Dataflow는 구글의스트림 및 배치 데이터 처리를 위한 솔루션입니다
사전 세팅
아래 명령을 통해서, 현재 프로젝트 계정과 연결을 시켜줍니다
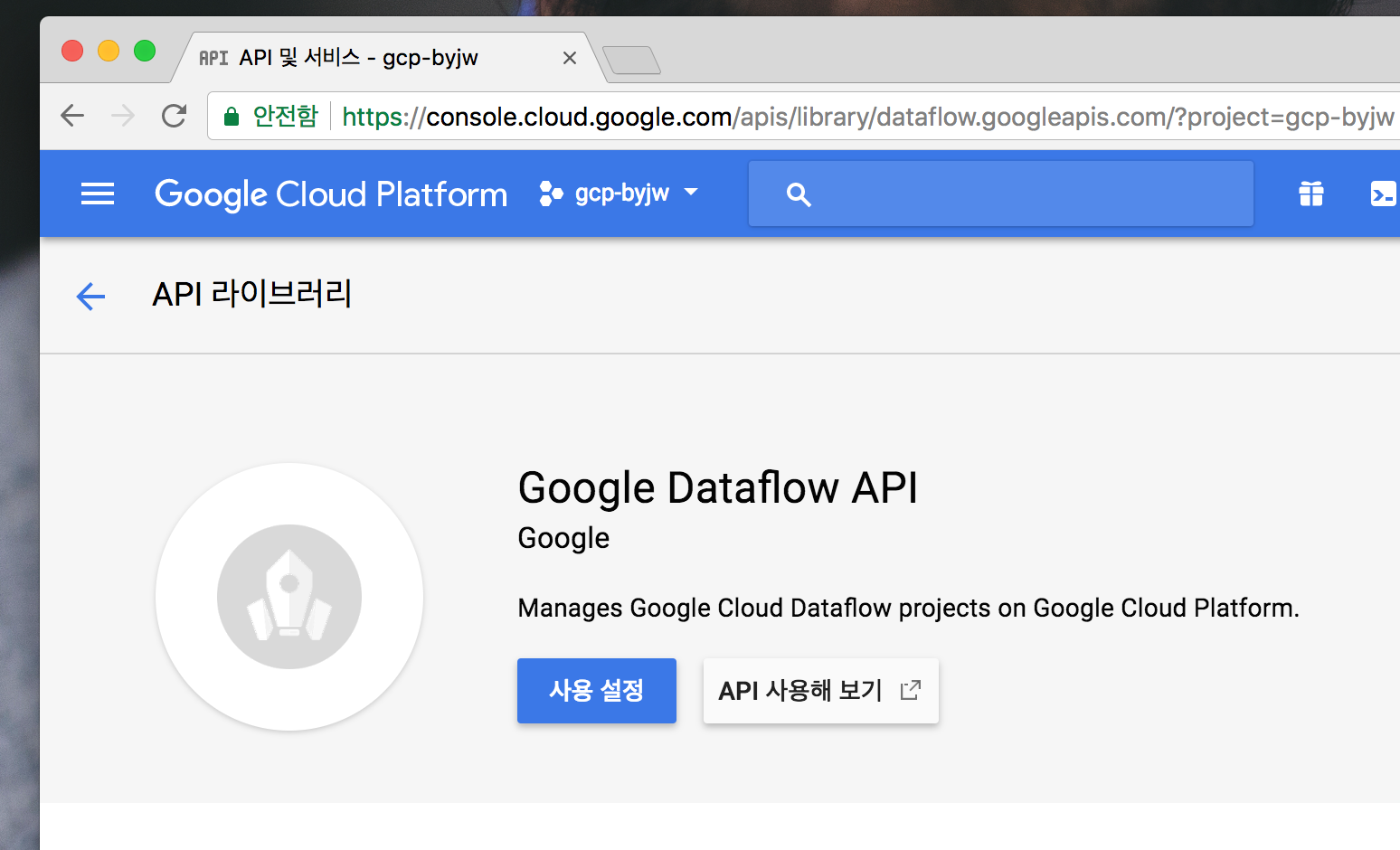
Dataflow API 활성화 해주기
Google Cloud Console에서 Dataflow를 사용할 수 있도록 API 사용설정을 해줍니다
구글 클라우드 콘솔에서 검색창에 dataflow를 검색한뒤 Google Dataflow API를 누릅니다
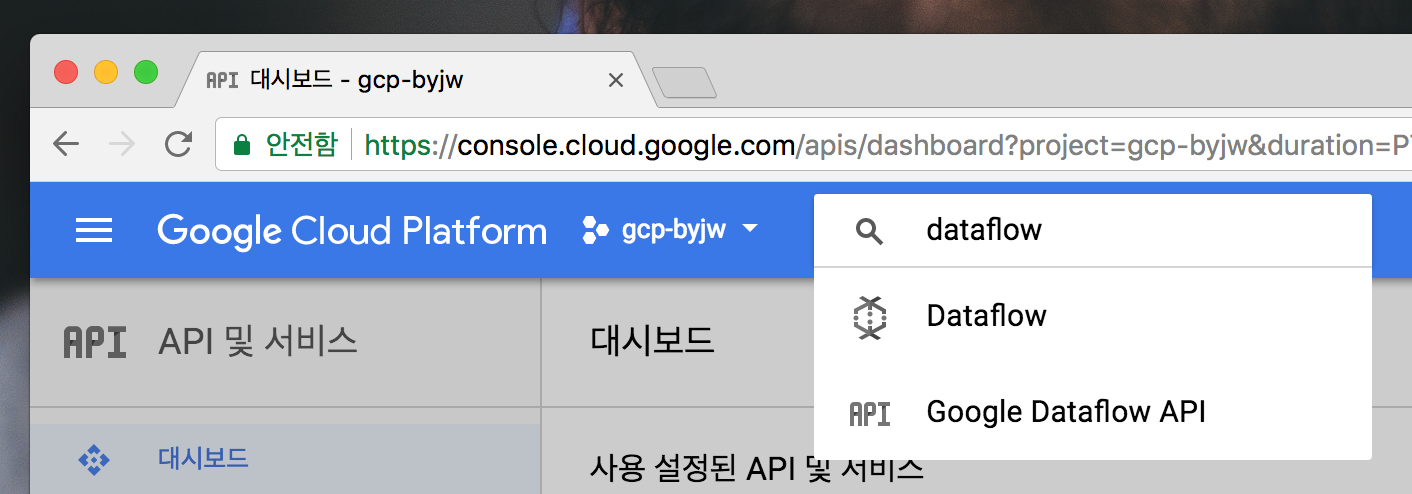
아래와 같이 나오면 사용 설정버튼을 눌러서 사용할 수 있도록 사용 설정 해줍니다
