BigQuery 데이터 로드시에 분할해서 로드하기 - #1 에서 빅쿼리 테이블 파티셔닝 하는 방법을 배웠는데요, 매번 날짜만 바꿔서 새로 *.yml 파일을 새로 만들어서 돌리는 작업이 번거로우니, 이번에는 쉘스크립트와 Rundeck을 이용하여 자동화를 해보려고 합니다.
크게 진행할 사항은 매번 사용하는 *.yml 에 대해서 template을 만들어 보고, 이를 원하는 값으로 변경하여 실행시킬, job.sh 라는 쉘 스크립트를 만들어 보도록 하겠습니다.
Template yml (cfg_transform.yml.template)
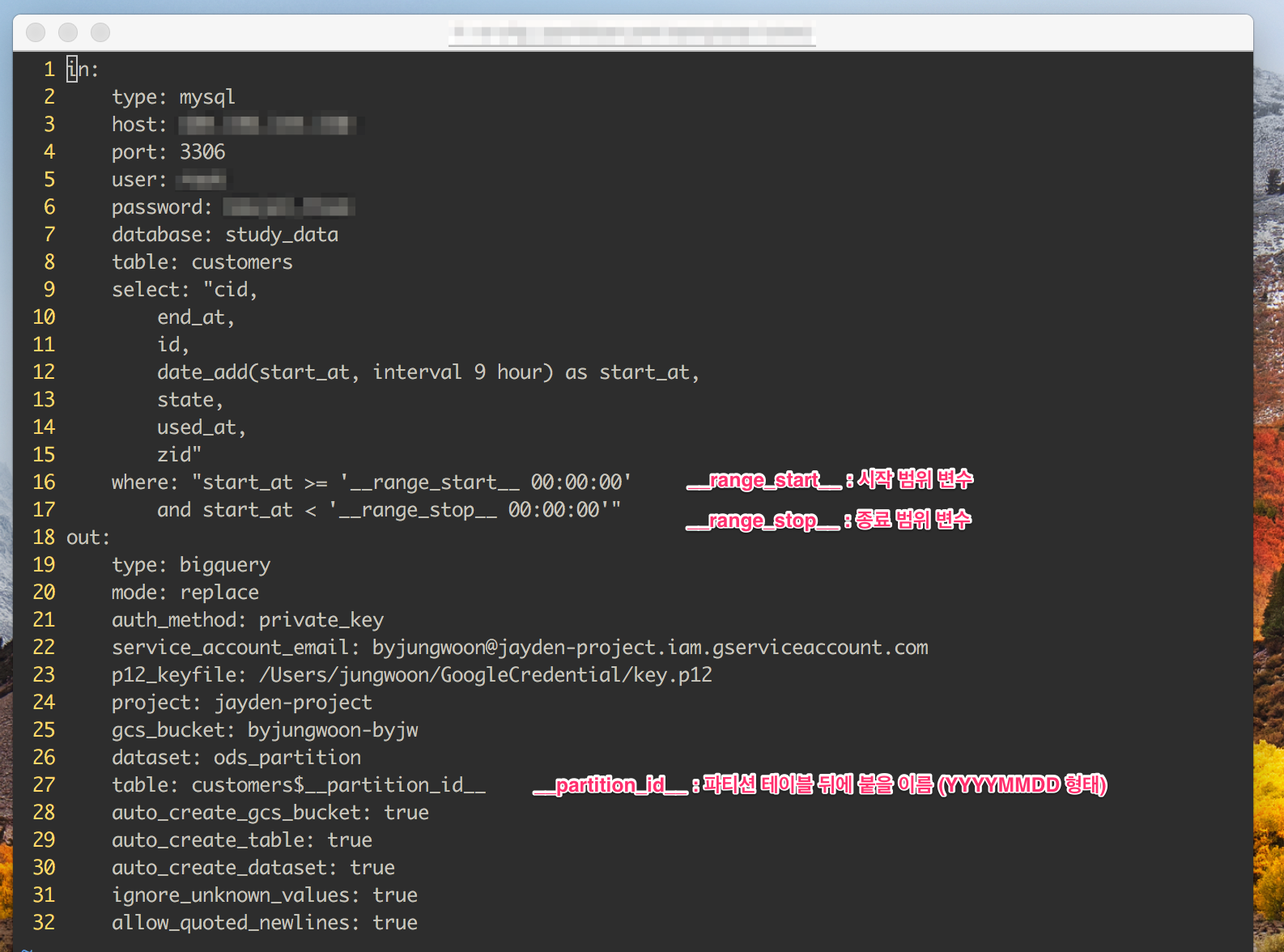
in:
type: mysql
host: 111.111.111.111
port: 3306
user: root # ID
password: root # PW
database: study_data
table: customers
select: "cid,
end_at,
id,
date_add(start_at, interval 9 hour) as start_at,
state,
used_at,
zid"
where: "start_at >= '__range_start__ 00:00:00' # __range_start__ : 범위 시작 변수
and start_at < '__range_stop__ 00:00:00'" # __range_stop__ : 범위 종료 변수
out:
type: bigquery
mode: replace
auth_method: private_key
service_account_email: byjungwoon@jayden-project.iam.gserviceaccount.com
p12_keyfile: /Users/jungwoon/GoogleCredential/key.p12
project: jayden-project
gcs_bucket: byjungwoon-byjw
dataset: ods_partition
table: customers$__partition_id__ #__partition_id : 파티션 테이블명 지정 (YYYYMMDD 형태)
auto_create_gcs_bucket: true
auto_create_table: true
auto_create_dataset: true
ignore_unknown_values: true
allow_quoted_newlines: true
Shell Script (job.sh)
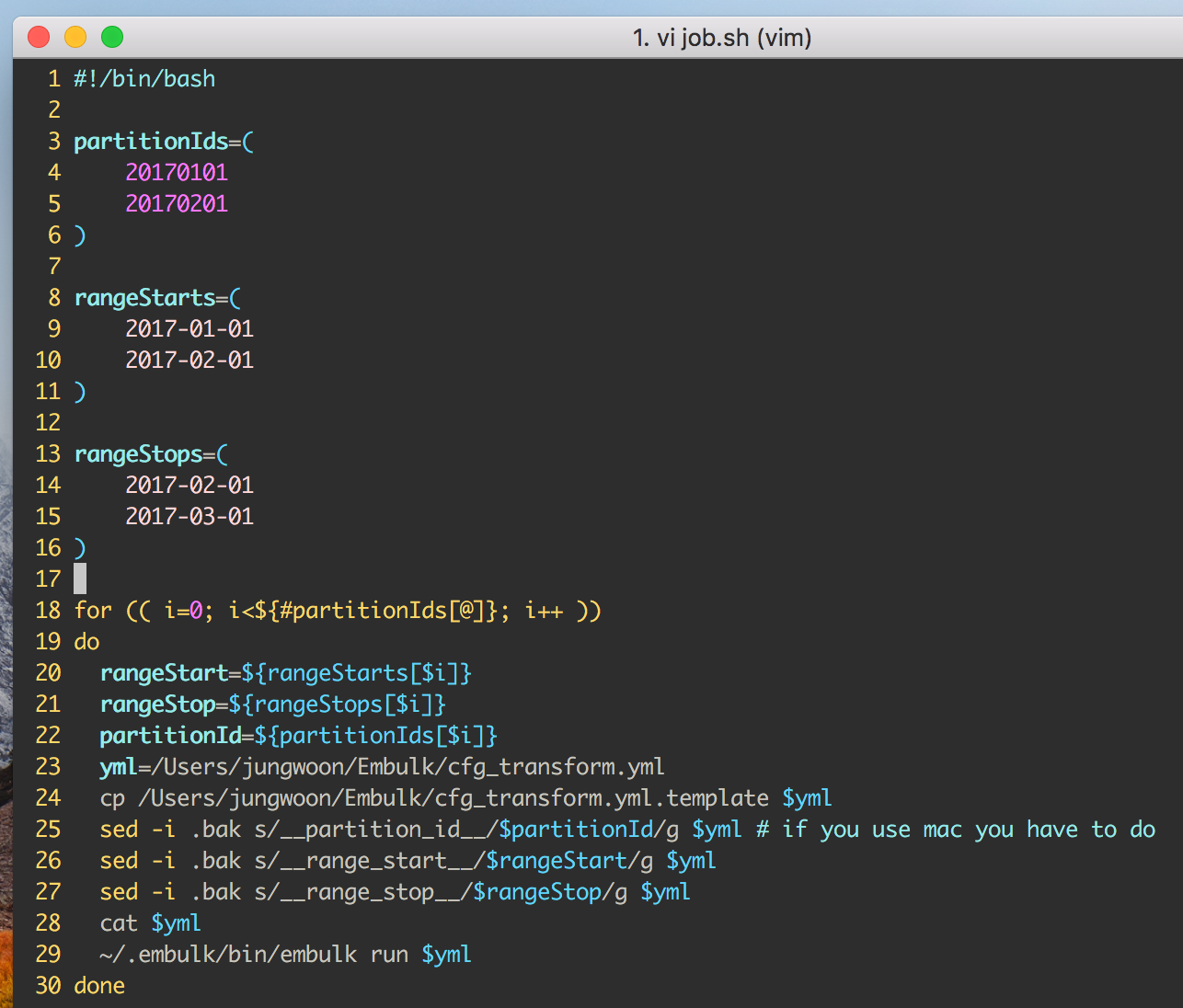
#!/bin/bash
partitionIds=(
20170101
20170201
)
rangeStarts=(
2017-01-01
2017-02-01
)
rangeStops=(
2017-02-01
2017-03-01
)
for (( i=0; i<${#partitionIds[@]}; i++ ))
do
rangeStart=${rangeStarts[$i]} # rangeStart란 변수에 위에 rangeStarts[i] 변수를 대입
rangeStop=${rangeStops[$i]} # rangeStop란 변수에 위에 rangeStops[i] 변수를 대입
partitionId=${partitionIds[$i]} # partitionId란 변수에 partitionIds[i] 변수를 대입
# Rundeck을 사용하기 위해서 경로는 반드시 절대경로로 잡아줍니다
yml=/Users/jungwoon/embulk/cfg_transform.yml # yml변수에 cfg_transform.yml 이란 변수 대입
