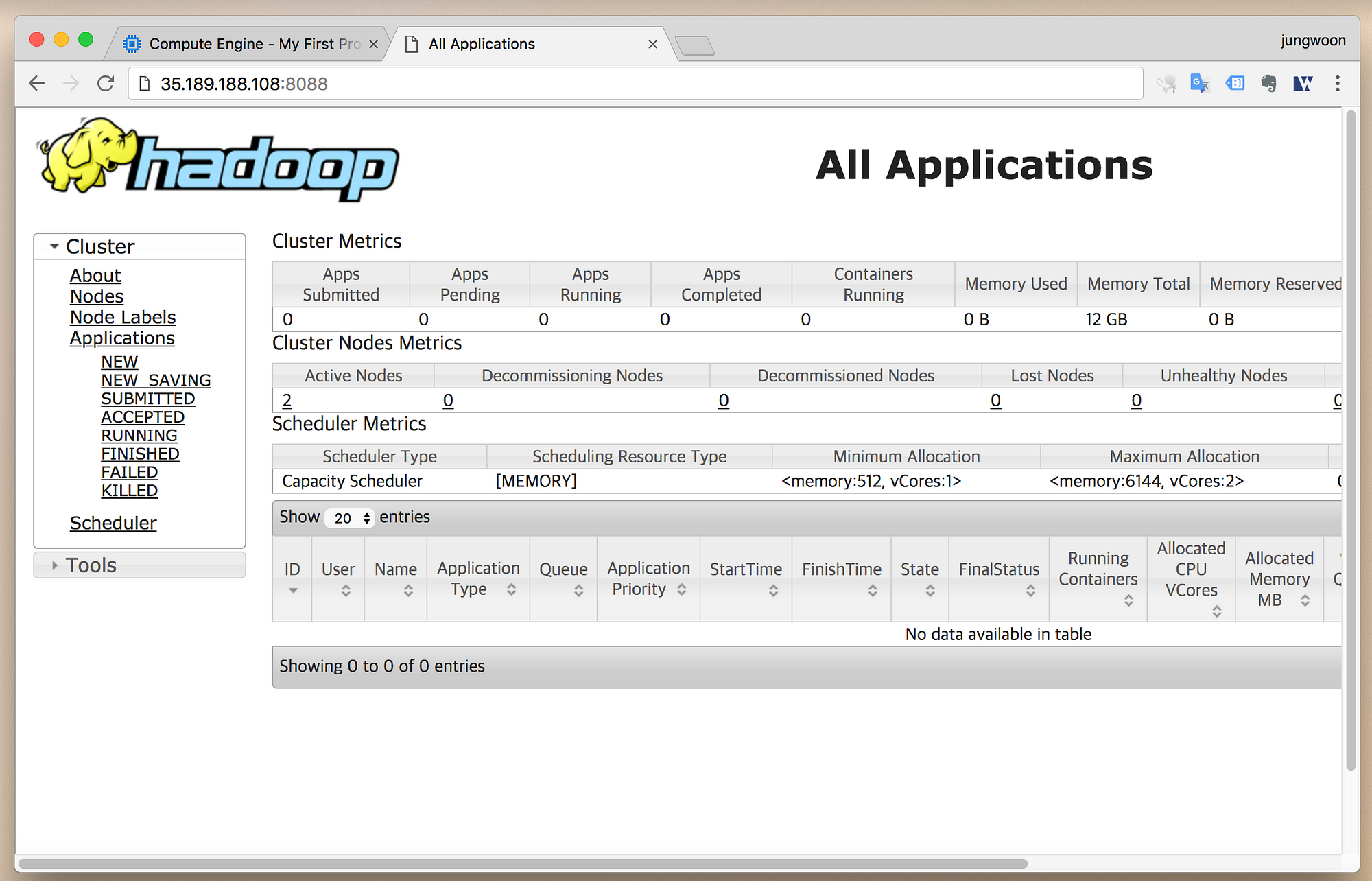
이번에는 웹 브라우저의 주소창에 External IP:8088 (ex - 35.189.188.108:8088)를
입력하면 다음과 같이 Hadoop의 Resource Manager용 웹 UI를 볼 수 있습니다.
(위의 방화벽 설정을 하지 않으면 접속이 되지 않습니다)
그 다음은 job을 실행 시켜주기 위한 자료를 먼저 준비해보도록 하겠습니다.
