CLOUD NATURAL LANGUAGE API는 구글 클라우드 환경에서 제공하는 자연어 분석기입니다. 무려 한글도 정식으로 지원이 되어서 이번에 사용해보면서 내용을 좀 정리해보려고 합니다.
따로 설정 필요없이 알아서 한글이면 한글로 분석 영어면 영어로 분석을 합니다 아주 똑똑한 녀석이네요
아래 실습 코드는 GoogleNLP 에 올려놨습니다
사전준비
해당 API를 쓰기 위해서는 아래 사전 세팅들을 필요로 합니다
Natural Language API 활성화 하기
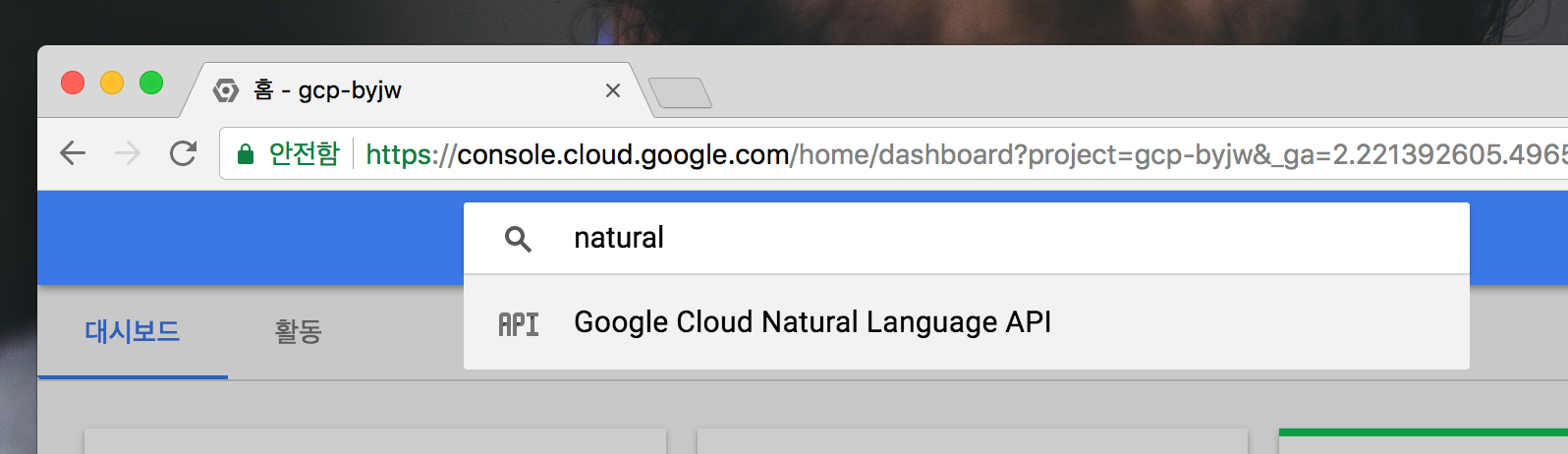
Google Cloud Console에 들어가서 natural을 검색하여 아래와 같이
Google Cloud Natural Language API를 클릭합니다
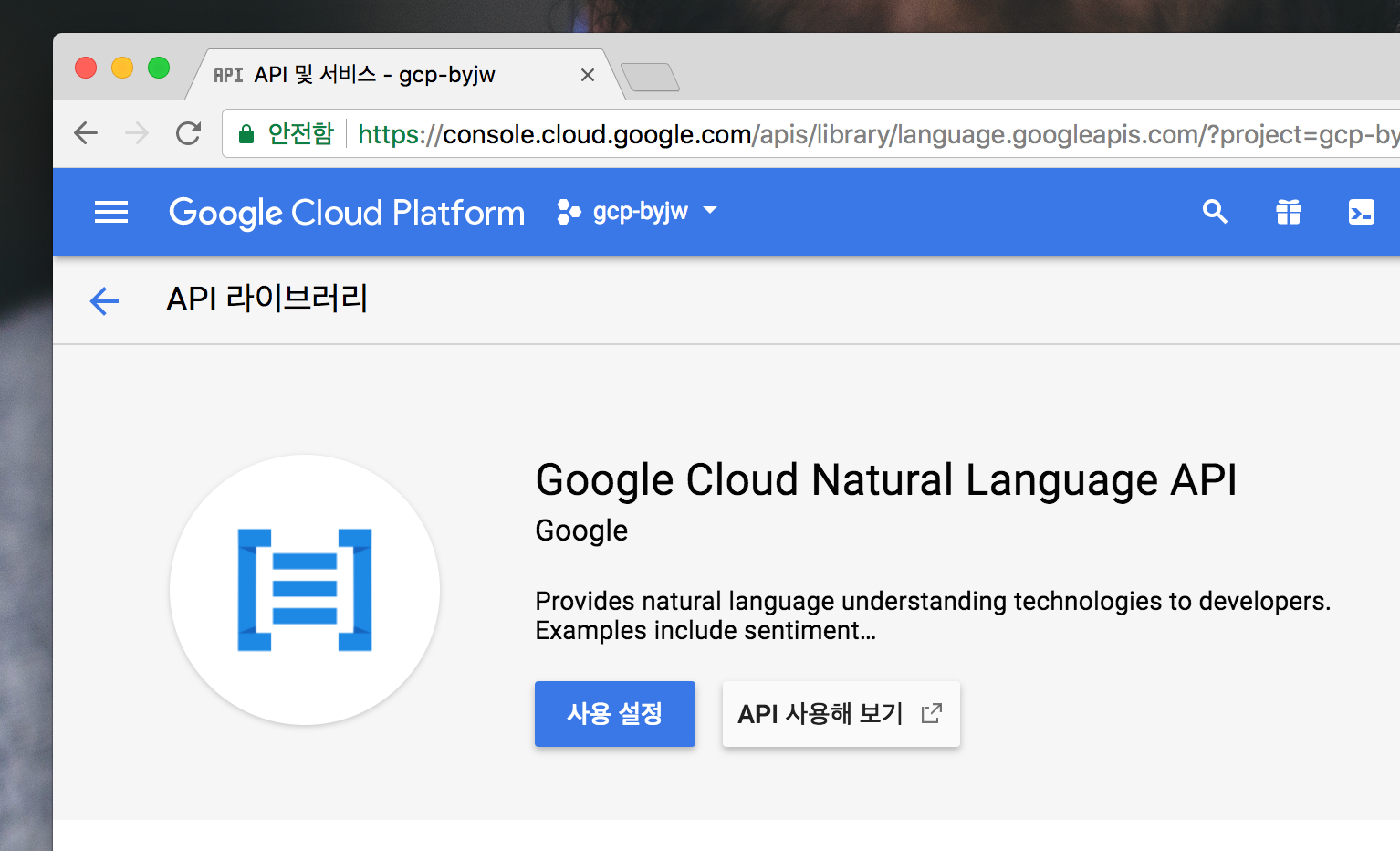
아래와 같은 화면이 나오면 사용 설정버튼을 눌러서 해당 API사용을 허용해줍니다
gcloud sdk 설치 후 인증받기
우선 Google Cloud SDK(=gcloud) 설치하기를 참고하여 gcloud 설치를 먼저 해줍니다
그 다음 gcloud auth login을 터미널에 입력을 해줍니다
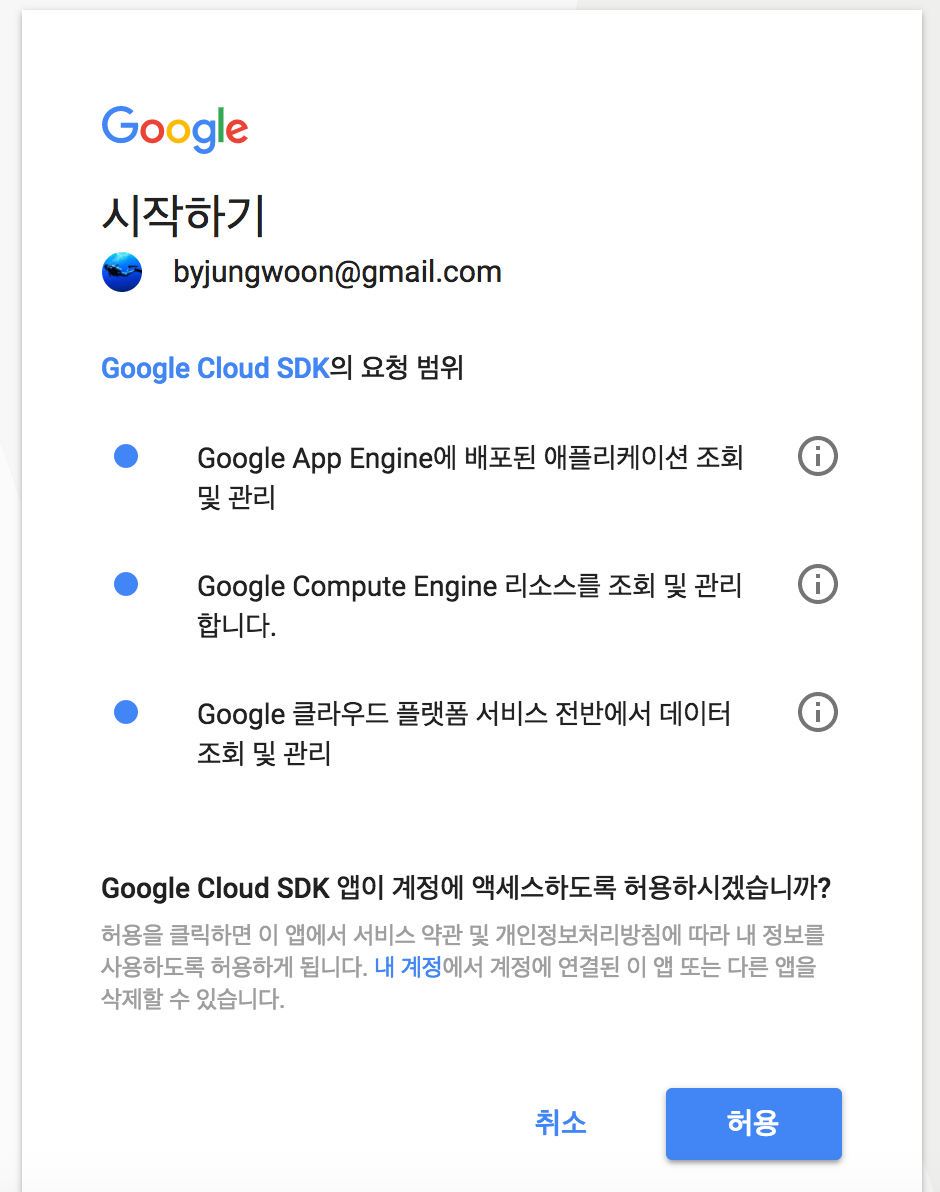
그럼 아래와 같이 브라우저가 뜨면서 구글 계정을 선택하는 화면이 나오는데, 해당 프로젝트 계정을 클릭합니다

그럼 다음과 같이 권한 요청이 나오는데, 허용을 누릅니다
서비스 계정키를 다운 받아서 .bashrc에 등록하기
GCP 서비스를 이용하기 위한 서비스 계정 키를 얻기 위해 Google Cloud Console에서
메뉴 - API 및 서비스 - 서비스 계정을 누릅니다
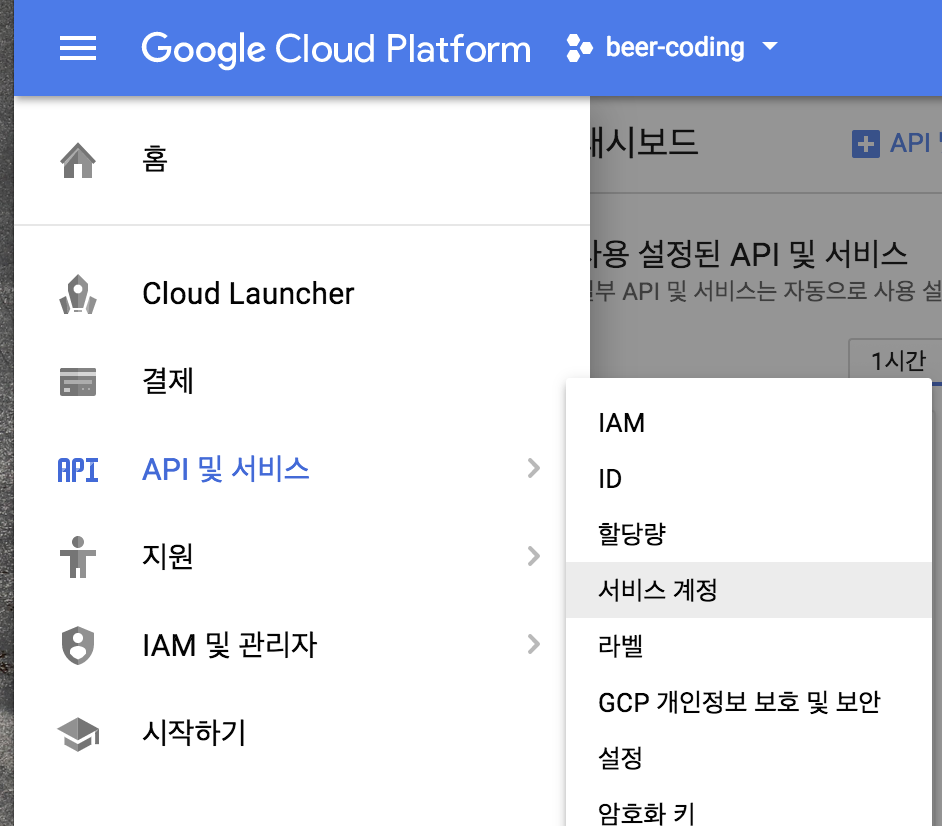
아래와 같이 나오면 우측에 메뉴를 누르고 키 만들기를 누릅니다

그럼 아래와 같이 JSON 또는 P12를 선택하라고 하는데 여기서는 JSON을 선택하고 생성 버튼을 누릅니다
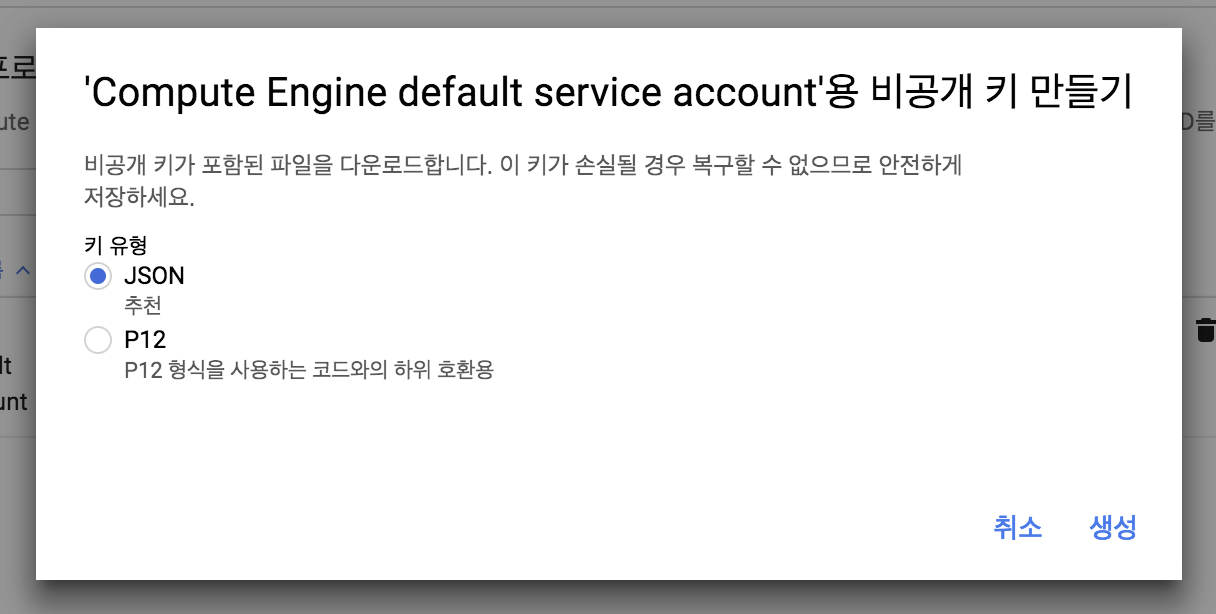
그럼 자동으로 Local로 다운로드 받아지게 됩니다
(한번밖에 다운로드 되지 않기 때문에 잘 보관해야 합니다)
그 다음 vi ~/.bashrc를 입력을 합니다. (다른 쉘을 쓰면 거기에 맞는걸 열어줍니다)
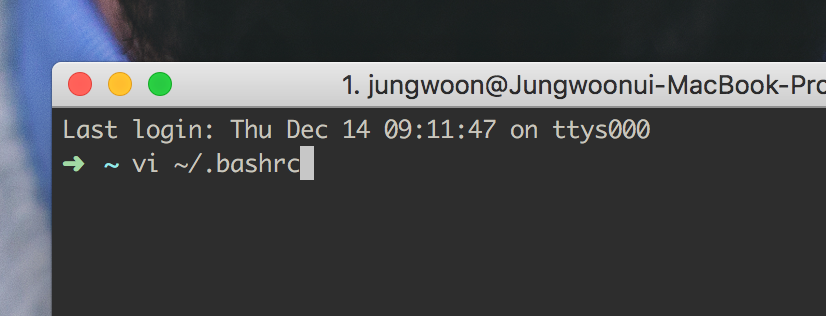