cp /Users/jungwoon/embulk/cfg_transform.yml.template $yml # 위의 template에 위에서 넣은 cfg_transform.yml 이란 이름으로 복사
# 이 아래는 sed 명령어를 통해서 위에서 만든 변수들을 대입하는 부분
sed -i .bak s/__partition_id__/$partitionId/g $yml # $yml에서 __partition_id__를 찾아서 $partitionId 로 치환
sed -i .bak s/__range_start__/$rangeStart/g $yml # $yml에서 __range_start__를 찾아서 $rangeStart로 치환
sed -i .bak s/__range_stop__/$rangeStop/g $yml # $yml에서 __range_stop__를 찾아서 $rangeStop로 치환
cat $yml # 위에서 생성한 내용을 cat으로 화면에 보여줌
~/.embulk/bin/embulk run $yml # embulk run으로 위에서 만든 yml 파일을 실행
done
그 다음 만들어진 job.sh를 실행하기 위해 권한을 줍니다
$ chmod 755 job.sh
설명)
chmod 명령어 : 파일 권한을 관리하는 명령어입니다
권한 : r(읽기), w(쓰기), x(실행)
(User) (Group) (Other)
rwx rwx rwx
421 421 421
위와 같은 형태로 각 User, Group, Other에 대해서 주고 싶은 권한에 대해서
아래 숫자를 더하면 권한이 바뀌게 됩니다
예로 위에서 755 이면 User[4(r)+2(w)+1(x)] Group[4(r)+1(x)] Other[4(r)+1(x)]의
권한으로
User : 읽기 쓰기 실행
Group : 읽기 실행
Other : 읽기 실행
이 권한이 설정되게 됩니다
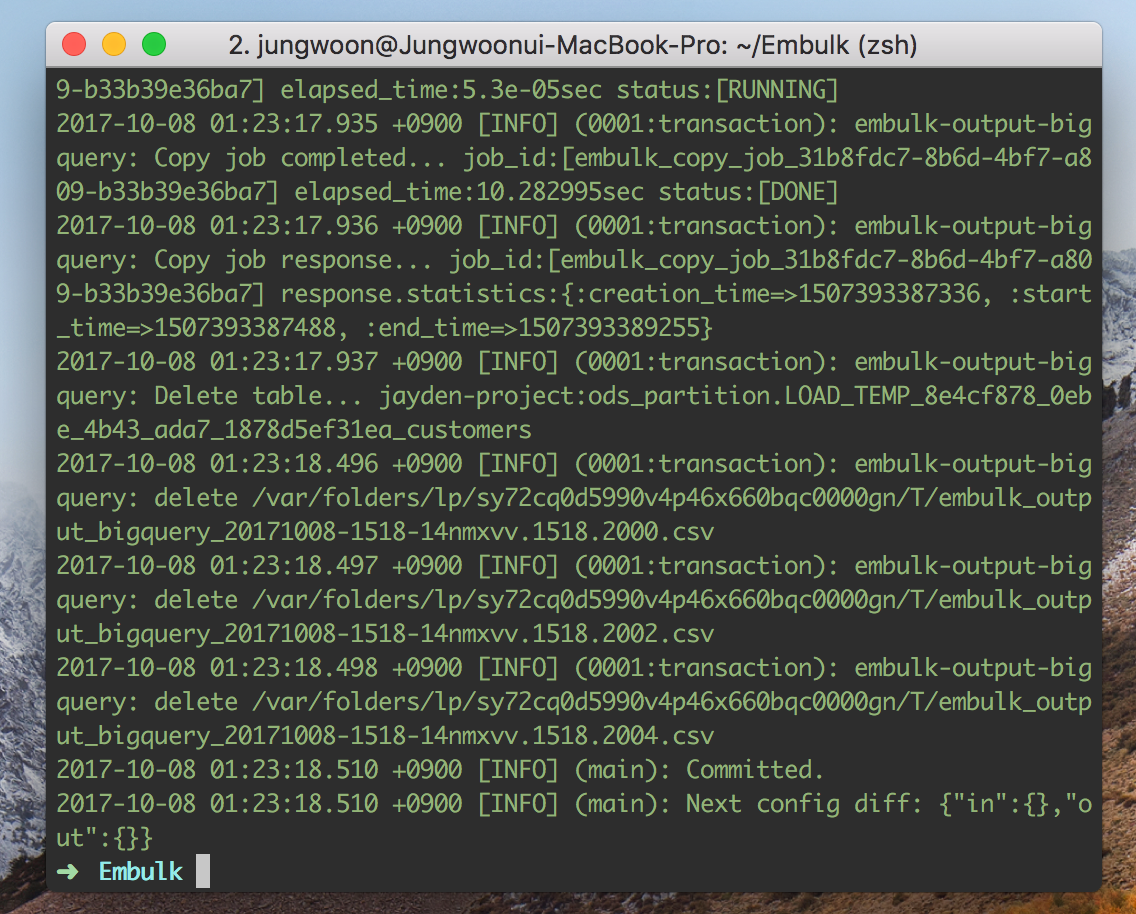
그 다음에 job.sh를 실행합니다
$ ./job.sh # job.sh가 있는 폴더에 들어가있다고 가정했을때 명령어
그래서 아래와 같이 Embulk가 실행이 되면 됩니다
sed 명령어 간단 사용법
sed는 Stream EDiter의 약자로 간단하게 텍스트를 파싱하고 변형하는 텍스트 편집 도구입니다
여기서는 간단하게 사용방법만 정리해놓고 자세한 내용은 추후에 쉘스크립트와 함께 다시 포스팅을 하도록 하겠습니다
문법
sed [옵션] [명령어] [파일]
옵션
-n: 읽어들인 라인을 암시적으로 자동출력하는 것을 중단한다-e: 실행될 명령에 스크립트를 추가한다-f: sed 스크립트 파일 지정-i: 파일을 제자리 처리 한다 (=변경된 내용을 파일에 적용한다)-c: 제자리 처리시에 사본을 쓴-r: 확장된 정규표현식을 사용한다
명령어
d: 출력시 지정 행 삭제, 원본은 유지!: 명령어를 반대로 수행, 선택된 라인을 제외한 나머지 라인에 명령 적용p: 패턴에 맞는 행 출력 -n 옵션이 없으면 동일 행이 중복해서 출력된다w: 파일 쓰기s: 문자열 치환, 해당 라인에 첫번째 문자가 치환이 되지만 g 옵션을 통해서 전체 치환도 가능a: 지정문자열을 다음 라인에 추가c: 지정 문자열로 기존 라인의 텍스트를 대체q: sed 편집기 종료
예제
sed 1,/search/d: 첫번째 줄부터 search 단어가 나타나는 줄까지 삭제sed 1,5 !d: 1~5라인을 제외한 나머지 라인 삭제sed s/apple/google/g: 모든 apple을 google로 모두 치환sed s/apple/google/g newfile: 모든 apple을 google로 모두 치환해서 newfile에 기록