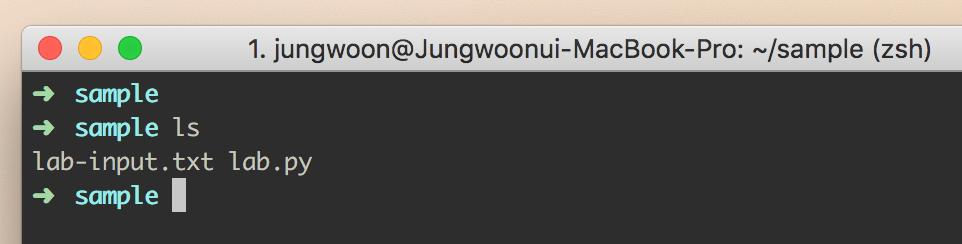
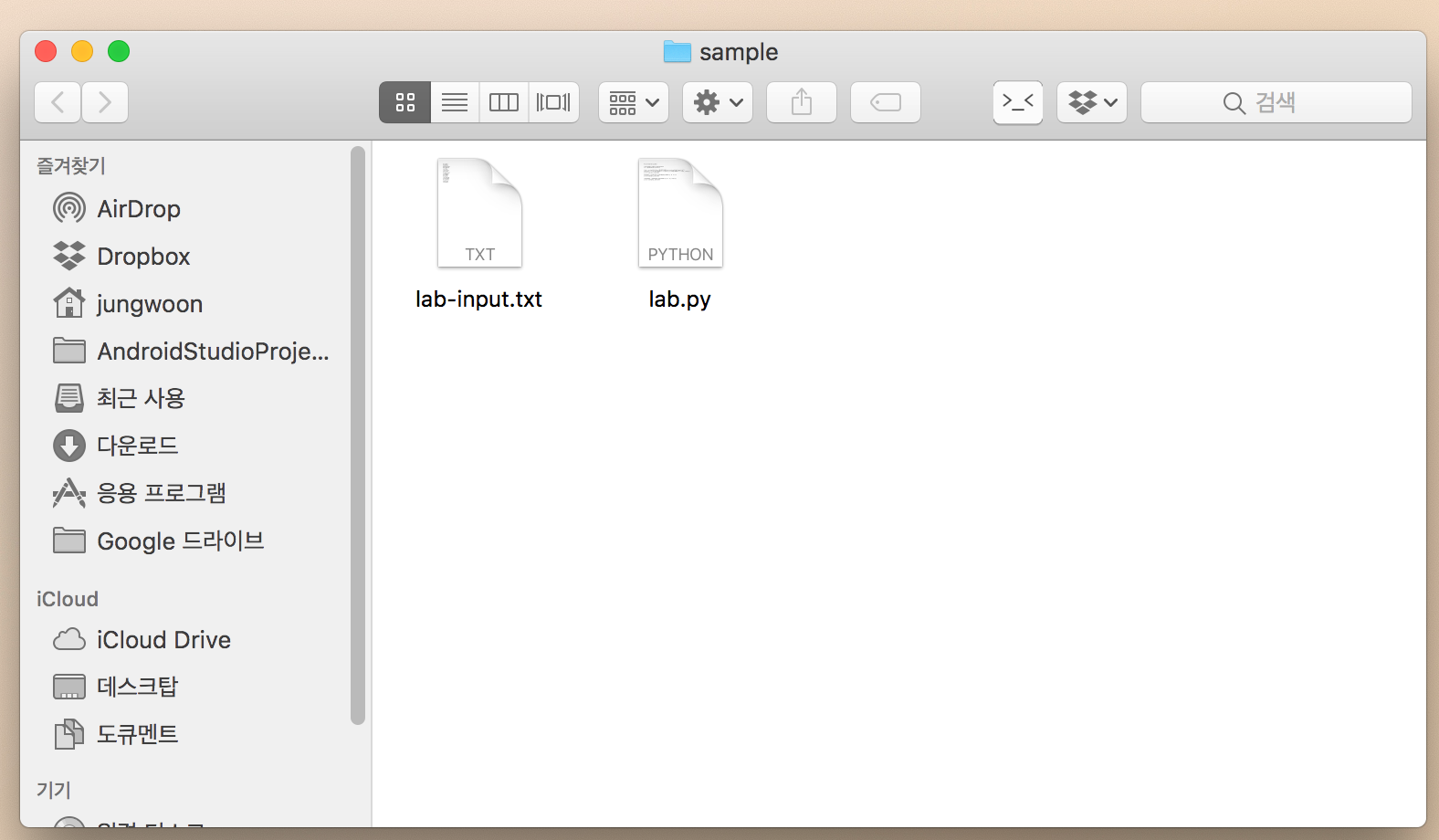
임시로 자신의 컴퓨터에 sample이란 이름의 디렉토리를 만들고
아래 두 파일을 만들어서 넣어줍니다.