gcloud sdk 설치 후 인증받기
우선 Google Cloud SDK(=gcloud) 설치하기를 참고하여 gcloud 설치를 먼저 해줍니다
그 다음 gcloud auth login을 터미널에 입력을 해줍니다
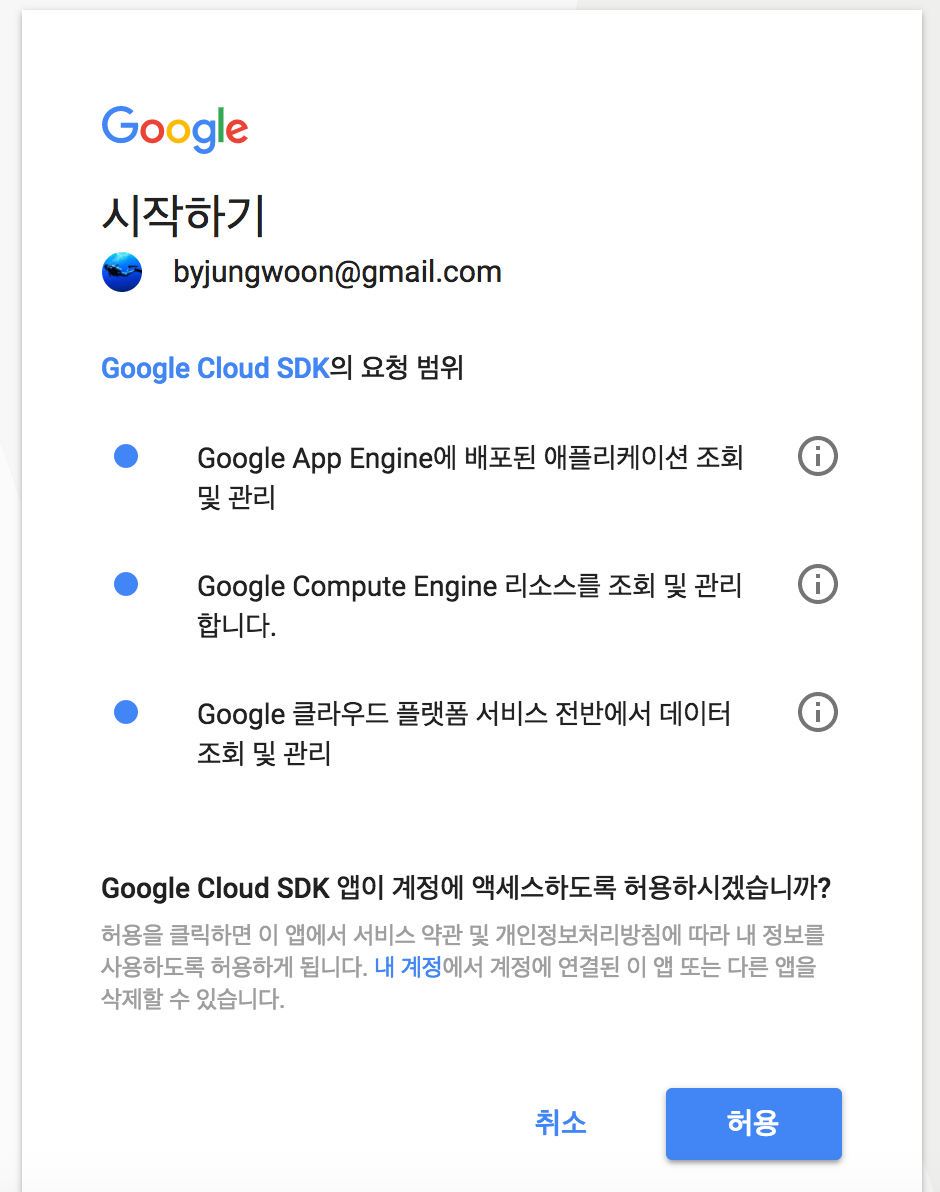
그럼 아래와 같이 브라우저가 뜨면서 구글 계정을 선택하는 화면이 나오는데, 해당 프로젝트 계정을 클릭합니다

그럼 다음과 같이 권한 요청이 나오는데, 허용을 누릅니다
서비스 계정키를 다운 받아서 .bashrc에 등록하기 및 사용설정하기
GCP 서비스를 이용하기 위한 서비스 계정 키를 얻기 위해 Google Cloud Console에서