메타문자
.: 해당 위치에 들어가는 단 하나의 모든 문자에 대응&: 검색할 문자열에서 사용한 문자열을 치환열에서 그대로 사용*: 모든 문자에 대응^: 해당 라인의 시작을 의미$: 해당 라인의 끝을 의미\<: 단어의 시작 부분을 의미\>: 단어의 끝을 의미\{n\}: 정확히 n번 반복\{n,\}: 적어도 n번 반복\{n,m\}: n번 이상 m번 이하 반복
메타문자 예제
sed s/naver&blog/: naver를 naverblog로 치환 여기서&는 naver와 같다sed s/^google/app/: google로 시작하는 라인의 gogole 문자열을 app으로 치환sed s/\<google/app/: google로 시작하는 단어를 app으로 치환sed s/txt\>/jpg/: txt로 끝나는 단어를 jpg로 치환
Rundeck 설치 및 워크플로우 등록하기
Rundeck은 CI툴의 일종으로 보고 라이브 배포시에 이용할 수 있습니다 위에서 만든 쉘 스크립트를 Rundeck에서 제어 해보도록 하겠습니다
먼저 http://rundeck.org 에 들어갑니다 그럼 아래와 같은 화면이 나오는데 여기서 Download Rundeck을 누릅니다

그럼 다음과 같은 화면이 나오는데 여기서는 왼쪽에서 Download Rundeck Core 버튼을 누릅니다
저 같은 경우는 MacOS 환경이므로, jar 파일을 받도록 하겠습니다
다운로드 받은 jar 파일을 아래 명령어로 실행을 시킵니다
$ java -jar rundeck-launcher-2.9.3.jar
그럼 아래와 같이 실행이 됩니다
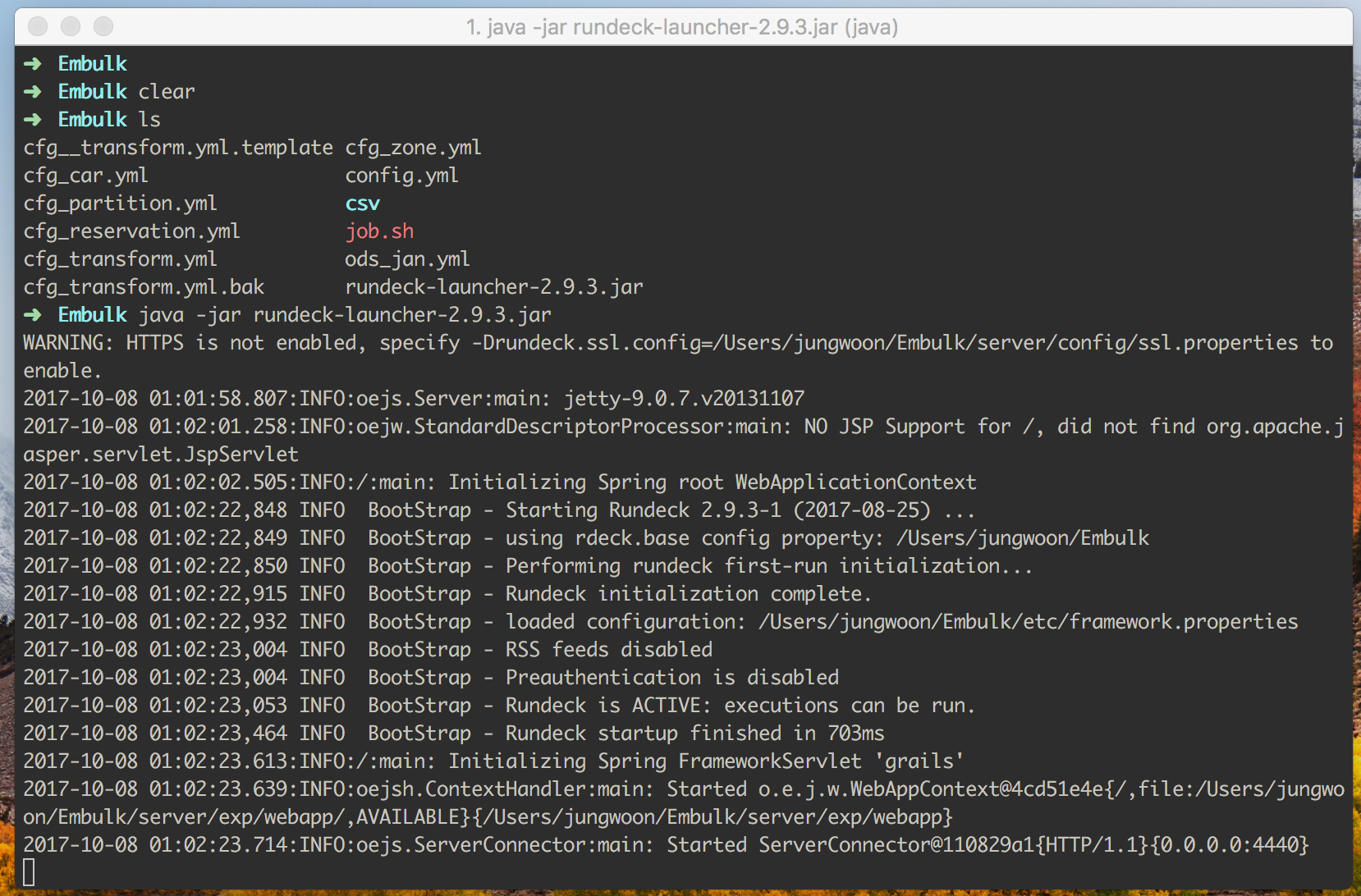
이제 브라우저를 열고 http://localhost:4440로 들어갑니다
기본 설정으로 세팅되어 있는 관리자 아이디와 비밀번호는 admin 입니다
Username : admin
Password : admin
입력을 하고 Login 버튼을 누릅니다 (여기서 URL 주소를 잘 봅니다)
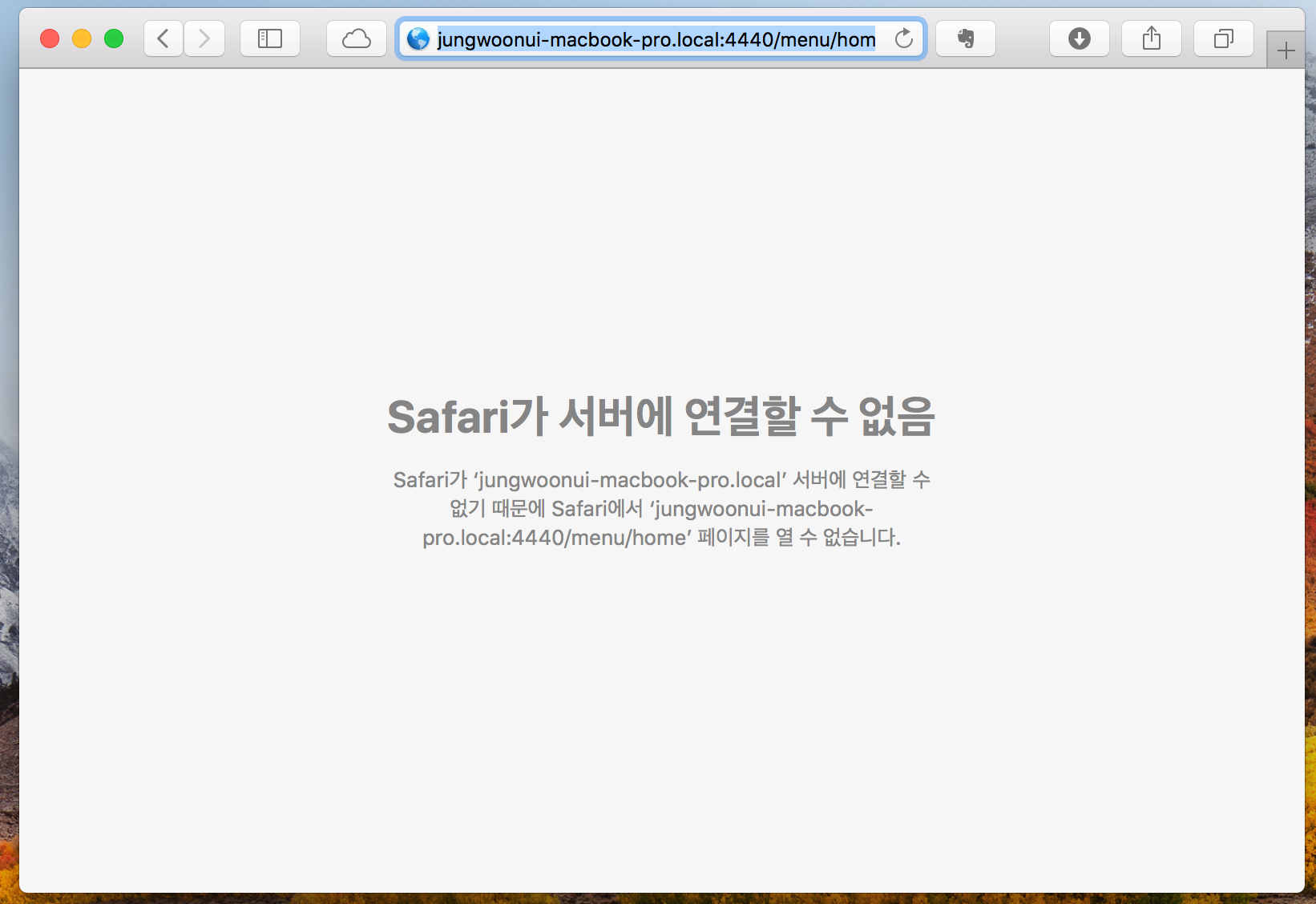
그럼 아마 다음과 같이 연결할 수 없다고 나오는데, 주소가 localhost -> jungwoonui-macbook-pro.local로 바뀐것을 확인할 수 있습니다
이건 아마 로컬에서 테스트할때 자동으로 바뀌게끔 되어 있는거 같은데 jungwoonui-macbook-pro.local이 무슨 주소인지 몰라서 페이지를 찾을 수 없다고 나옵니다
(** 여기에서 jungwoonui-macbook-pro.local 이 이름은 개별 컴퓨터마다 다르게 나옵니다, 저는 macbook으로 실습을 하고 있고 홈 디렉토리가 jungwoon이라 이렇게 나옵니다)
이제 위에 방법을 해결해주기 터미널을 열고 아래와 같이 입력합니다
$ sudo vi /etc/hosts # 시스템 파일이라 sudo를 입력해야 합니다

그리고 아래의 마지막 줄 같이 입력을 합니다, 내용은 jungwoonui-macbook-pro.local는 127.0.0.1로 매핑하겠다는 의미입니다
(** 각자 이름이 다르기 때문에 위에서 페이지 로딩 실패했을때 나타났던 주소에서 복사해서 붙여넣기를 합니다)
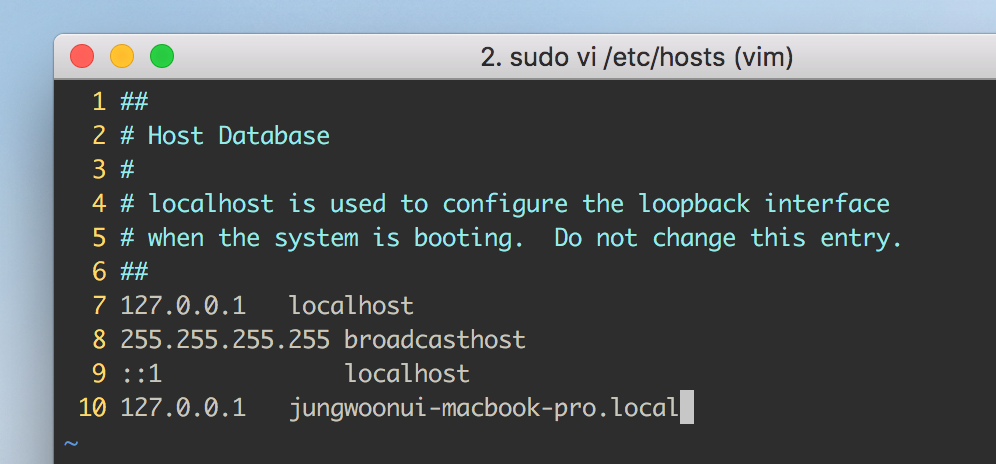
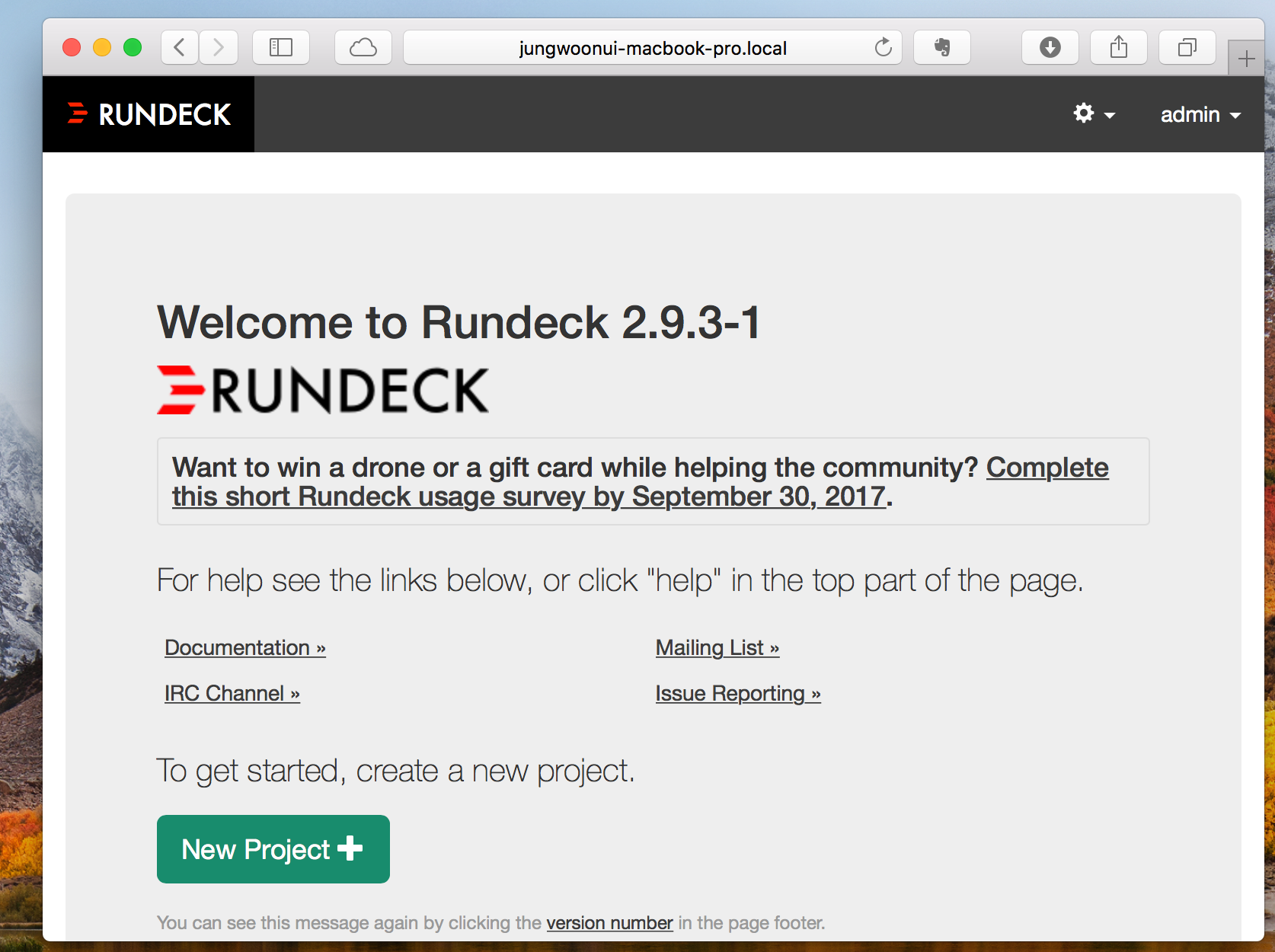
그 다음 다시 브라우저를 열고 http://localhost:4440로 들어가서 로그인을 하면 아래와 같이 URL이 바뀌어도 정상적으로 동작하는걸 확인할 수 있습니다.