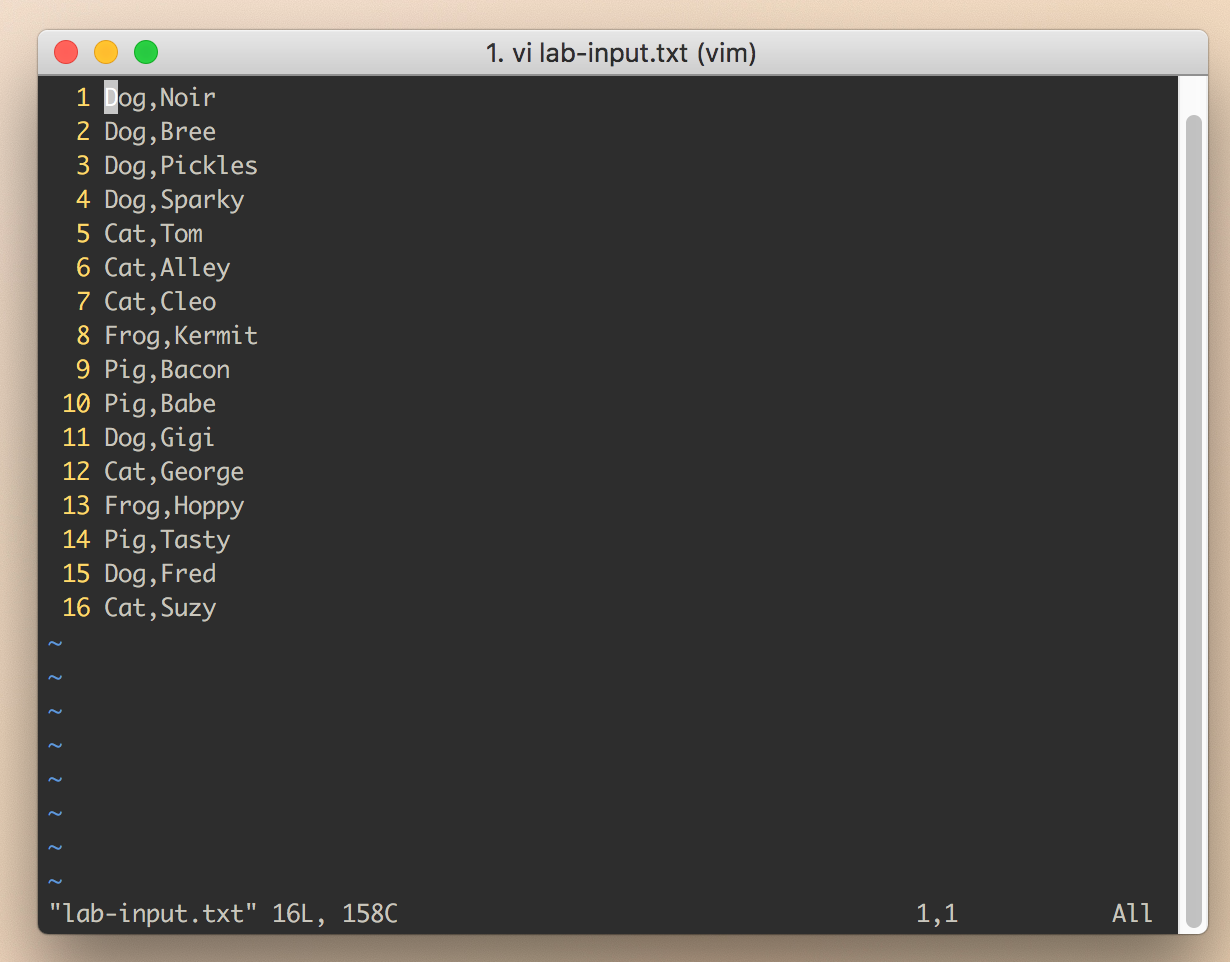
데이터가 들어있는 lab-input.txt를 아래 내용으로 만들어 줍니다.