메뉴 - API 및 서비스 - 서비스 계정을 누릅니다
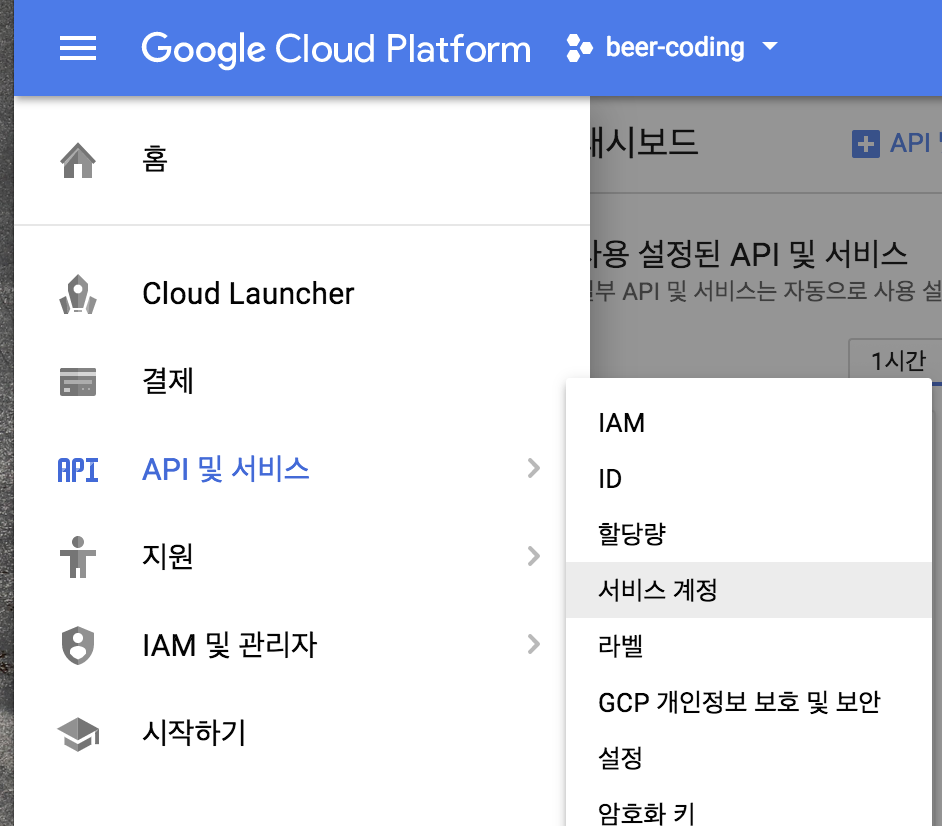
아래와 같이 나오면 우측에 메뉴를 누르고 키 만들기를 누릅니다

그럼 아래와 같이 JSON 또는 P12를 선택하라고 하는데 여기서는 JSON을 선택하고 생성 버튼을 누릅니다
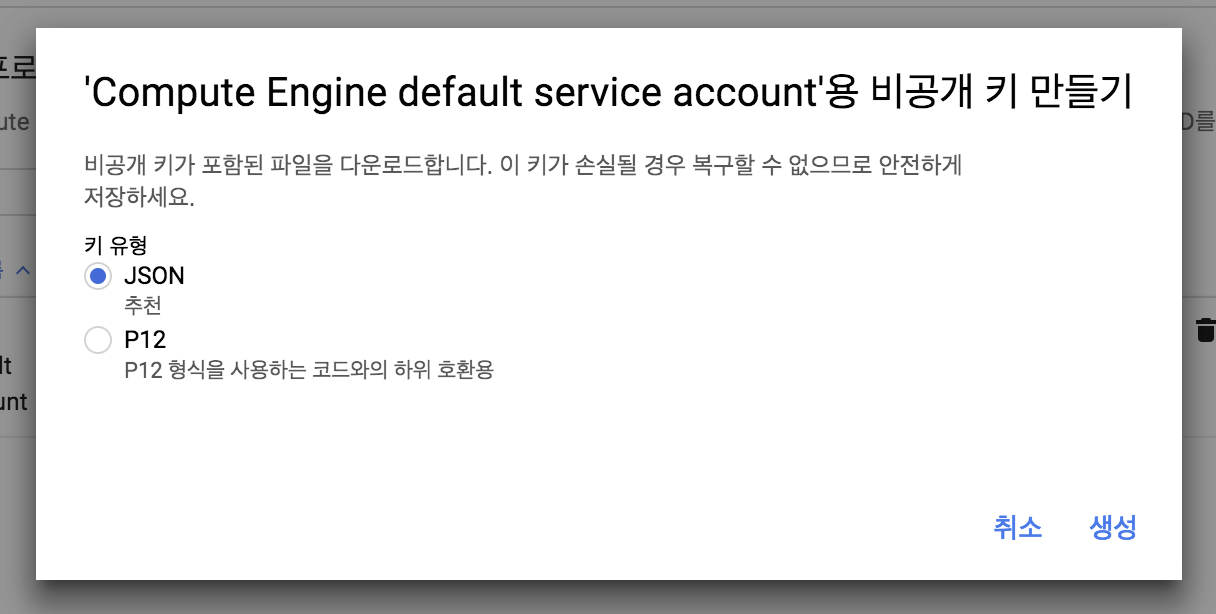
그럼 자동으로 Local로 다운로드 받아지게 됩니다
(한번밖에 다운로드 되지 않기 때문에 잘 보관해야 합니다)
그 다음 vi ~/.bashrc를 입력을 합니다. (다른 쉘을 쓰면 거기에 맞는걸 열어줍니다)
아래의 105번 라인과 같이 위에서 다운받은 서비스 계정 키의 경로를 GOOGLE_APPLICATION_CREDENTIALS에 넣어줍니다

## Google Cloud
export GOOGLE_CLOUD_SDK_PATH=/Users/jungwoon/google-cloud-sdk
export PATH=$PATH:$GOOGLE_CLOUD_SDK_PATH/bin
export GOOGLE_APPLICATION_CREDENTIALS=/Users/jungwoon/GoogleCredential/bigquerybyjw.json
그 다음 터미널에서 $ gcloud auth application-default login을 해주어야 합니다.