일단 아래의 New Projectt+ 버튼을 눌러서 새로운 프로젝트를 만듭니다
그럼 아래와 같이 화면이 나오는데 Project Name을 적당히 주고 밑으로 내립니다
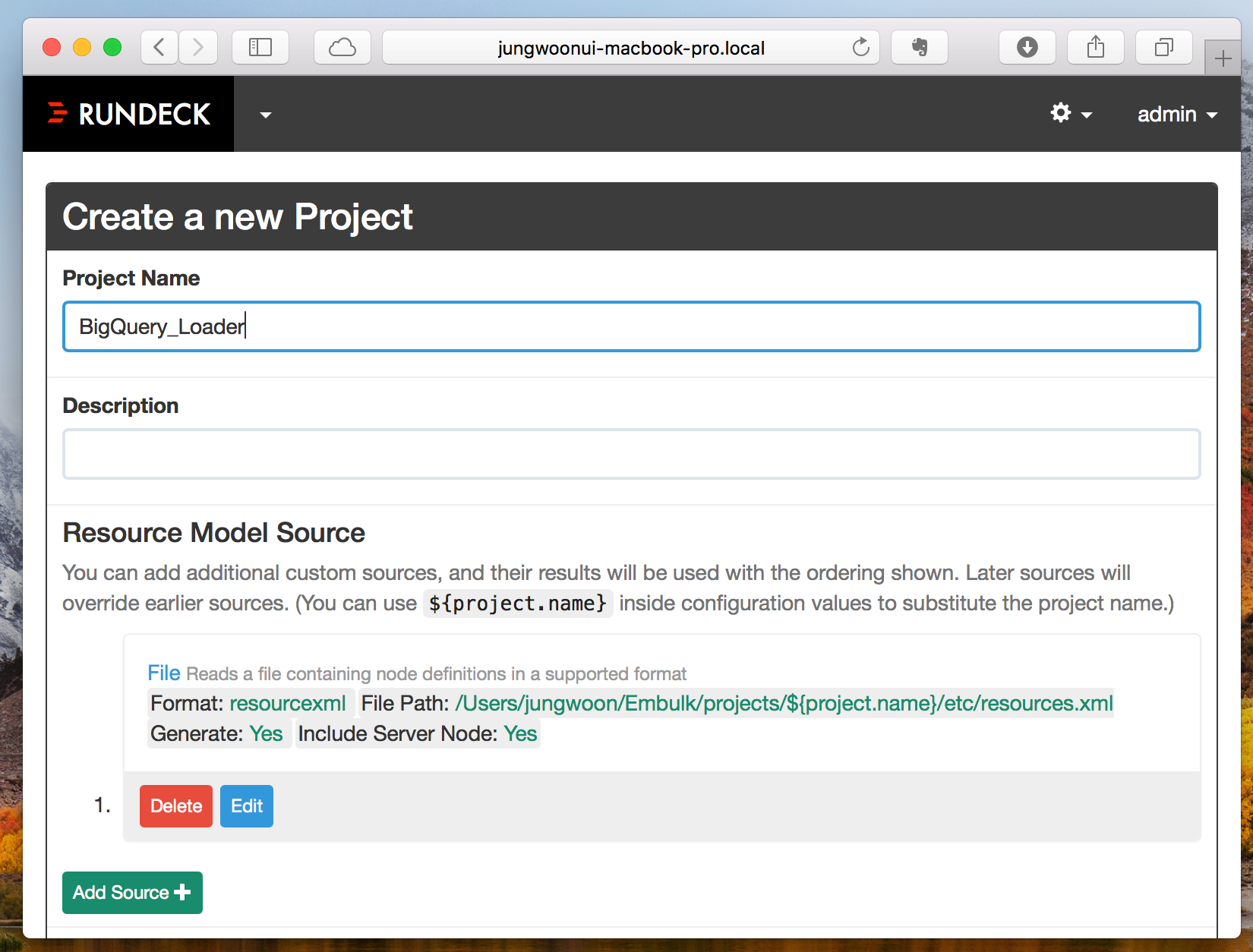
맨 마지막에 오면 Create 버튼을 볼 수 있는데 버튼을 누릅니다
그 다음에는 아래와 같은 화면이 나타납니다, 여기서 Create a New Job... 버튼을 눌러 새로운 잡을 만듭니다
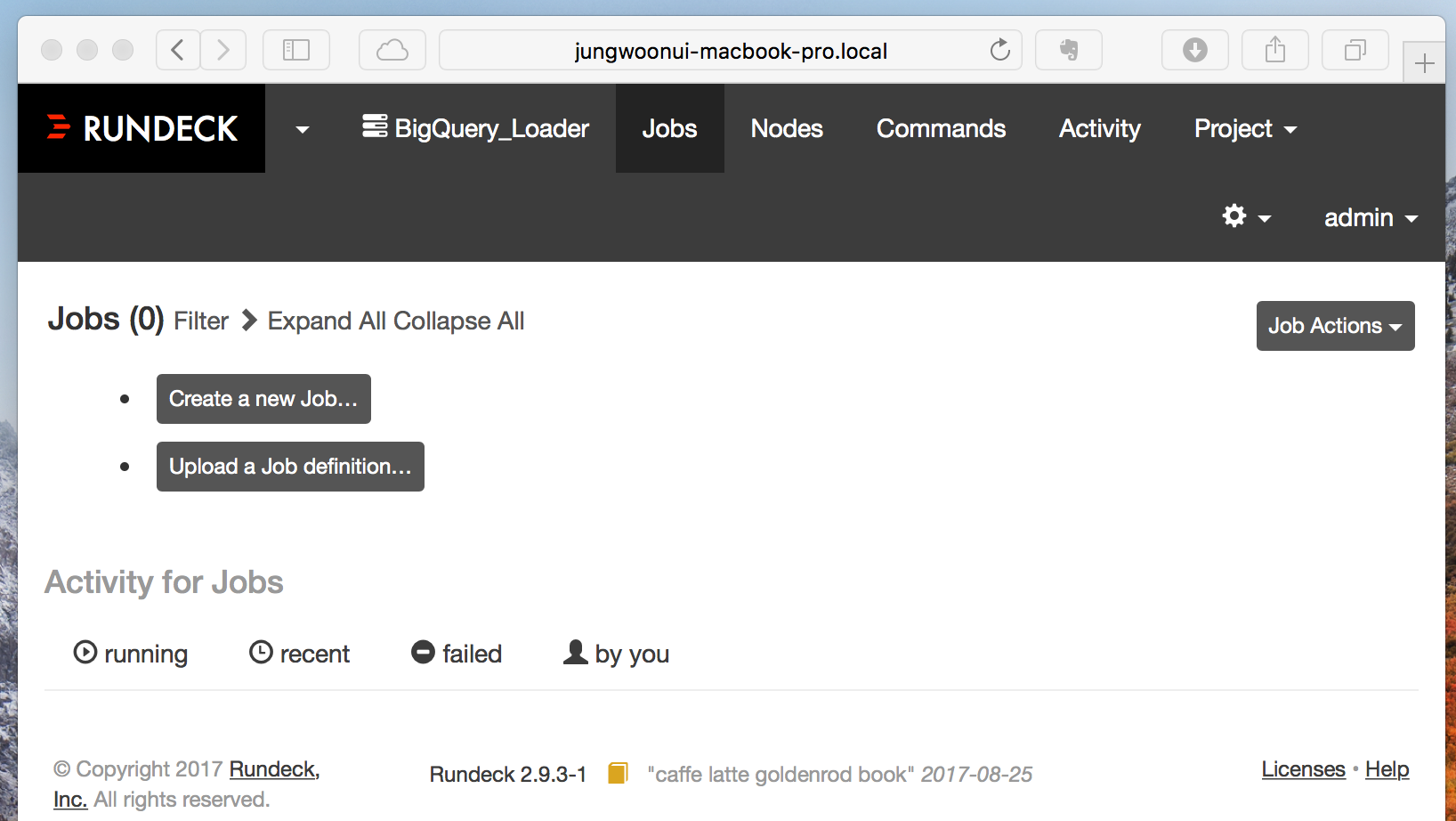