아래의 105번 라인과 같이 위에서 다운받은 서비스 계정 키의 경로를 GOOGLE_APPLICATION_CREDENTIALS에 넣어줍니다

## Google Cloud
export GOOGLE_CLOUD_SDK_PATH=/Users/jungwoon/google-cloud-sdk
export PATH=$PATH:$GOOGLE_CLOUD_SDK_PATH/bin
export GOOGLE_APPLICATION_CREDENTIALS=/Users/jungwoon/GoogleCredential/bigquerybyjw.json
지원하는 언어 (2017.11.16. 기준)
- Chinese (Simplified)
- Chinese (Traditional)
- English
- French
- German
- Italian
- Japanese
- Korean
- Portuguese
- Spanish
실습
JAVA로 개발을 하려면 Maven 기반에서 해야해서, Maven 프로젝트를 생성하고 pom.xml에 아래 코드를 추가합니다
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-language</artifactId>
<version>0.26.0-beta</version>
</dependency>
저의 pom.xml 환경 (테스트 코드 작성을 위해 junit과 hamcrest도 추가하였습니다)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.byjw</groupId>
<artifactId>com.byjw</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-language</artifactId>
<version>0.26.0-beta</version>
</dependency>
<!-- Hamcrest and JUnit are required dependencies of DataflowAssert,
which is used in the main code of DebuggingWordCount example. -->
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-all</artifactId>
<version>1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