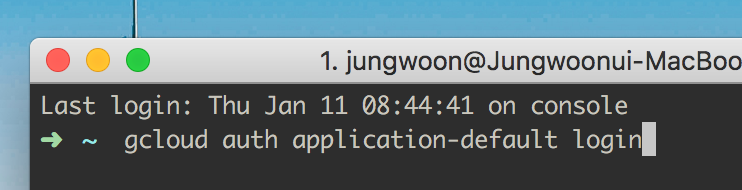
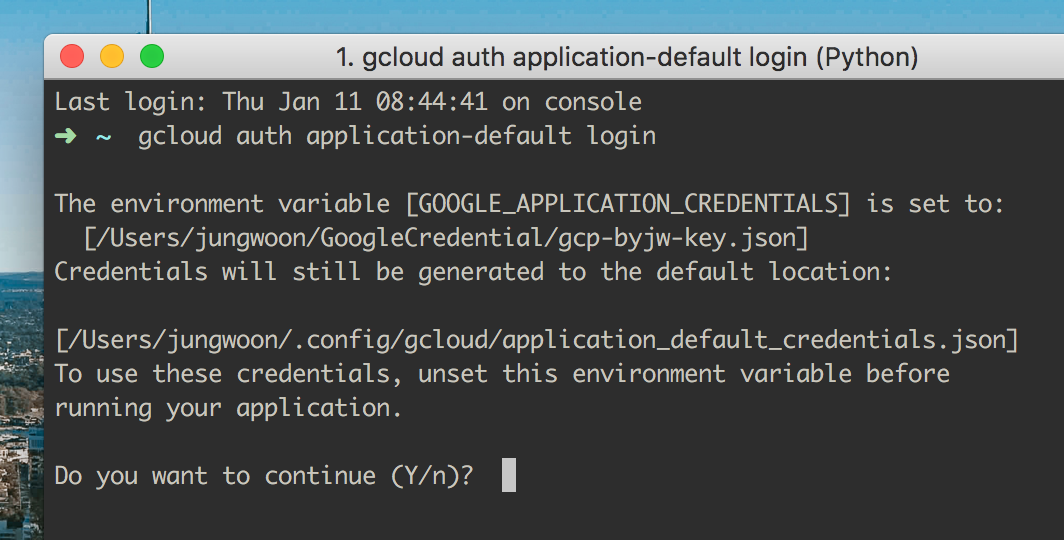
그럼 아래와 같이 나오는데 여기서 Y를 눌러서 진행을 합니다.
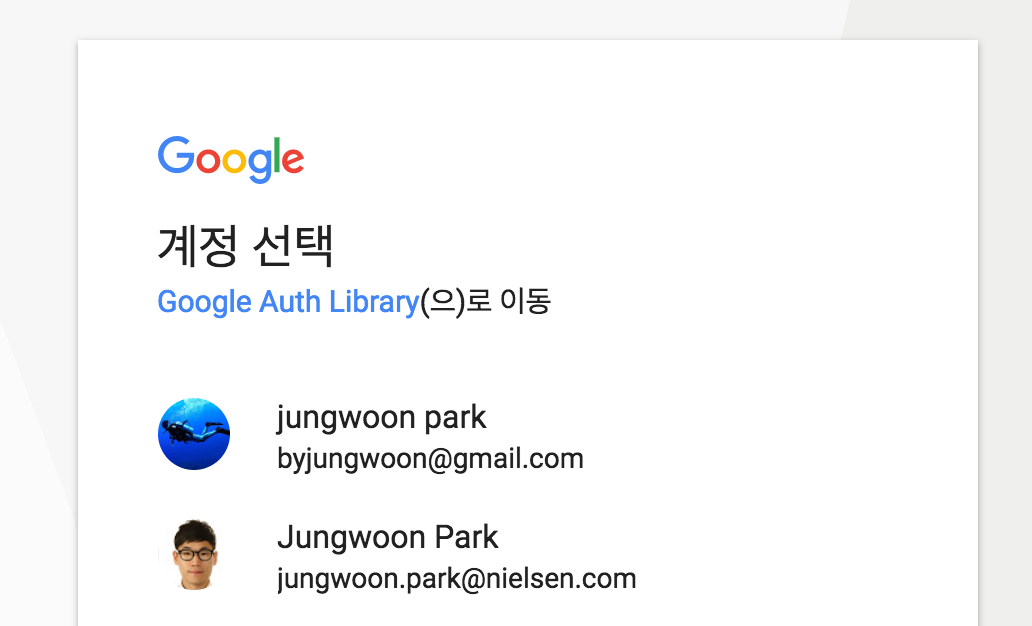
그 다음 브로우저가 열리면서 어떤 계정에 연결을 할건지에 대해서 나오는데, 연결하고자 하는 계정을 클릭합니다.