적당히 job에 이름을 주고 스크롤을 내립니다
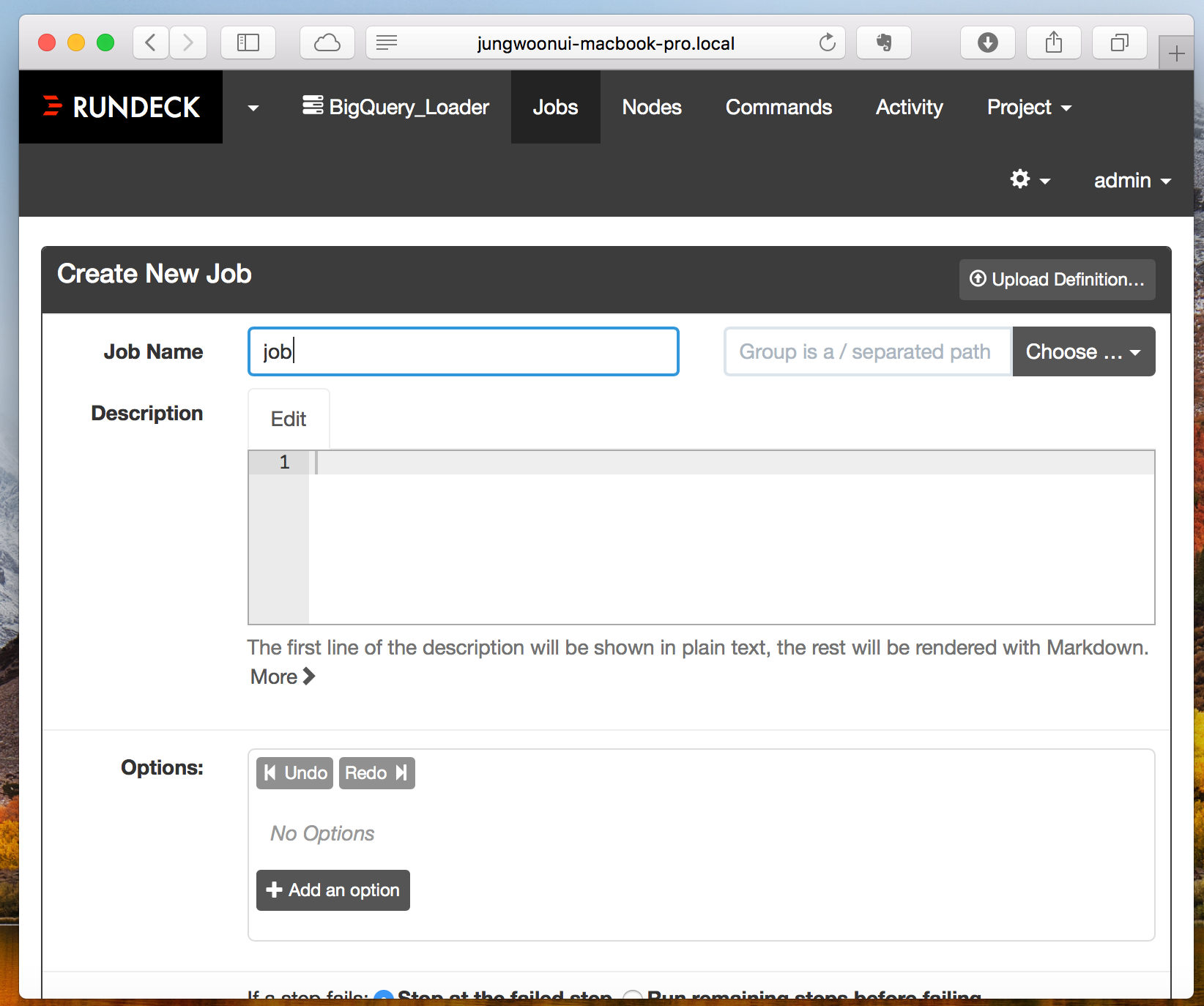
아래와 같이 Workflow 까지 내립니다
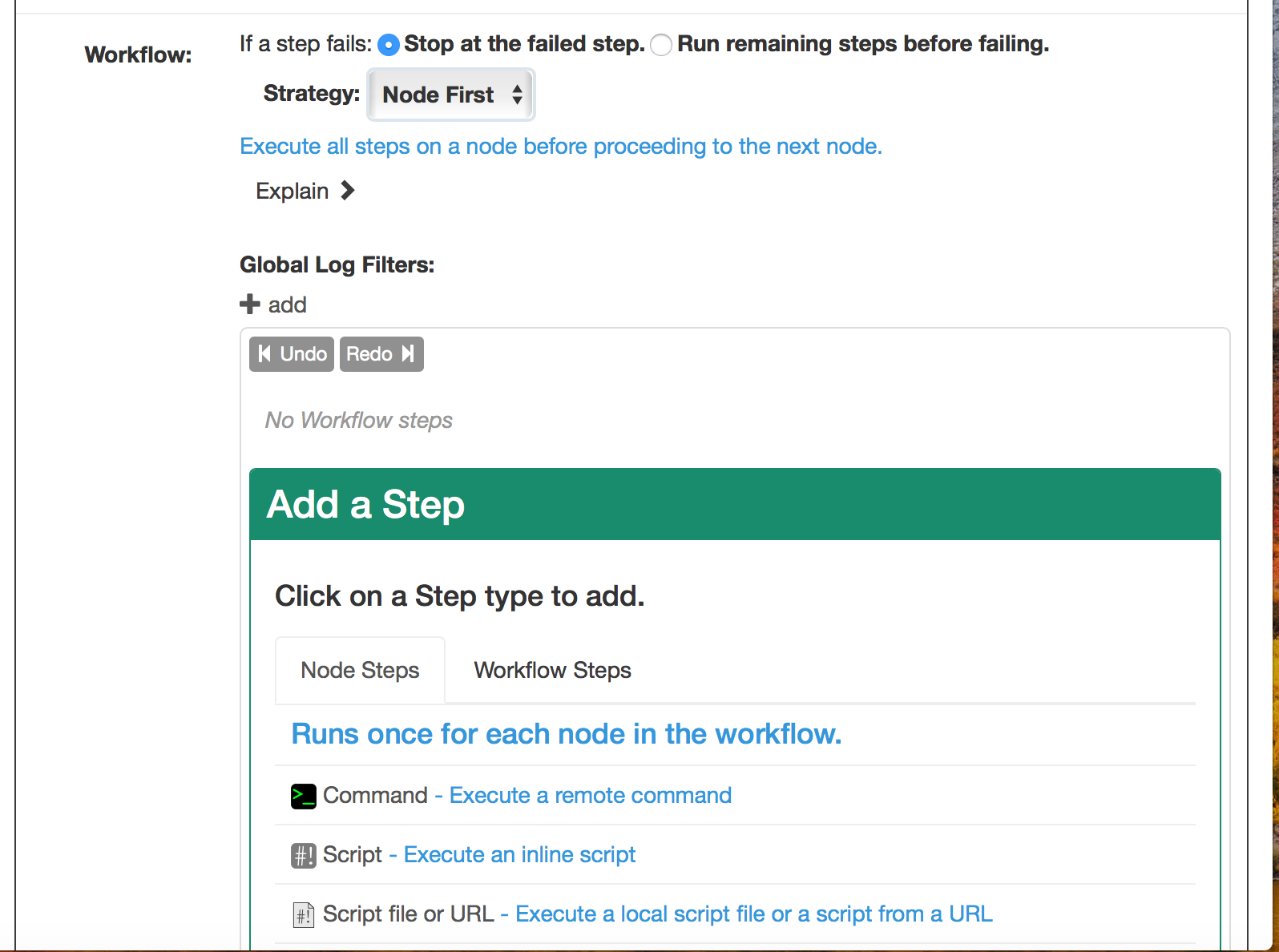
그럼 아래와 같이 다양하게 Workflow를 만들 수 있도록 지원하는 걸 확인할 수 있습니다
저는 만들어 놓은 쉘 스크립트가 있으니 그냥 Command를 선택하여 쉘 스크립트를 실행하도록 하겠습니다
우선 Command를 누릅니다
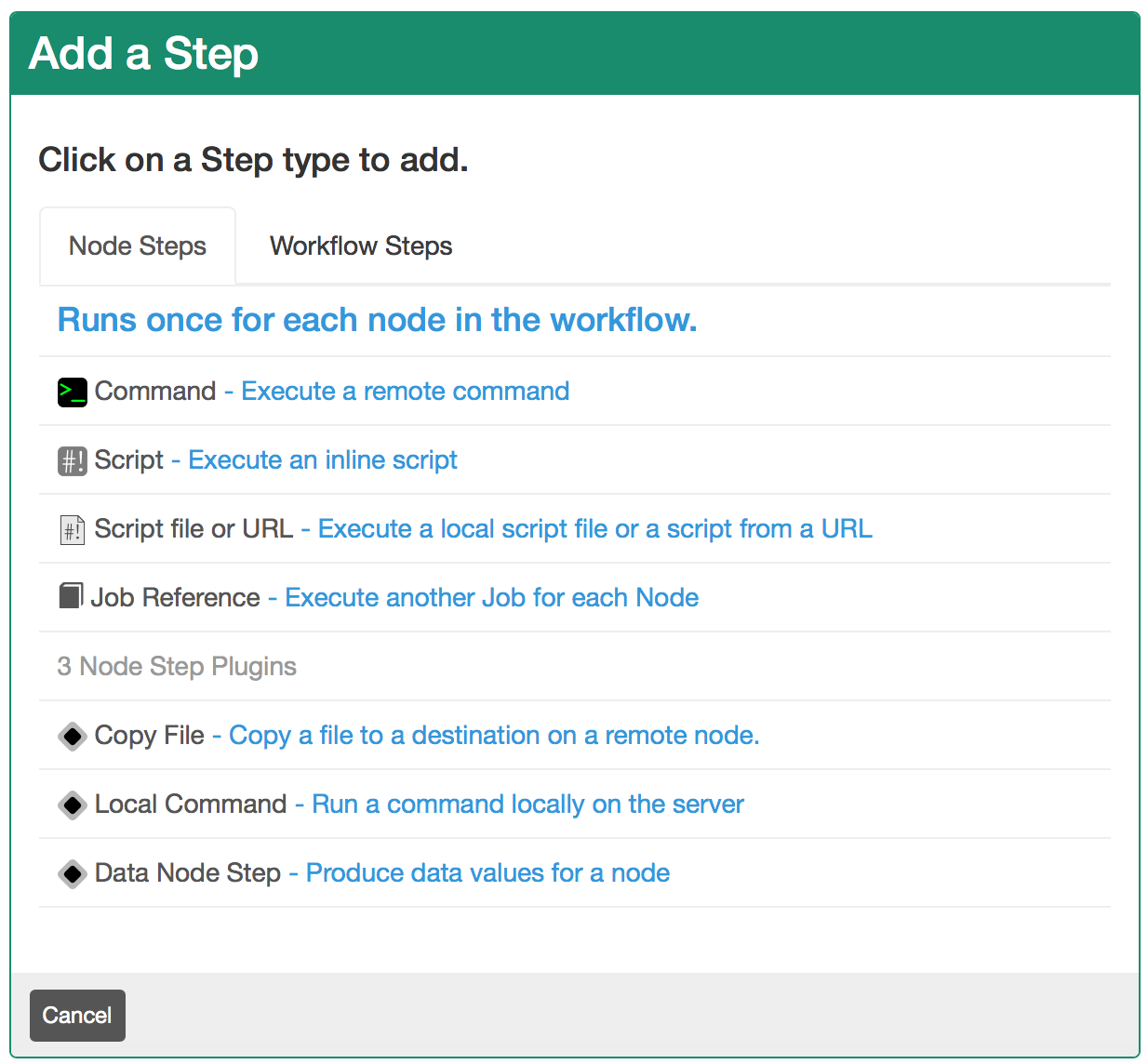