Dog,Noir
Dog,Bree
Dog,Pickles
Dog,Sparky
Cat,Tom
Cat,Alley
Cat,Cleo
Frog,Kermit
Pig,Bacon
Pig,Babe
Dog,Gigi
Cat,George
Frog,Hoppy
Pig,Tasty
Dog,Fred
Cat,Suzy
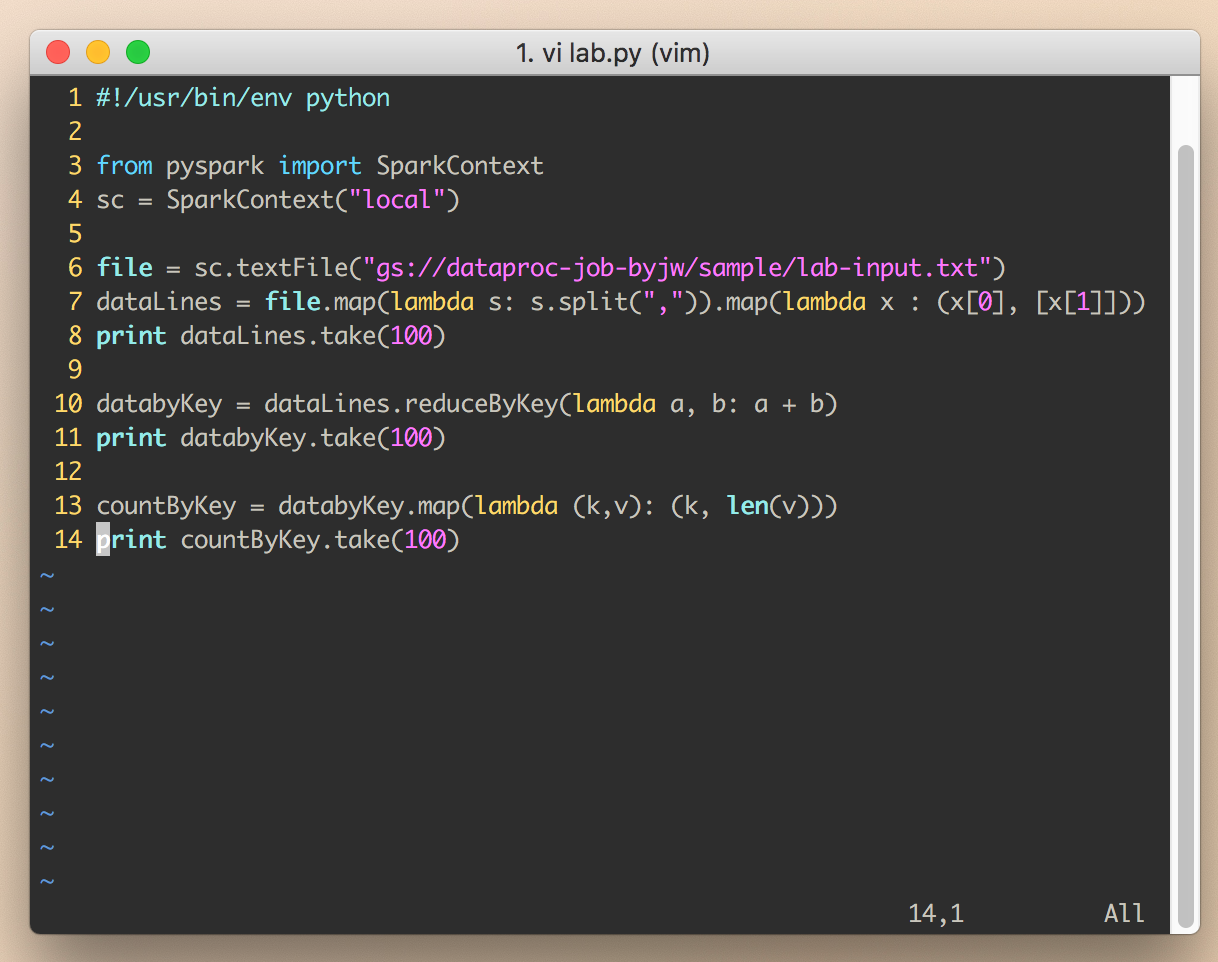
그 다음 실제 작업내용이 들어있는 lab.py 파일을 아래 내용으로 만들어 줍니다.
#!/usr/bin/env python
from pyspark import SparkContext
sc = SparkContext("local")
file = sc.textFile("gs://dataproc-job-byjw/sample/lab-input.txt") # gs://본인 버킷 네임/unstructured/lab2-input.txt
dataLines = file.map(lambda s: s.split(",")).map(lambda x : (x[0], [x[1]]))
print dataLines.take(100)
databyKey = dataLines.reduceByKey(lambda a, b: a + b)
print databyKey.take(100)
countByKey = databyKey.map(lambda (k,v): (k, len(v)))
print countByKey.take(100)
그럼 다음과 같은 환경이 될 것입니다.
그 다음 클라우드 콘솔 화면에서 메뉴 - Storage를 누릅니다.
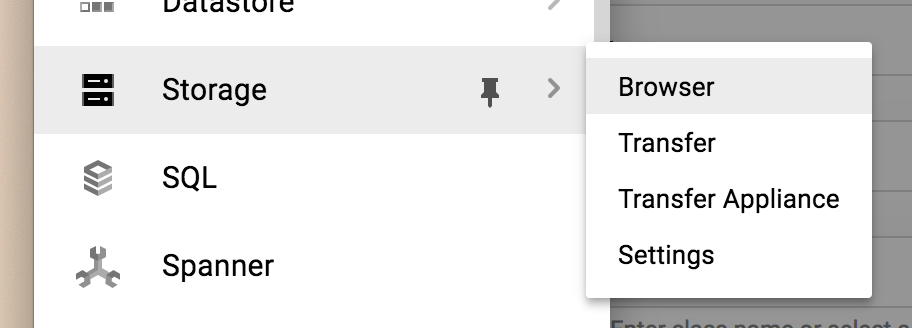
그럼 아래와 같은 bucket들이 있는 화면이 나타납니다.
(저는 이미 만들어놓은 bucket들 때문에 아래 리스트에 내용들이 나왔습니다)
여기서 job을 위한 새로운 버킷을 만들기 위해 상단에 CREATE BUCKET을 누릅니다.