</project>
NLAnalyze.class (전체소스 - 싱글톤)
정식으로 지원하는 기능이 Entity, Syntax, Sentiment 이므로 해당 클래스에 기능을 넣고 싱글톤 형태로 필요할때마다 불러서 사용하는 식으로
구성해봤습니다
package com.byjw.NLP;
import com.google.cloud.language.v1beta2.*;
import java.util.List;
public class NLAnalyze {
private static NLAnalyze instance = new NLAnalyze();
private static LanguageServiceClient languageServiceClient;
public static NLAnalyze getInstance() {
try {
languageServiceClient = LanguageServiceClient.create();
}
catch (Exception e) {
e.printStackTrace();
}
return instance;
}
public NLAnalyzeVO analyze(String text) {
NLAnalyzeVO nlAnalyzeVo = new NLAnalyzeVO();
List<Token> tokenList = analyzeSyntax(text);
for (Token token : tokenList) {
String tag = token.getPartOfSpeech().getTag().toString();
String content = token.getText().getContent();
if (tag.equals("NOUN")) nlAnalyzeVo.addNouns(content);
else if (tag.equals("ADJ")) nlAnalyzeVo.addAdjs(content);
}
return nlAnalyzeVo;
}
public List<Entity> analyzeEntities(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeEntitiesRequest request = AnalyzeEntitiesRequest.newBuilder()
.setDocument(document)
.setEncodingType(EncodingType.UTF16)
.build();