그럼 아래와 같이 나오는데, 절대 경로로 아까 만든 쉘 스크립트 위치를 지정하고 save를 누르고, 스크롤을 내려서 Job을 생성합니다
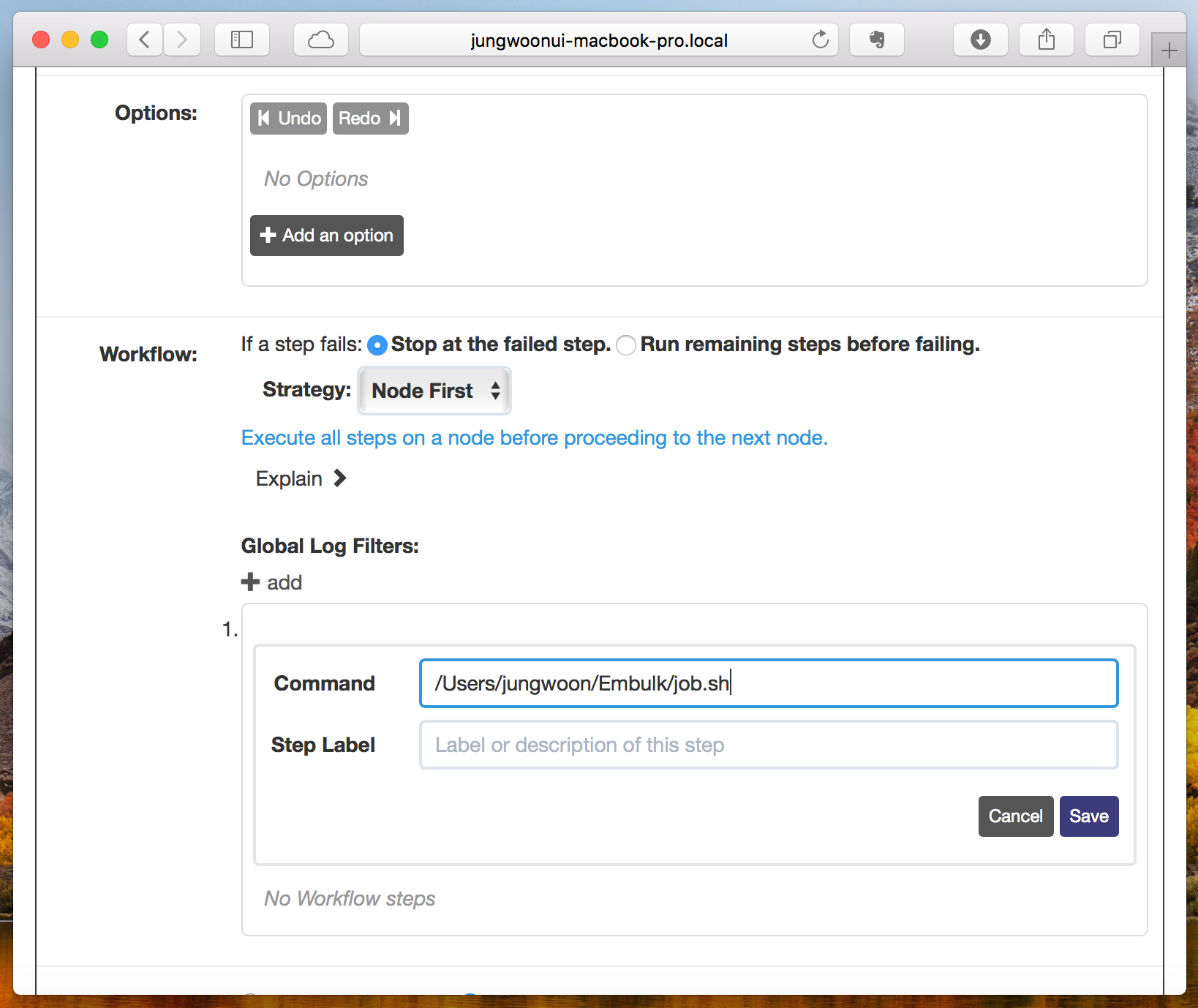
그럼 아래와 같이 나오는데 여기서 Run Job Now를 눌러서 Job을 실행 시킵니다
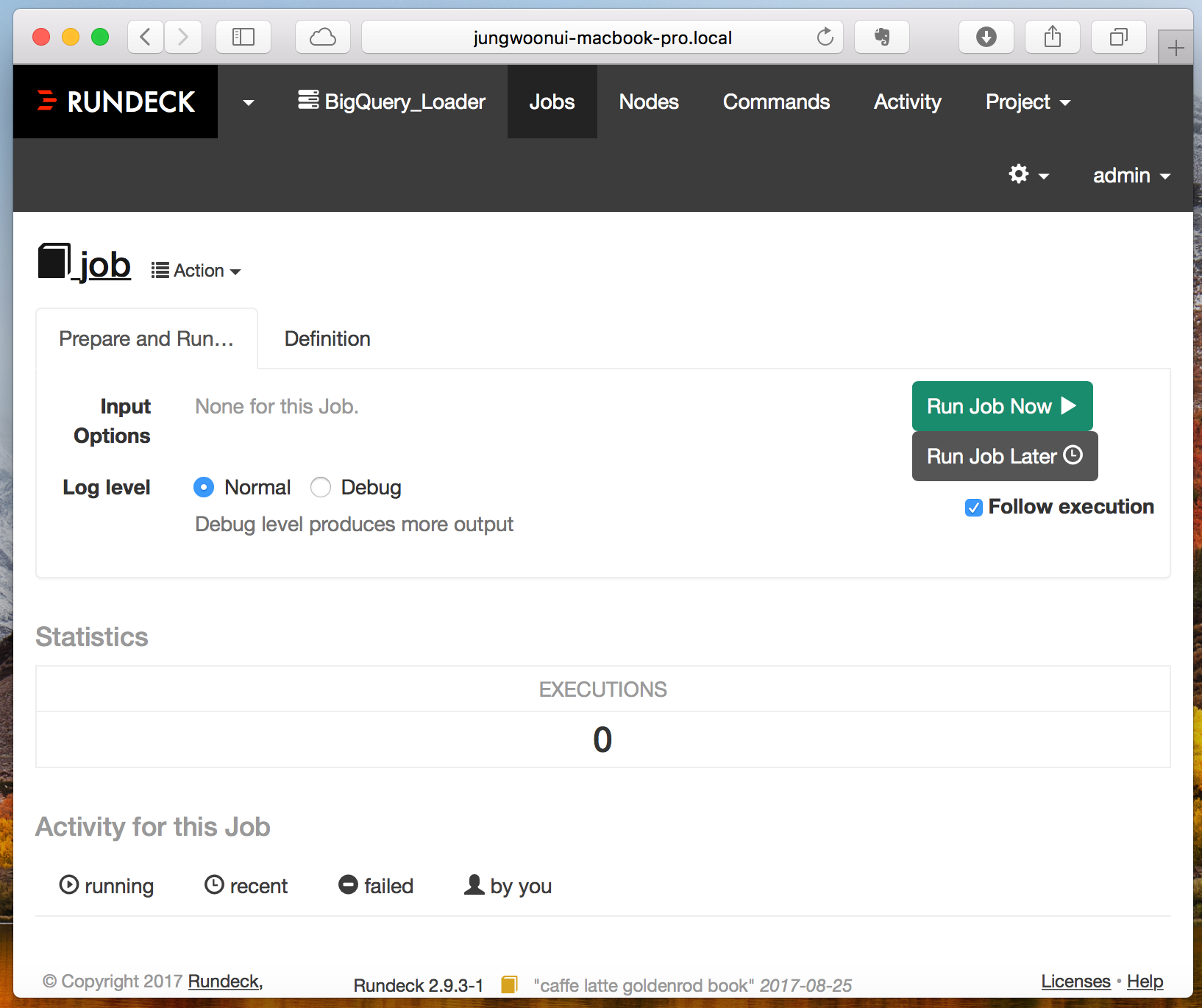
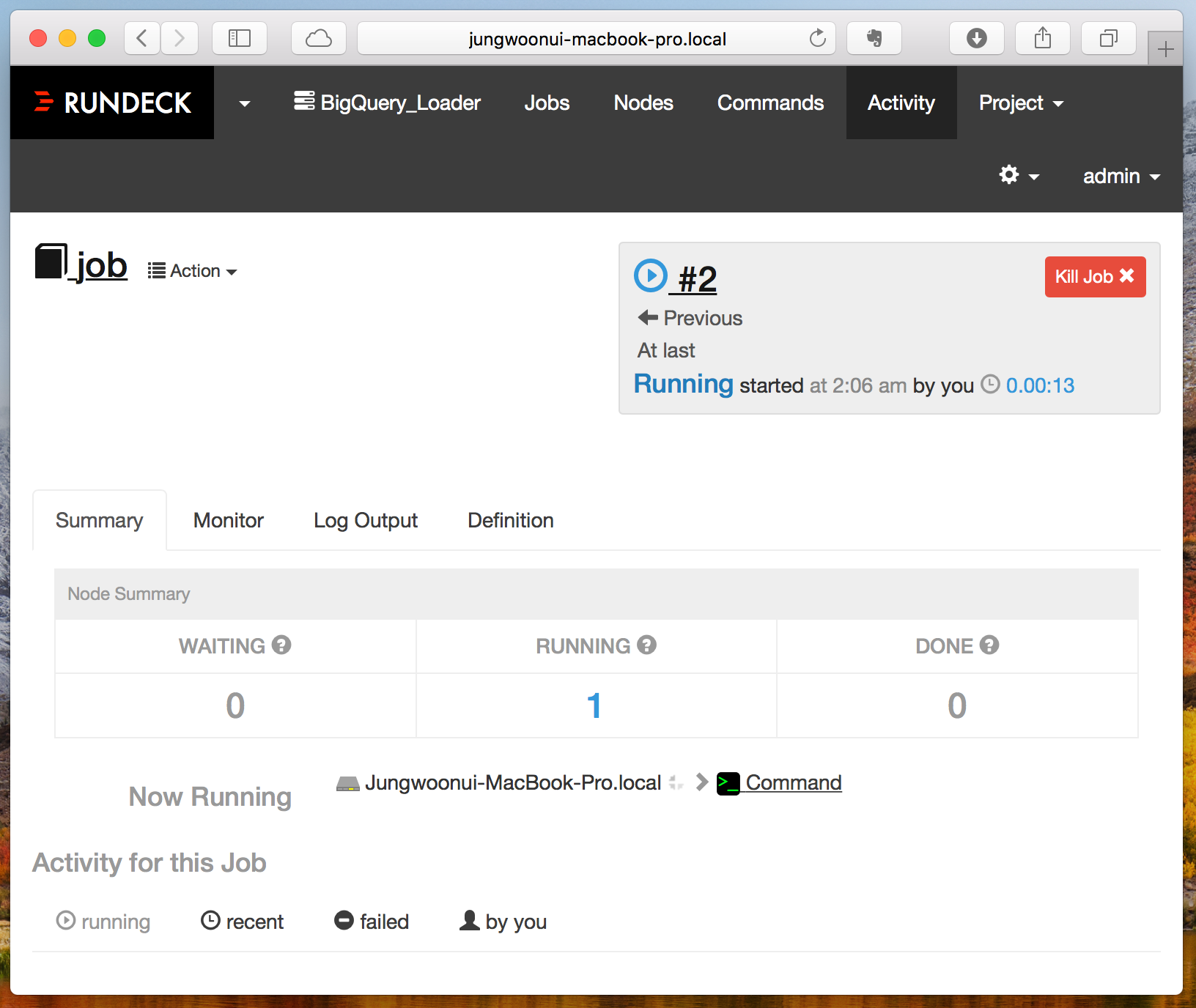
그럼 아래와 같이 Running 쪽에 숫자가 증가하면서 job 이 실행됩니다