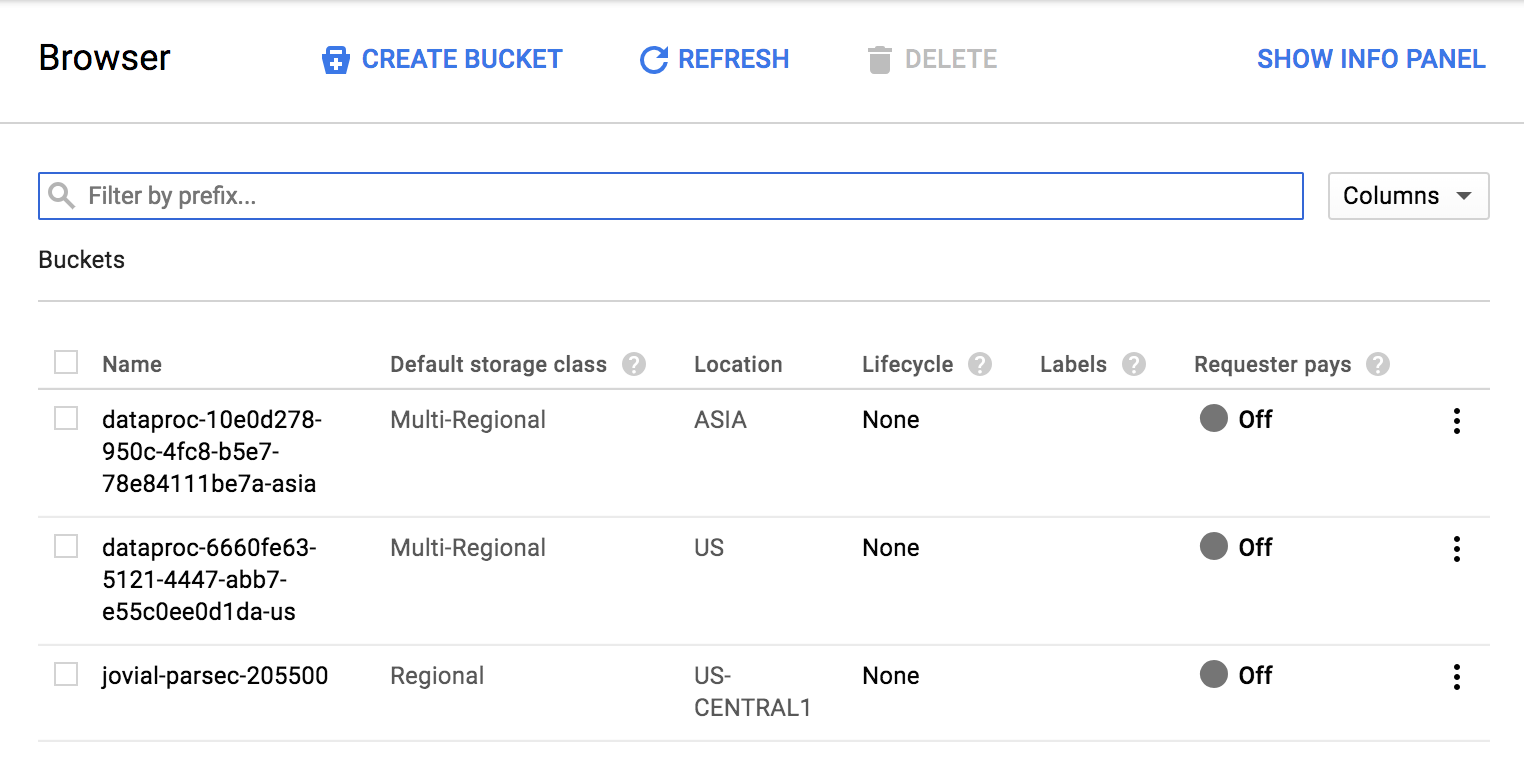
그 다음 아래와 같이 설정을 해주고 Create 버튼을 눌러줍니다.
