이번 5월부터 Google Cloud Professional Data Engineer을 취득하기 위해 준비하면서 공부하는 내용들을 틈틈히 포스팅 해보려고 합니다.
오늘 포스팅할 내용은 GCP의 Bigdata 관련 플랫폼에 대한 간단한 소개를 하려고 합니다.
예전에 포스팅한 내용도 있고 새로 포스팅하는 내용도 있을 예정입니다.
클라우드 컴퓨팅이란?
| 온 프레미스 | 데이터 센터 | 클라우드 컴퓨팅 | |
|---|---|---|---|
| 하드웨어를 누가 소유 하는가? | 당신 | 당신 | 클라우드 |
| 네트워크와 기기들을 누가 관리 하는가? | 당신 | 데이터 센터 | 클라우드 |
| 어떤 부분에 대해서 돈을 지불하는가? | 모든 것 | 하드웨어 비용 + 공간 | 사용한 만큼 지불 |
구글의 혁신적인 데이터 테크놀로지
| 연도 | 기술 | 구글 제품 |
|---|---|---|
| 2002 | GFS | Cloud Storage |
| 2004 | MapReduce | DataProc |
| 2006 | BigTable | BigTable |
| 2008 | Dremel | BigQuery |
| 2009 | Colossus | Cloud Storage |
| 2010 | Flume | Data Flow |
| 2011 | Megastore | DataStore |
| 2012 | Spanner | Spanner |
| 2013 | Millwheel | Data Flow |
| 2013~2014 | PubSub | PubSub |
| 2014 | F1 | |
| 2015 | TensorFlow | Cloud ML |
구글의 플랫폼들 (기능면)
- Foundation
- Compute Engine
- Cloud Storage
- …
- Database
- Datastore
- Cloud SQL
- Cloud Bigtable
- Analytics and ML
- BigQuery
- Cloud Datalab
- Translate API
- …
- Data-handling frameworks
- Cloud Pub/Sub
- Cloud Dataflow
- Cloud Dataproc
구글의 클라우드 빅데이터 및 머신러닝 플랫폼들
- Change where you compute
- Databases, Storage, and Hadoop
- Cloud Databases : Cloud SQL, Cloud Data Store, Cloud Bigtable…
- Proven storage platform : Cloud Storage
- Hadoop / Spark / Pig / Hive : Cloud Dataproc
- Databases, Storage, and Hadoop
- Scalability & Reliability
- Messaging and Data Processing
- Reliable, large scale messaging : Cloud Pub/Sub
- Flexible, scalable and reliable data processing : Cloud dataflow, Cloud Dataproc
- Messaging and Data Processing
- Change how you compute
- Exploration, analytics and intelligence
- Data exploration and business intelligence : Cloud Datalab, Cloud Data Studio
- Fast & economical data warehouse for large-scale data analytics : Google BigQuery
- Machine learning : Cloud Machine Learning, Vision API, Speech API, Translate API
- Exploration, analytics and intelligence
Google Cloud Storage의 gsutil 명령어 살펴보기
Google Cloud의 Storage인 GCS(=Google Cloud Storage)는 AWS(Amazon Web Service)의 S3에 해당하는 서비스입니다.
자세한 사항은 구글 공식 가이드를 참고하세요
gsutil을 위한 사전 준비
만약 gcloud가 설치되어있지 않다면 Google Cloud SDK(=gcloud) 설치하기를 참고하여 설치를 먼저 진행합니다
그 다음 아래 명령어를 통해서 gsutil 컴포넌트를 설치하면 사용준비가 끝이 납니다
$ gcloud components install gsutil # gsutil 명령어를 다운받아보겠습니다
gsutil 명령어 모음
$ gsutil list # 나의 버킷 리스트 보기
$ gsutil ls -r gs://버킷이름 # 버킷 안에 들어있는 파일 확인
$ gsutil du -s gs://버킷이름 # 버킷 용량 확인
$ gsutil mb gs://버킷이름 # 버킷 생성
$ gsutil rb gs://버킷이름 # 버킷 삭제
$ gsutil cp 로컬 파일 위치 gs://버킷이름 # 로컬 -> 버킷 복사
$ gsutil cp gs://버킷이름 로컬 파일 위치 # 버킷 -> 로컬 복사
$ gsutil mv 로컬 파일 위치 gs://버킷이름 # 로컬 -> 버킷 이동
$ gsutil mv gs://버킷이름 로컬 파일 위치 # 버킷 -> 로컬 이동
$ gsutil rm gs://버킷이름/파일이름 # 파일 삭제
$ gsutil ls -L gs://버킷이름/파일이름 # 파일 정보 보기
gsutil의 성능을 향상시키기 (-m 옵션)
Facebook의 Google Cloud Platform 커뮤니티 에서 알려줘서 추가로 업데이트 합니다
-m 옵션을 주게되면 처리가 Parallel 하게 처리가 되기 때문에 성능이 비약적으로 향상됩니다.
관련해서 자세한 문서는 Top-Level Command-Line Options 를 참고해주세요
-m을 지원하는 명령어들
$ gsutil -m acl ch [해당 명령어 관련 설정] # Access Control List 변경
$ gsutil -m acl set [해당 명령어 관련 설정] # Access Control List 세팅
$ gsutil -m cp [해당 명령어 관련 설정] # 복사
$ gsutil -m mv [해당 명령어 관련 설정] # 이동
$ gsutil -m rm [해당 명령어 관련 설정] # 삭제
$ gsutil -m rsync [해당 명령어 관련 설정] # 원본과 버킷 사이에 동기화
$ gsutil -m setmeta [해당 명령어 관련 설정] # 메타데이터 셋
명령어에 대한 자세한 설명은 gsutil Commands를 참고해주세요
Google Compute Engine
Google Compute Engine은 GCP의 대표적인 서비스로 인스턴스를 만들어 사용할 수 있도록 해주는 서비스 입니다.