(** 우측 상단의 #2는 중간에 실패해서 디버깅하느라고 job이 증가한거라 신경쓰실 필요 없습니다)
job이 성공이 되면 아래와 같이 Complete가 됩니다
(Tip - 쉘 스크립트를 만들때, 반드시 절대경로로 만들어야 Job이 정상적으로 동작을 합니다, 꼭 상대경로말고 절대경로를 입력해주세요)
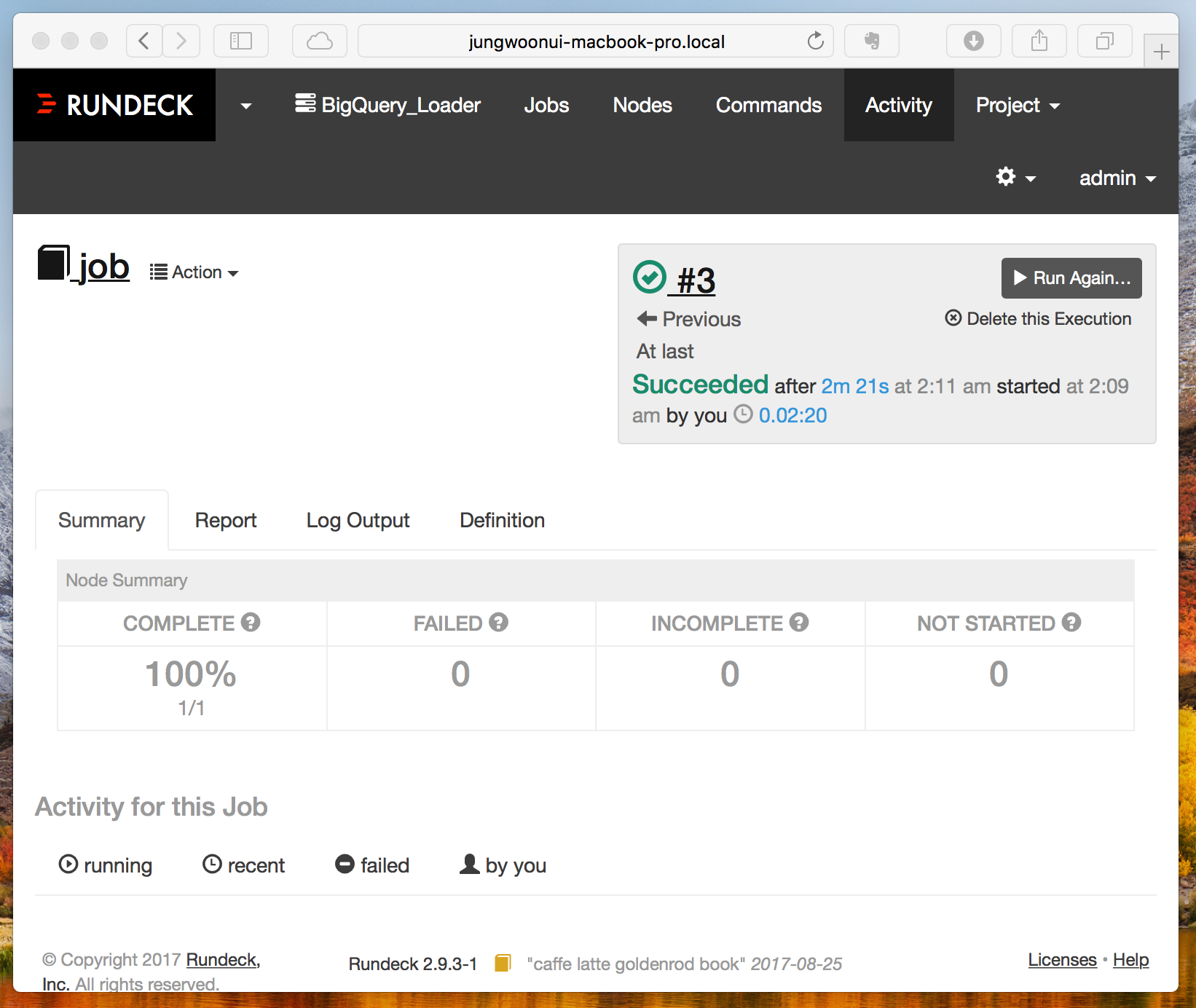
Rundeck 스케쥴링을 통한 반복 설정하기
job의 오른쪽의 화살표를 눌러서 edit this job...을 선택합니다.