- Name : dataproc-job-byjw (임의로 주셔도 됩니다)
- Default storage class : Regional
- Location : us-west1
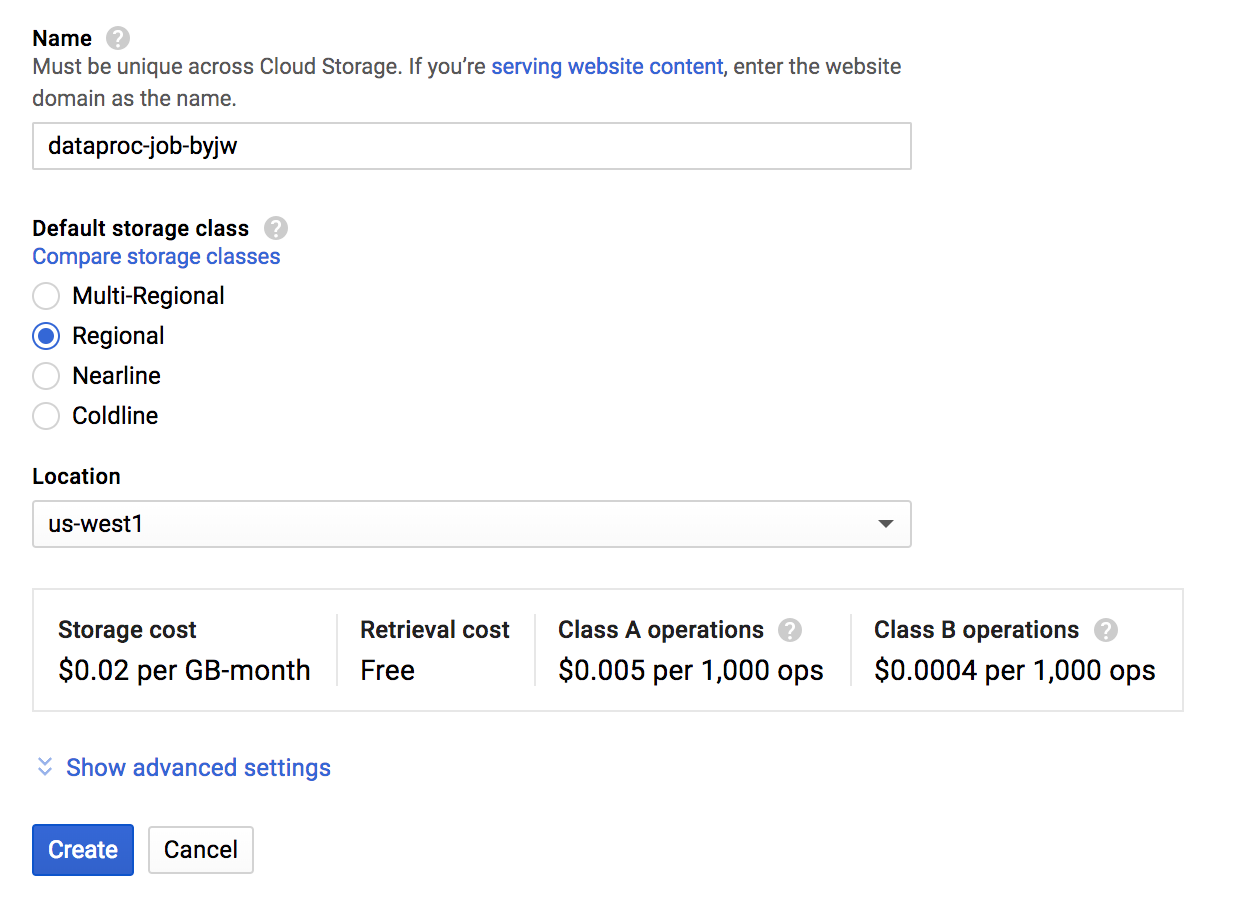
그럼 곧 지금 만든 bucket이 생성되게 됩니다. 해당 bucket으로 들어가 봅니다.
그 다음 상단의 Upload folder를 누릅니다.
그럼 아래와 같이 나오는데, 좀 전에 만들었던 sample를 업로드 해줍니다.
그럼 다음과 같은 메시지가 나오는데 업로드를 누릅니다.
업로드가 완료가 되면 다음과 같은 상태창을 확인할 수 있습니다.