AnalyzeEntitiesResponse response = languageServiceClient.analyzeEntities(request);
return response.getEntitiesList();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
public Sentiment analyzeSentiment(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeSentimentResponse response = languageServiceClient.analyzeSentiment(document);
return response.getDocumentSentiment();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
public List<Token> analyzeSyntax(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeSyntaxRequest request = AnalyzeSyntaxRequest.newBuilder()
.setDocument(document)
.setEncodingType(EncodingType.UTF16)
.build();
AnalyzeSyntaxResponse response = languageServiceClient.analyzeSyntax(request);
return response.getTokensList();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
LanuageServiceClient 인스턴스 만들기
LanguageServiceClient의 인스턴스를 만들어서 사용하기 때문에 만들도록 하겠습니다 IOException 처리를 해줘야 하기 때문에 예외 처리를 해줬습니다
try {
languageServiceClient = LanguageServiceClient.create();
}
catch (Exception e) {
e.printStackTrace();
}
Document 인스턴스 만들기
항상 Document의 인스턴스로 API에 전달을 해줘야 하기 때문에 아래와 같이 만들었습니다
분석하고자 하는 text는 setContent()에 넣으면 됩니다
만약 GCS에 있는 문서를 분석하고 싶으면 setGcsContentUri()에 gcsUri(gs://bucket/file) 형태로 넣어주면 됩니다
// text를 분석하기
Document document = Document.newBuilder()
.setContent(text)
.setType(Document.Type.PLAIN_TEXT).build();
// GCS에서 파일을 읽어서 분석하기
Document document = Document.newBuilder()
.setGcsContentUri("gs://my-project/helloworld.txt")
.setType(Document.Type.PLAIN_TEXT).build();
Entities 분석
Entities의 결과는 List
자세하게 알고 싶으신 분은 Entity를 참고하시기 바랍니다
Entity
- name : 대상 텍스트
- type
- UNKNOWN : 알수 없음
- PERSON : 사람
- LOCATION : 위치
- ORGANIZATION : 기관
- EVENT : 이벤트
- WORK_OF_ART : 미술품
- CONSUMER_GOOD : 소비재
- OTHER : 그 외
- metadata : 해당 키워드가 위키에 있으면 찾아서 반환해줍니다
- salience : 중요도를 나타내며 0~1의 숫자로 1에 가까울수록 중요하고, 0에 가까울수록 덜 중요합니다
- mentions[]
- setiment
public List<Entity> analyzeEntities(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeEntitiesRequest request = AnalyzeEntitiesRequest.newBuilder()
.setDocument(document)
.setEncodingType(EncodingType.UTF16)
.build();
AnalyzeEntitiesResponse response = languageServiceClient.analyzeEntities(request);
return response.getEntitiesList();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
테스트 코드
private String text = "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.