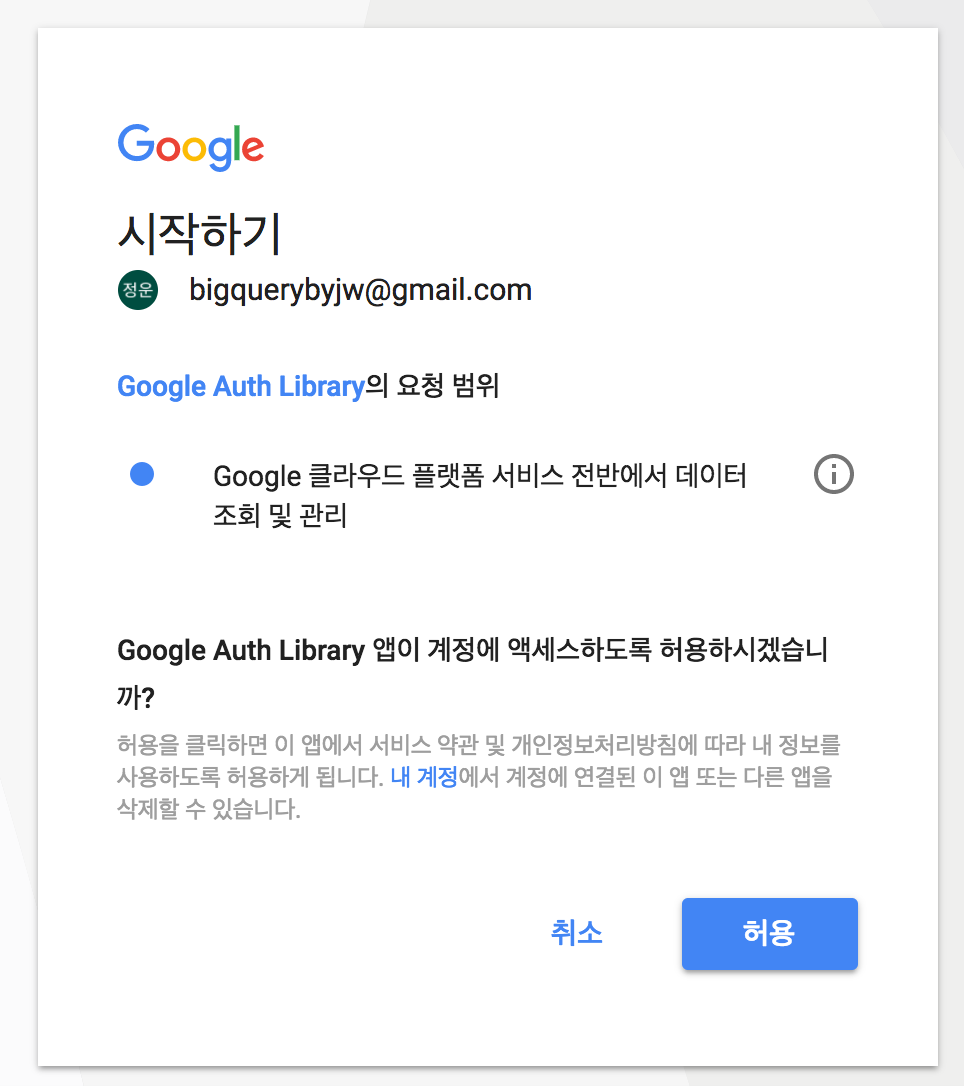
마지막으로 아래와 같은 화면에서 허용을 해주어야 사용할 수 있게 됩니다.