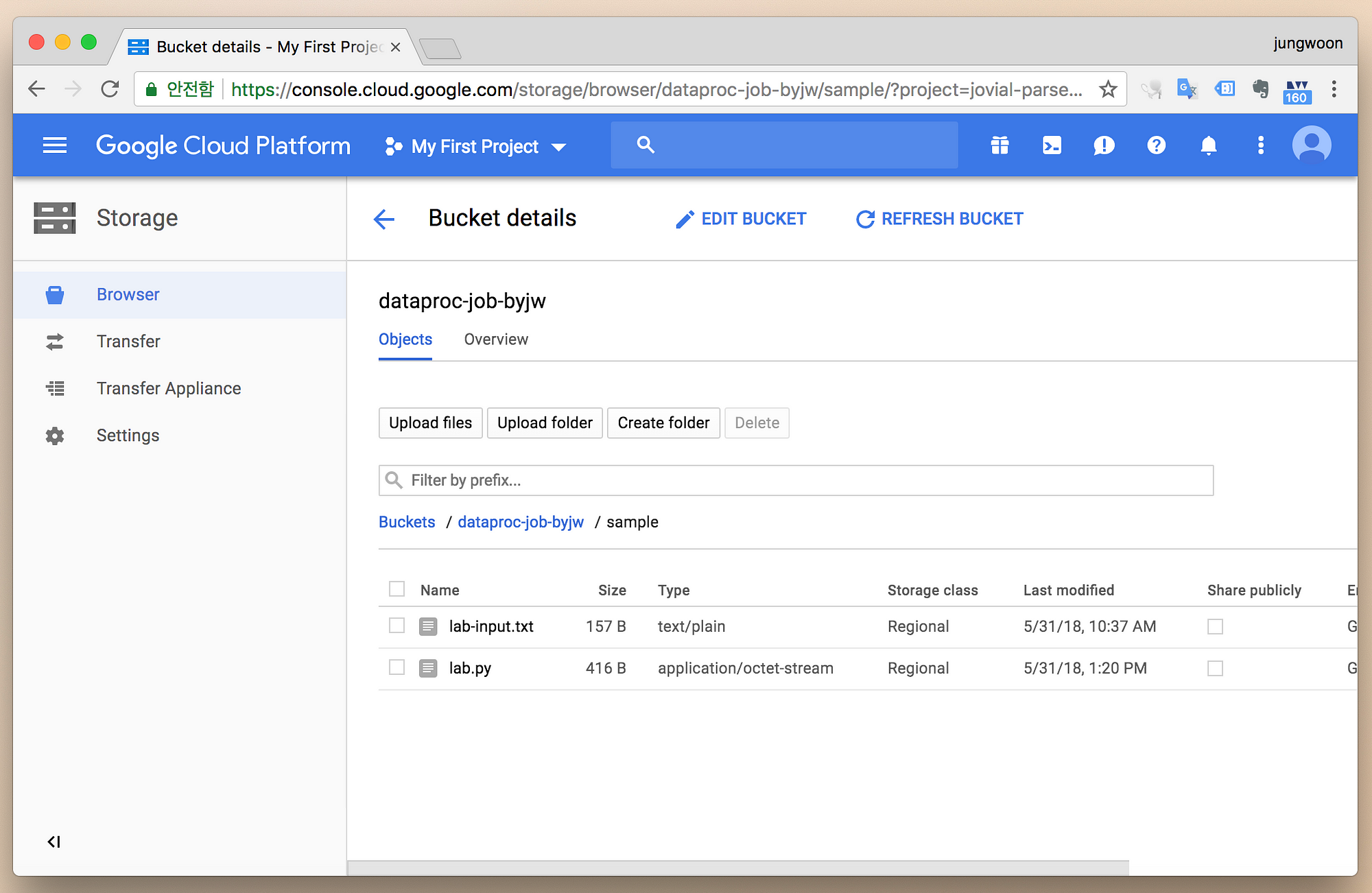
그 다음 방금 만든 경로에 가보면 아래와 같이 정상적으로 업로드 된 것을 확인할 수 있습니다.
다시 메뉴 - Dataproc을 들어갑니다.
Jobs를 누르면 아래와 같은 화면이 보입니다.
여기서 Submit job 버튼을 누릅니다.
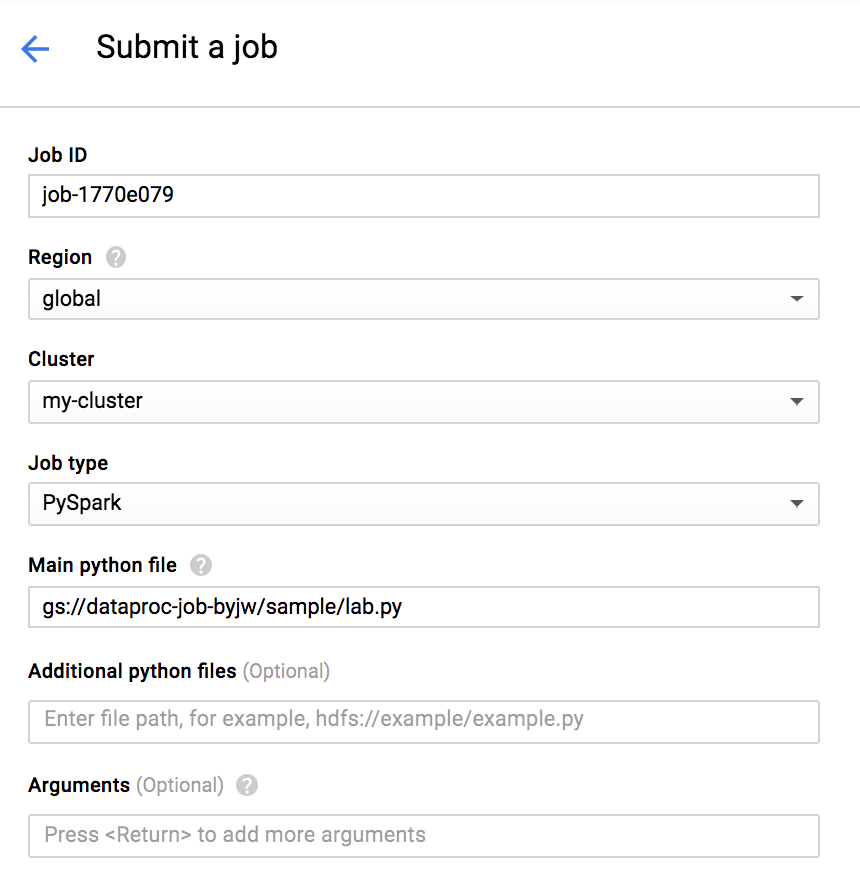
그럼 아래와 같이 설정을 하고 Submit을 누릅니다.