Sundar Pichai said in his keynote that users love their new Android phones.";
@Test
public void test_nlp_get_entities() {
List<Entity> entityList = NLAnalyze.getInstance().analyzeEntities(text);
System.out.println("\n\n========== Entities ==========\n\n");
for (Entity entity : entityList) {
for (EntityMention mention : entity.getMentionsList()) {
System.out.printf("Content: %s\n", mention.getText().getContent());
System.out.printf("Begin offset: %d\n", mention.getText().getBeginOffset());
System.out.printf("Type: %s\n", mention.getType());
}
System.out.printf("Entity: %s\n", entity.getName());
System.out.printf("Salience: %.3f\n", entity.getSalience());
System.out.println("Metadata: ");
for (Map.Entry<String, String> entry : entity.getMetadataMap().entrySet()) {
System.out.printf("%s : %s", entry.getKey(), entry.getValue());
}
System.out.println("\n\n-------------------\n\n");
}
}
테스트 코드 결과
========== Entities ==========
Content: Google
Begin offset: 4
Type: PROPER
Entity: Google
Salience: 0.259
Metadata:
mid : /m/045c7bwikipedia_url : https://en.wikipedia.org/wiki/Google
-------------------
Content: users
Begin offset: 148
Type: COMMON
Entity: users
Salience: 0.149
Metadata:
-------------------
Content: phone
Begin offset: 69
Type: COMMON
Entity: phone
Salience: 0.133
Metadata:
-------------------
Content: Android
Begin offset: 61
Type: PROPER
Content: Android
Begin offset: 169
Type: PROPER
Entity: Android
Salience: 0.125
Metadata:
mid : /m/02wxtgwwikipedia_url : https://en.wikipedia.org/wiki/Android_(operating_system)
-------------------
Content: Sundar Pichai
Begin offset: 109
Type: PROPER
Entity: Sundar Pichai
Salience: 0.115
Metadata:
mid : /m/09gds74wikipedia_url : https://en.wikipedia.org/wiki/Sundar_Pichai
-------------------
Content: Mountain View
Begin offset: 29
Type: PROPER
Entity: Mountain View
Salience: 0.104
Metadata:
wikipedia_url : https://en.wikipedia.org/wiki/Mountain_View,_Californiamid : /m/0r6c4
-------------------
Content: Consumer Electronic Show
Begin offset: 82
Type: PROPER
Entity: Consumer Electronic Show
Salience: 0.065
Metadata:
mid : /m/01p15wwikipedia_url : https://en.wikipedia.org/wiki/Consumer_Electronics_Show
-------------------
Content: phones
Begin offset: 177
Type: COMMON
Entity: phones
Salience: 0.033
Metadata:
-------------------
Content: keynote
Begin offset: 135
Type: COMMON
Entity: keynote
Salience: 0.017
Metadata:
-------------------
Syntax 분석
Syntax의 결과는 List
자세한 정보는 Token 여기서 확인하실 수 있습니다
(일단 자주 쓸만한 기능만 정리해놓도록 하겠습니다... 한글로 번역해봐도 뭔지 모르겠네요, 자세하게 알고 싶으시면 위의 링크를 참조 하세요)
기능
- text
- getText() : 현재 분석하고 있는 텍스트 가져오기
- getContent() : 현재 텍스트 시작 위치 가져오기
- partOfSpeech
- tag (품사의 형태를 가져옴)
- UNKNOWN : 알수 없음 (Unknown)
- ADJ : 형용사 (Adjective)
- ADP : 전치사 + 후치사 (Adposition (preposition and postposition))
- ADV : 부사 (Adverb)
- CONJ : 접속사 (Conjunction)
- DET : 한정사 (Determiner)
- NOUN : 명사 (Noun (common and proper))
- NUM : 숫자 (Cardinal number)
- PRON : 대명사 (Pronoun)
- PRT : 조각 또는 다른 기능의 단어 (Particle or other function word)
- PUNCT : 구두점 (Punctuation)
- VERB : 동사 (Verb (all tenses and modes))
- X : 그 외(외래어, 오타, 약어) (Other: foreign words, typos, abbreviations)
- AFFIX : 접사(접두사, 접미사) (Affix)
- aspect
- case
- form
- gender
- mood
- number
- person
- proper
- reciprocity
- tense
- voice
- tag (품사의 형태를 가져옴)
- dependencyEdge
- lemma
getTag()를 통해서 가져올 수 있는 부분은 아래와 같습니다
public List<Token> analyzeSyntax(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeSyntaxRequest request = AnalyzeSyntaxRequest.newBuilder()
.setDocument(document)
.setEncodingType(EncodingType.UTF16)
.build();
AnalyzeSyntaxResponse response = languageServiceClient.analyzeSyntax(request);
return response.getTokensList();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
테스트 코드
private String text = "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.