아래와 같이 간단한 설정 만으로도 사용할 수 있는 서버를 만들 수 있습니다.
Google Cloud Console에 들어가서 메뉴 - Compute Engine을 선택합니다
아래와 같은 화면이 나오면 상단에 ‘인스턴스 만들기’를 선택합니다
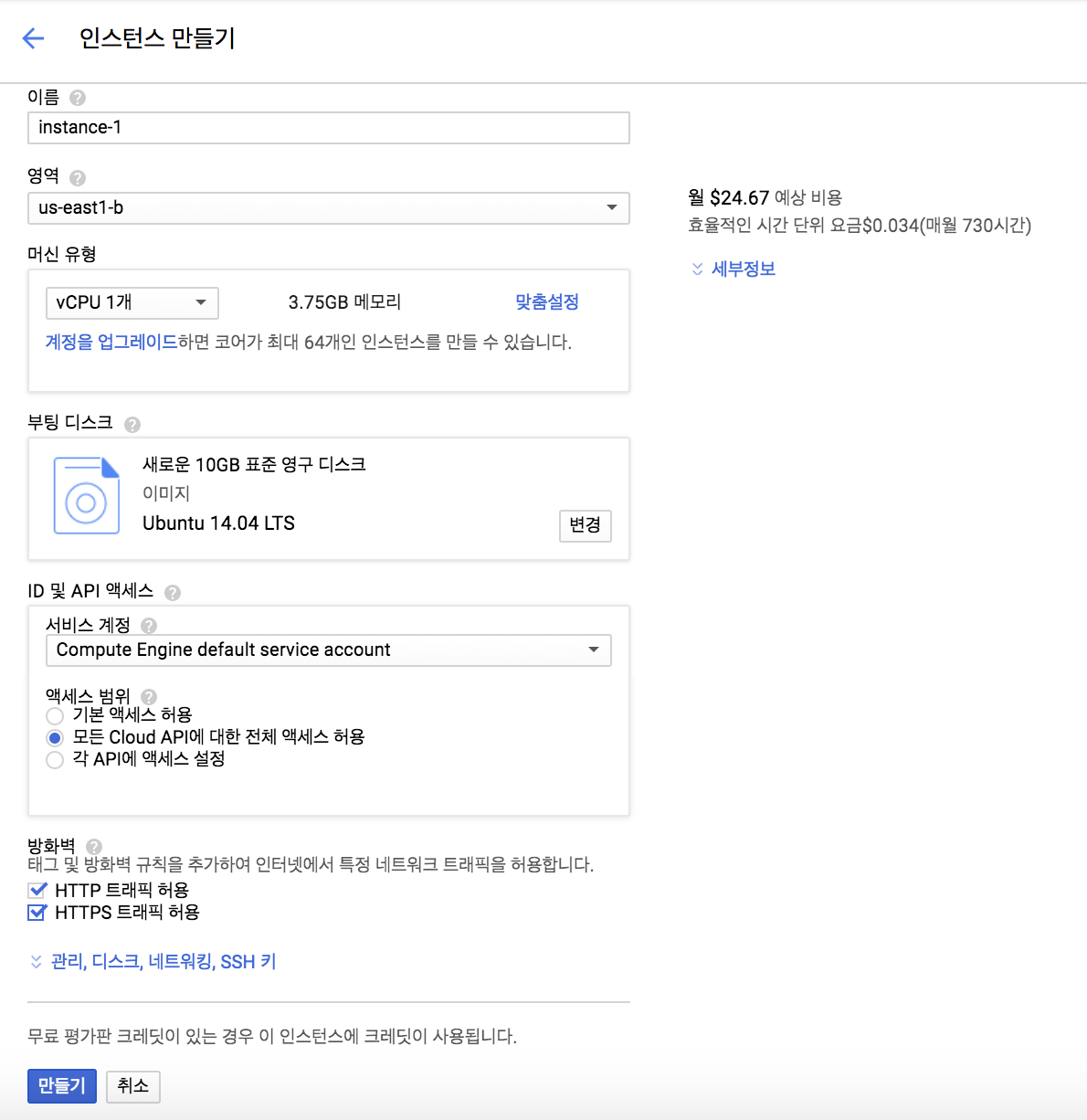
그럼 아래와 동일하게 설정을 하고 만들기를 누릅니다
중요하게 볼 부분은
- 부팅 디스크 : Ubuntu 14.04 LTS
- 액세스 범위 : 모든 Cloud API에 대한 전체 액세스 허용
- 방화벽 : HTTP 트래픽 허용, HTTPS 트래픽 허용
끝나면 아래와 같이 생성된 인스턴스를 확인할 수 있습니다
Google App Engine

구글의 App Engine은 Web Application을 만들 수 있는 툴 입니다. Web Application을 서비스하는데 필요한 모든 기능들을 제공합니다.
- Develop : App Engine SDK와 다양한 언어를 제공합니다. (Go, PHP, Java, Python, Node.js, .NET, Ruby …)
- Upload : 손 쉽게 개발된 소스를 업로드 할 수 있습니다.
- Scales & Reliably : 손 쉽게 스케일 아웃을 할 수 있습니다.
- Managing : 배포나 업데이트등의 관리를 손 쉽게 할 수 있도록 도와줍니다.
Google Dataproc

구글의 Dataproc은 하둡 에코시스템(Hadoop, Spark, Hive, Pig…)을 지원해주는 서비스 입니다.