Dataflow Components
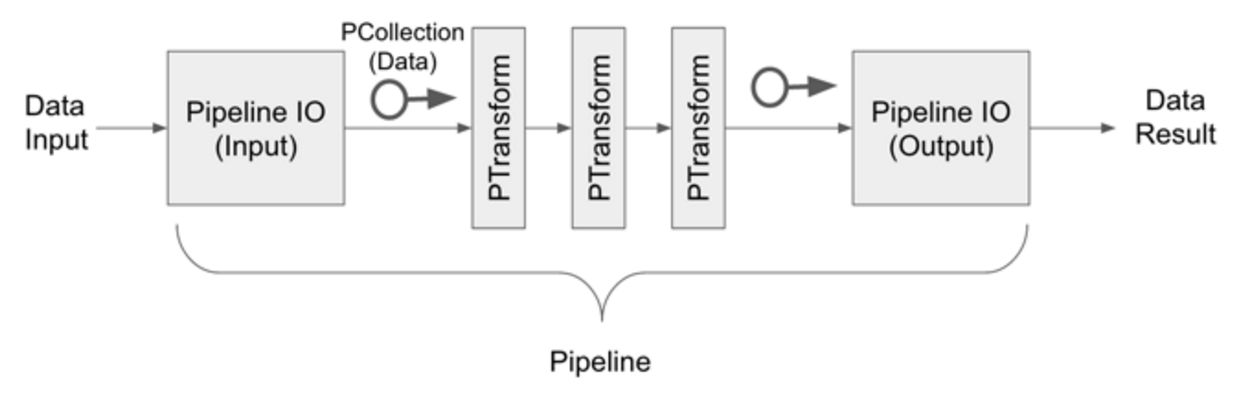
- Pipeline : 데이터 처리를 위한 큰 흐름
- Pipeline IO : 데이터의 I/O를 위한 부분
- PCollection : 데이터처리를 위한 데이터 형
- PTransform : 데이터의 변환 및 가공
Maven으로 Dataflow 적용하기
<dependencies>
<dependency>
<groupId>com.google.cloud.dataflow</groupId>
<artifactId>google-cloud-dataflow-java-sdk-all</artifactId>
<version>[1.9.1,1.99)</version>
</dependency>
<dependency>
<groupId>com.google.api-client</groupId>
<artifactId>google-api-client</artifactId>
<version>1.22.0</version>
<exclusions>
<!-- Exclude an old version of guava that is being pulled
in by a transitive dependency of google-api-client -->
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava-jdk5</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
Pipeline
데이터 처리를 위한 큰 흐름
PipelineOptions로 처리하는 방법
private final String PROJECT = "beer-coding";
private final String BUCKET = "gs://DataFlow-byjw";
DataflowPipelineOptions options = PipelineOptionsFactory.create().as(DataflowPipelineOptions.class);
options.setRunner(DataflowPipelineRunner.class);
options.setProject(PROJECT);
options.setStagingLocation(BUCKET);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
실행시 option에 대한 정보를 넣어주지 않아도 된다
$ mvn compile exec:java \
-Dexec.mainClass=com.byjw.dataflow.TwitterPipeline
Argument로 Option을 받아서 처리하는 방법
public static void main(String[] args) {
Pipeline pipeline = Pipeline.create(PipelineOptionsFactory.fromArgs(args).withValidation().create());
}
대신에 실행시 option에 대한 정보를 넣어줘야 한다
$ mvn compile exec:java \
-Dexec.mainClass=com.byjw.dataflow.TwitterPipeline \
-Dexec.args="--project=beer-coding \
--stagingLocation=gs://dataflow-byjw/staging/ \
--streaming \
--runner=DataflowPipelineRunner"
PipelineOptions
- Runner
- DirectPipelineRunner : 로컬에서 돌릴때 사용
- DataflowPipelineRunner : Cloud Dataflow 이용시 사용
- BlockingDataflowPipelineRunner : Cloud Dataflow 이용시 사용하지만 파이프라인이 기동되는 동안 프로그램이 실행중인걸로 되어서 프로그램(IntelliJ or Eclipse)에서 멈춰버리면 전체 파이프라인이 멈춰버리게 된다
- Project : Google Cloud Project ID
- StagingLocation : Google Cloud Storage의 Bucket 아이디를 넣어준다
- Streaming : 스트리밍 데이터 처리때 설정을 해 준다.
Pipeline IO
Dataflow와 직접 연결하여 데이터를 읽어올 수 있는 API들로, 자세한 내용은 Google Cloud Dataflow SDK for Java, version 1.9.1 를 참조하시기 바랍니다.
- AvroIO : Avro에서 데이터를 읽어오고 쓸 수 있음
- BigQueryIO : BigQuery에서 데이터를 읽어오고 쓸 수 있음
- DataStoreIO : DataStore에서 데이터를 읽어오고 쓸 수 있음
- PubSubIO : PubSub에서 데이터를 읽어오고 쓸 수 있음
- TextIO : GCS나 특정 경로로부터 텍스트 데이터를 읽어오고 쓸 수 있음
Element-Wise (Map + Reduce)
개별 데이터 엘리먼트를 단위로 연산하는것으로 ParDo 함수가 이에 해당하며 데이터를 받아서 처리한 후 출력을 하는것이 하나의 단위가 됩니다.