Sundar Pichai said in his keynote that users love their new Android phones.";
@Test
public void test_nlp_get_syntax() {
List<Token> tokenList = NLAnalyze.getInstance().analyzeSyntax(text);
System.out.println("\n\n========== Syntax ==========\n\n");
for (Token token : tokenList) {
System.out.printf("\tText: %s\n", token.getText().getContent());
System.out.printf("\tBeginOffset: %d\n", token.getText().getBeginOffset());
System.out.println("\n-------------------\n");
System.out.printf("Lemma: %s\n", token.getLemma());
System.out.println("\n-------------------\n");
System.out.printf("PartOfSpeechTag: %s\n", token.getPartOfSpeech().getTag());
System.out.printf("\tAspect: %s\n", token.getPartOfSpeech().getAspect());
System.out.printf("\tCase: %s\n", token.getPartOfSpeech().getCase());
System.out.printf("\tForm: %s\n", token.getPartOfSpeech().getForm());
System.out.printf("\tGender: %s\n", token.getPartOfSpeech().getGender());
System.out.printf("\tMood: %s\n", token.getPartOfSpeech().getMood());
System.out.printf("\tNumber: %s\n", token.getPartOfSpeech().getNumber());
System.out.printf("\tPerson: %s\n", token.getPartOfSpeech().getPerson());
System.out.printf("\tProper: %s\n", token.getPartOfSpeech().getProper());
System.out.printf("\tReciprocity: %s\n", token.getPartOfSpeech().getReciprocity());
System.out.printf("\tTense: %s\n", token.getPartOfSpeech().getTense());
System.out.printf("\tVoice: %s\n", token.getPartOfSpeech().getVoice());
System.out.println("\n-------------------\n");
System.out.println("DependencyEdge");
System.out.printf("\tHeadTokenIndex: %d\n", token.getDependencyEdge().getHeadTokenIndex());
System.out.printf("\tLabel: %s\n\n", token.getDependencyEdge().getLabel());
}
}
테스트 코드 결과
========== Syntax ==========
Text: Google
BeginOffset: 0
-------------------
Lemma: Google
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 7
Label: NSUBJ
Text: ,
BeginOffset: 6
-------------------
Lemma: ,
-------------------
PartOfSpeechTag: PUNCT
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 0
Label: P
Text: headquartered
BeginOffset: 8
-------------------
Lemma: headquarter
-------------------
PartOfSpeechTag: VERB
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: PAST
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 0
Label: VMOD
Text: in
BeginOffset: 22
-------------------
Lemma: in
-------------------
PartOfSpeechTag: ADP
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 2
Label: PREP
Text: Mountain
BeginOffset: 25
-------------------
Lemma: Mountain
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 5
Label: NN
Text: View
BeginOffset: 34
-------------------
Lemma: View
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 3
Label: POBJ
Text: ,
BeginOffset: 38
-------------------
Lemma: ,
-------------------
PartOfSpeechTag: PUNCT
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 0
Label: P
Text: unveiled
BeginOffset: 40
-------------------
Lemma: unveil
-------------------
PartOfSpeechTag: VERB
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: INDICATIVE
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: PAST
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 7
Label: ROOT
Text: the
BeginOffset: 49
-------------------
Lemma: the
-------------------
PartOfSpeechTag: DET
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 11
Label: DET
Text: new
BeginOffset: 53
-------------------
Lemma: new
-------------------
PartOfSpeechTag: ADJ
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 11
Label: AMOD
Text: Android
BeginOffset: 57
-------------------
Lemma: Android
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 11
Label: NN
Text: phone
BeginOffset: 65
-------------------
Lemma: phone
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 7
Label: DOBJ
Text: at
BeginOffset: 71
-------------------
Lemma: at
-------------------
PartOfSpeechTag: ADP
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 7
Label: PREP
Text: the
BeginOffset: 74
-------------------
Lemma: the
-------------------
PartOfSpeechTag: DET
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 16
Label: DET
Text: Consumer
BeginOffset: 78
-------------------
Lemma: Consumer
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 15
Label: NN
Text: Electronic
BeginOffset: 87
-------------------
Lemma: Electronic
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 16
Label: NN
Text: Show
BeginOffset: 98
-------------------
Lemma: Show
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 12
Label: POBJ
Text: .