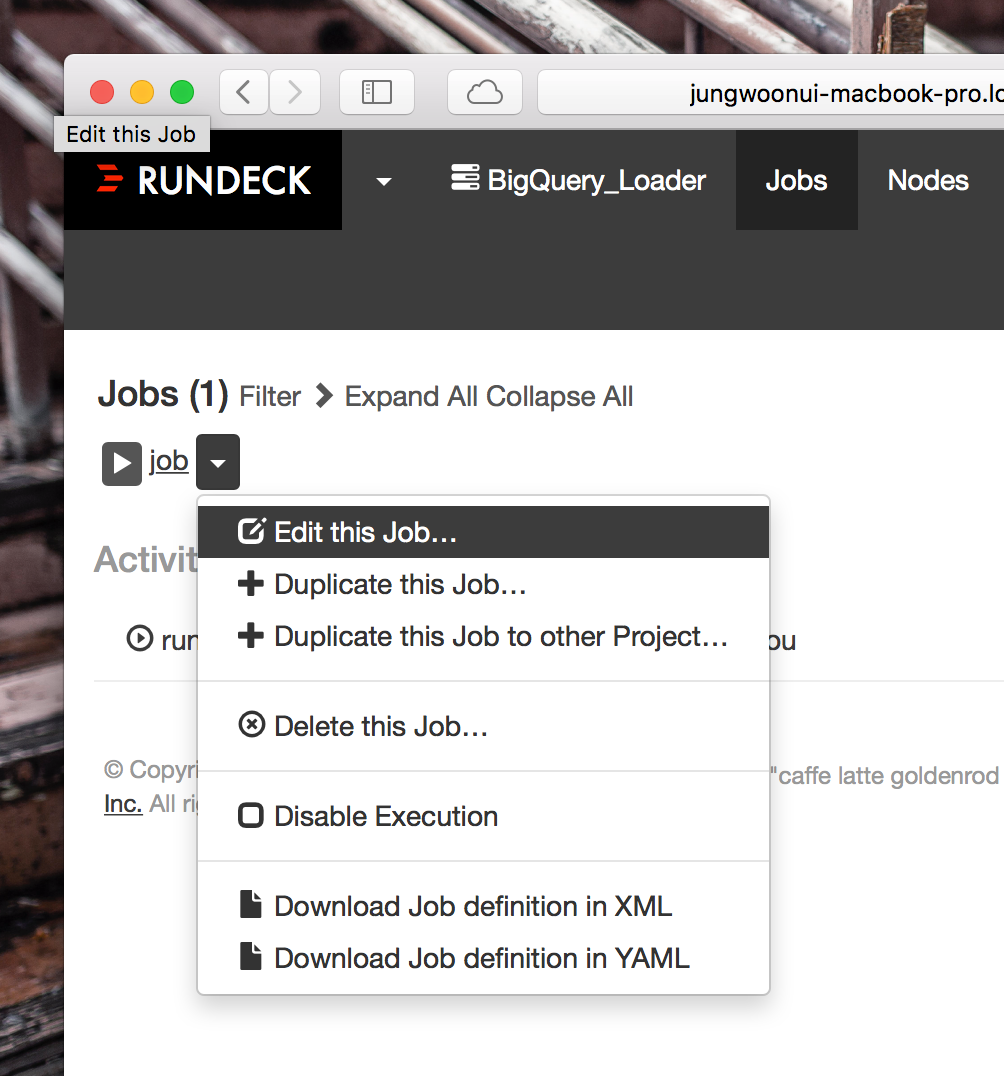
스크롤을 내려서 좌측의 Schedule to run repeatedly?를 찾아서 Yes를 누릅니다
손쉽게 Simple을 통해서 특정 시간에 해당 Job을 반복하게 설정할 수 있습니다
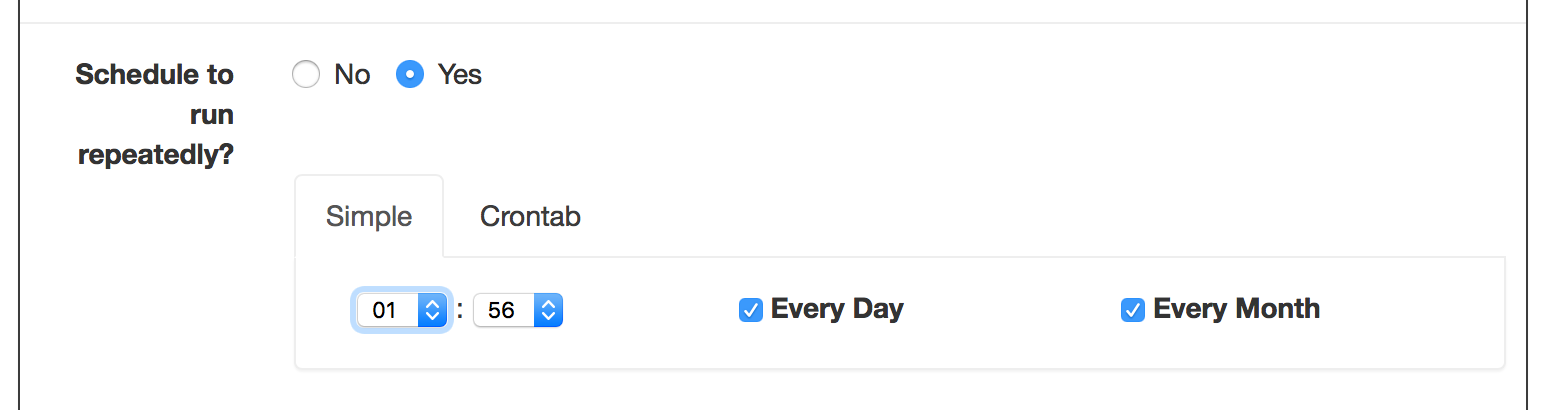
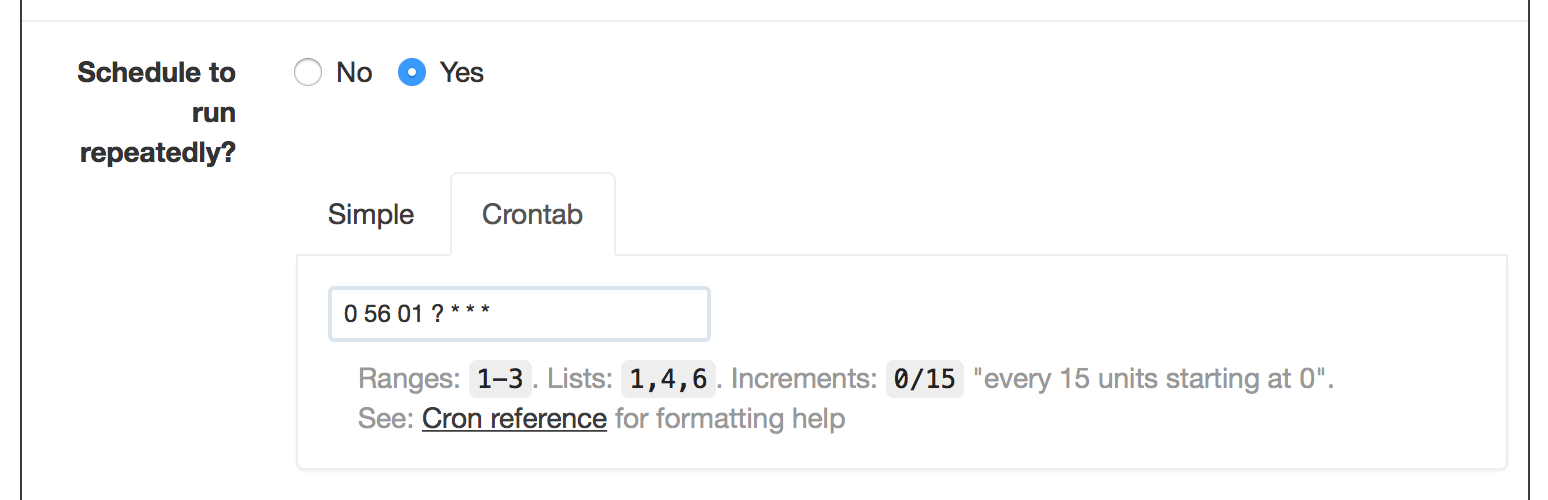
좀 더 디테일한 설정을 하고 싶으면 Crontab Tab을 눌러서 Linux의 Crontab과 동일 한 설정을 할 수 있습니다
(** 설정은 아래를 참고하세요)
* * * * * 수행할 명령어
┬ ┬ ┬ ┬ ┬
│ │ │ │ │
│ │ │ │ │
│ │ │ │ └───────── 요일 (0 - 6) (0:일요일, 1:월요일, 2:화요일, …, 6:토요일)
│ │ │ └───────── 월 (1 - 12)
│ │ └───────── 일 (1 - 31)
│ └───────── 시 (0 - 23)
└───────── 분 (0 - 59)
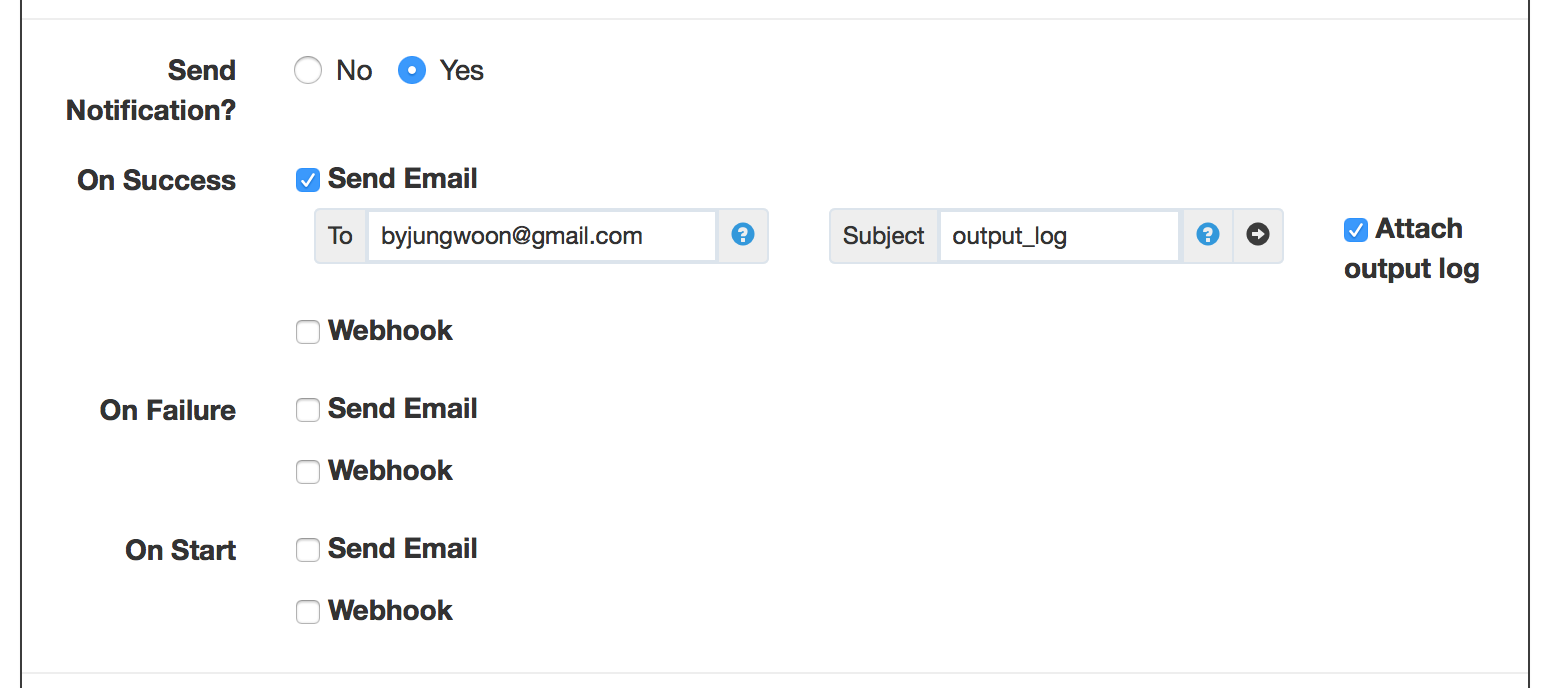
Rundeck 작업 Notification 보내기
스크롤을 내려서 좌측의 Send Notification?을 찾아서 Yes를 누릅니다
그 다음 Notification을 보내고자 하는, 상태(성공, 실패, 시작)에 대해서 Mail을 설정할 수 있습니다
마무리
이상으로 쉘스크립트와 Rundeck을 이용하여 자동으로 로딩하는 부분에 대한 포스팅을 마무리 하겠습니다. 아직 배우는 과정이라 잘못되거나 한 점이 있으면 언제든 댓글로 남겨주세요 감사합니다