미리 DoFn을 상속한 클래스를 만들어서 사용해도 되고, 바로 ParDo 형태로 구현해서 사용해도 됩니다.
DoFn 클래스
DoFn으로 부터 상속된 클래스를 미리 만들어 놓는 형태
class MyFunction extends DoFn<{입력 데이타 타입},{출력 데이타 타입}> {
@Override
public void processElement(ProcessContext processContext) {
String result = processContext.element() // 입력 데이터 타입으로 정의된 입력 데이터를 꺼냄
processContext.output(result); // 파이프 라인상의 다음 컴포넌트로 데이터 전달
}
}
ParDo 메서드
DoFn을 ParDo안에다가 구현한 형태
Pipeline pipeline = Pipeline.create(PipelineOptionsFactory.fromArgs(args).withValidation().create());
pipeline.apply(ParDo.named("toUpper").of(new DoFn<String,String>() {
@Override
public void processElement(ProcessContext processContext) {
String result = processContext.element(); // 입력 데이터 타입으로 정의된 입력 데이터를 꺼냄
processContext.output(result); // 파이프 라인상의 다음 컴포넌트로 데이터 전달
}
}))
중요한 메서드
processContext.element() : 위에 흐름에서 전달받은 데이터를 가져옴
processContext.output(result) : 처리한 result를 다음 흐름으로 전
DoFn을 외부에 클래스로 상속받아서, ParDo메서드에서는 만들어진 클래스의 인스턴스를 생성해서 처리하는 형태
Pipeline pipeline = Pipeline.create(PipelineOptionsFactory.fromArgs(args).withValidation().create());
pipeline.apply(ParDo.named("toUpper").of(new UpperCase());
class UpperCase extends DoFn<String, String> {
@Override
public void processElement(ProcessContext processContext) {
processContext.output(processContext.element().toUpperCase());
}
}
Aggregation
특정 키 값을 이용하여 데이터를 그루핑하는 개념
Aggregation 기능
- Grouping : 특정 키별로 데이터를 묶어줌
- Combine : 특정 키별로 데이터를 연산함(합이나 평균)
Grouping
특정 키값을 이용하여 데이터를 그룹핑하는 개념
PCollection <KV<String, Iterable<Integer>>> groupedWords =
wordAndLines.apply(GroupByKey.<String,Integer> create());
Combine
PCollection <KV<String, Iterable<Integer>>> groupedWords =
wordAndLines.apply(GroupByKey.<String,Integer> create());
PCollection <KV<String, Integer>> sum = groupedWords.apply(Combine.globally(new Sum.SumIntegerFn)));
PCollection
PCollection은 데이터 플로 파이프라인 내에서 데이터를 저장하는 개념으로 한번 생성이 되면 그 데이터는 수정이 불가능하다
데이터를 변경하거나 수정하기 위해서는 PCollection을 새로 생성해야 한다
Window
스트리밍 데이터를 처리할때, 특히 Unbounded 데이터를 이용한 스트리밍 처리때 Grouping이나 Combine을 이용할때 반드시 사용해야 합니다
Fixed Window
PCollection<String> items = ...;
PCollection<String> fixed_windowed_items = items.apply(
Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES)));
Sliding Window
PCollection<String> items = ...;
PCollection<String> sliding_windowed_items = items.apply( Window.<String>into(SlidingWindows.of(Duration.standardMinutes(30)).every(Duration.standardSeconds(5))));
Session Window
세션 윈도우는 키별로 세션을 묶기 때문에 반드시 키가 필요하다
userEvents
.apply(Window.named("WindowIntoSessions")
.<KV<String, Integer>>into(
Sessions.withGapDuration(Duration.standardMinutes(Duration.standardMinutes(10))))
.withOutputTimeFn(OutputTimeFns.outputAtEndOfWindow()))
// For this use, we care only about the existence of the session, not any particular
// information aggregated over it, so the following is an efficient way to do that.
.apply(Combine.perKey(x -> 0))
// Get the duration per session.
.apply("UserSessionActivity", ParDo.of(new UserSessionInfoFn()))