BeginOffset: 102
-------------------
Lemma: .
-------------------
PartOfSpeechTag: PUNCT
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 7
Label: P
Text: Sundar
BeginOffset: 105
-------------------
Lemma: Sundar
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 19
Label: NN
Text: Pichai
BeginOffset: 112
-------------------
Lemma: Pichai
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 20
Label: NSUBJ
Text: said
BeginOffset: 119
-------------------
Lemma: say
-------------------
PartOfSpeechTag: VERB
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: INDICATIVE
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: PAST
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 20
Label: ROOT
Text: in
BeginOffset: 124
-------------------
Lemma: in
-------------------
PartOfSpeechTag: ADP
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 20
Label: PREP
Text: his
BeginOffset: 127
-------------------
Lemma: his
-------------------
PartOfSpeechTag: PRON
Aspect: ASPECT_UNKNOWN
Case: GENITIVE
Form: FORM_UNKNOWN
Gender: MASCULINE
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: THIRD
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 23
Label: POSS
Text: keynote
BeginOffset: 131
-------------------
Lemma: keynote
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 21
Label: POBJ
Text: that
BeginOffset: 139
-------------------
Lemma: that
-------------------
PartOfSpeechTag: ADP
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 26
Label: MARK
Text: users
BeginOffset: 144
-------------------
Lemma: user
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: PLURAL
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 26
Label: NSUBJ
Text: love
BeginOffset: 150
-------------------
Lemma: love
-------------------
PartOfSpeechTag: VERB
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: INDICATIVE
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: PRESENT
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 20
Label: CCOMP
Text: their
BeginOffset: 155
-------------------
Lemma: their
-------------------
PartOfSpeechTag: PRON
Aspect: ASPECT_UNKNOWN
Case: GENITIVE
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: PLURAL
Person: THIRD
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 30
Label: POSS
Text: new
BeginOffset: 161
-------------------
Lemma: new
-------------------
PartOfSpeechTag: ADJ
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 30
Label: AMOD
Text: Android
BeginOffset: 165
-------------------
Lemma: Android
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: SINGULAR
Person: PERSON_UNKNOWN
Proper: PROPER
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 30
Label: NN
Text: phones
BeginOffset: 173
-------------------
Lemma: phone
-------------------
PartOfSpeechTag: NOUN
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: PLURAL
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 26
Label: DOBJ
Text: .
BeginOffset: 179
-------------------
Lemma: .
-------------------
PartOfSpeechTag: PUNCT
Aspect: ASPECT_UNKNOWN
Case: CASE_UNKNOWN
Form: FORM_UNKNOWN
Gender: GENDER_UNKNOWN
Mood: MOOD_UNKNOWN
Number: NUMBER_UNKNOWN
Person: PERSON_UNKNOWN
Proper: PROPER_UNKNOWN
Reciprocity: RECIPROCITY_UNKNOWN
Tense: TENSE_UNKNOWN
Voice: VOICE_UNKNOWN
-------------------
DependencyEdge
HeadTokenIndex: 20
Label: P
Sentiment 분석
Sentiment 현태로 반환을 하며, 분석하는 단어의 성격(긍정적 / 부정적)을 분석해서 숫자로 나타내 줍니다
자세하고 알고 싶은 부분이 있으면 Sentiment
- magnitude : 절대값으로 나타내며 0 ~ +inf 로 나타냅니다
- score : -1 (부정적) ~ 1 (긍정적)
public Sentiment analyzeSentiment(String text) {
try {
Document document = Document.newBuilder().setContent(text).setType(Document.Type.PLAIN_TEXT).build();
AnalyzeSentimentResponse response = languageServiceClient.analyzeSentiment(document);
return response.getDocumentSentiment();
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
테스트 소스
@Test
public void test_nlp_get_sentiment() {
Sentiment sentiment = NLAnalyze.getInstance().analyzeSentiment(text);
System.out.println("\n\n========== Sentiment ==========\n\n");
System.out.println("getMagnitude() : " + sentiment.getMagnitude());
System.out.println("getScore() : " + sentiment.getScore());
}
결과
========== Sentiment ==========
getMagnitude() : 0.6
getScore() : 0.3