- Job ID : job-1770e079 (저는 자동생성된 ID를 사용했습니다)
- Region : global
- Cluster : my-cluster (아까 만든 클러스터입니다)
- Job type : 아래와 같은 다양한 파일들을
GCS나hdfs에 올려놓고 손쉽게Job을 돌릴 수 있습니다.- Hadoop
- Spark
PySpark- 이번 실습에서는 PySpark를 사용하겠습니다.- Hive
- SparkSql
- Pig Main python file : gs://dataproc-job-byjw/sample/lab.py (아까 업로드한 lab.py의 경로를 올립니다)
그럼 아래와 같이 job이 돌아가는걸 확인할 수 있습니다.

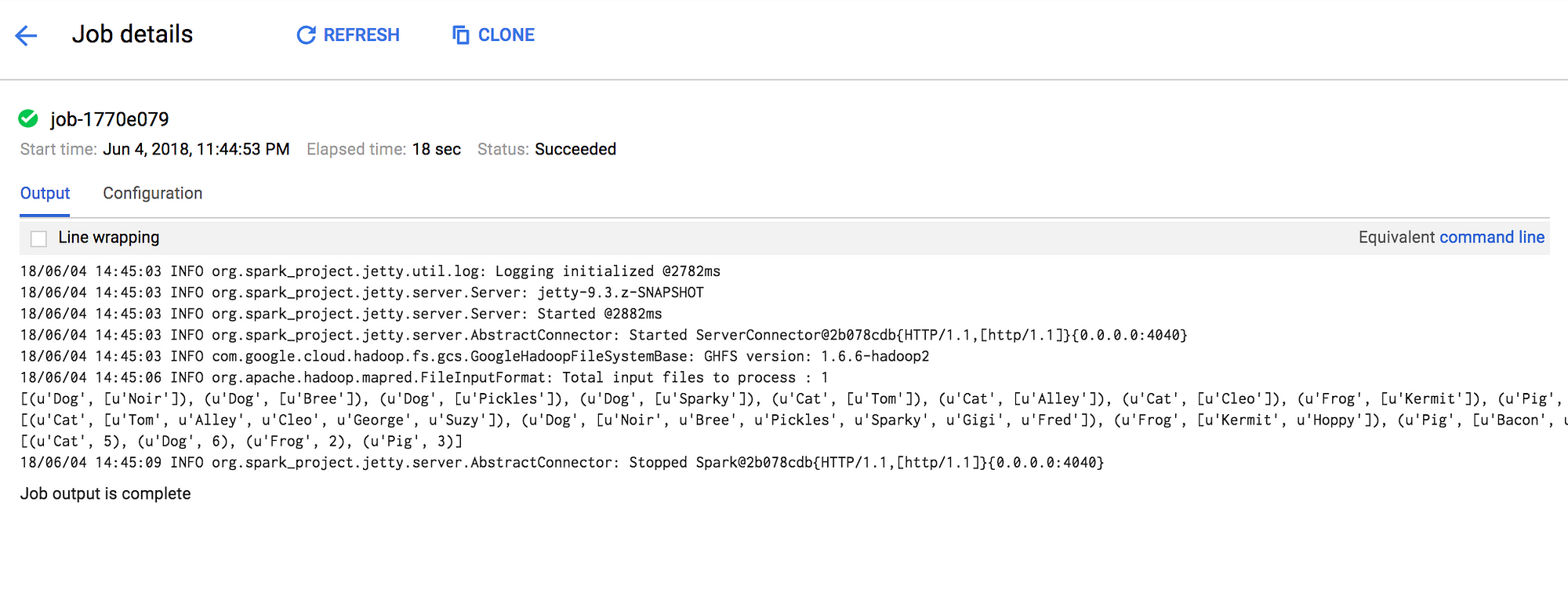
완료가 되면 아래와 같이 나옵니다
(에러가 나면 실패한 Job ID를 클릭해서 로그를 보고 잘못된 부분을 찾아야 합니다)

결과는 해당 Job의 상세 피이지에 들어가면 아래와 같이 확인할 수 있습니다.
마무리
이 외에도 명령어를 통한 방법도 있고, Pig 파일을 만들어서 실행하는 방법등도 다양하게 있습니다. 나중에 제가 공부를 해서 해당 부분에 대해서 추가로 올리도록 하려고 합니다.
혹시 잘못된 부분이 있으면 편하게 댓글 부탁 드립니다.