데이터 소스로부터 많은 데이터를 읽어올때 한번에 가져오게 되면 중간에 예상치 않은 문제가 생길 수도 있고, 테이블을 파티셔닝 하여 로딩하게 되면 병렬로 빠르게 처리도 가능하게 됩니다
그래서 Embulk를 이용하여 Sequential하게 증가하는 데이터를 이용하여 범위를 나눠서 데이터를 별도로 로드하는 방법을 한번 진행해보고자 합니다
빅쿼리 자체적으로 Partitiond Tables를 지원합니다, 자세한 내용은 다음 링크를 참조합니다 (참고 - https://cloud.google.com/bigquery/docs/partitioned-tables)
구글 빅쿼리의 partitioned table 제한 (2017.09.28. 기준)
- Daily limit : 테이블당 2,000 파티션
- Rate limit : 매 10초당 50개의 파티션 업데이트
빅쿼리 파티셔닝 하는 방법
테이블 이름을 이용하여 파티셔닝을 합니다
- [테이블 명]$[YYYYMMDD] ex) customers$20170101, customers$20170201
실습
Embulk를 이용해서 시간을 가지고 월별로 데이터를 쪼개서 파티셔닝을 할 예정입니다
(만약 Embulk를 처음 써보신다면 여기를 들어가서 사용법을 확인해주세요)
먼저 아래와 같이 데이터 스키마가 생겼습니다 여기서 start_at이란 Sequential하게 증가하는 컬럼을 선택하여 파티셔닝을 하도록 하겠습니다
여기서는 시간이 UTC로 되어 있어서 한국 시간에 맞춰주기 위해서 +9를 하였습니다
(** 빅쿼리는 기본적으로 UTC만 지원하기 때문에 글로벌 서비스를 하는 경우에는 UTC로 저장을 해놓고 데이터 추출시에 Local Time에 맞춰서 변경 한다음에 이용하는게 좋습니다)
데이터 스키마
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int(11) | NO | PRI | NULL | auto_increment |
| cid | int(11) | NO | NULL | ||
| zid | int(11) | NO | NULL | ||
| state | tinyint(4) | NO | NULL | ||
| start_at | datetime | YES | NULL | ||
| end_at | datetime | YES | NULL | ||
| used_at | float | YES | NULL |
Tip) ETL vs ELT
- ETL(Extract, Transform, Load) : 추출, 변형, 로드
- 원천 데이터에서 데이터를 추출해서 변형하고 다른 곳으로 로드를 하는 형태, 원천 데이터에서 변형을 하고 로드를 하기 때문에 좀 더 보안상의 이점이 있습니다
- ELT(Extract, Load, Transform) : 추출, 로드, 변형
- 원천 데이터에서 데이터를 추출해서 다른 곳에 로드를 하고 그곳에서 변형을 하는 형태
설정 파일 스크린샷
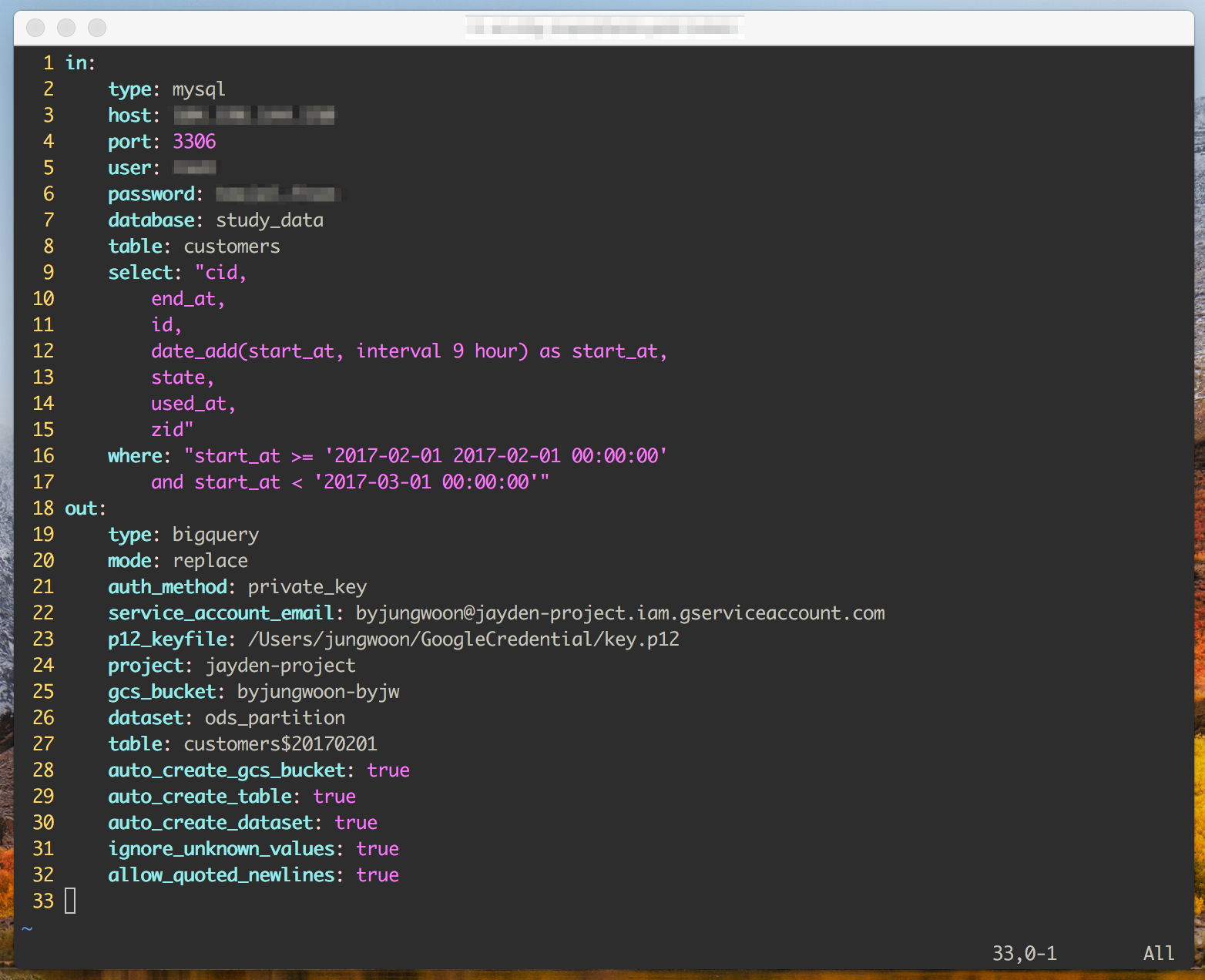
1월 데이터 로딩용 yml (ods_jan.yml)
in:
type: mysql
host: 111.111.111.111 # IP Address
port: 3306
user: root # ID
password: root # PASSWORD
database: study_data
table: customers
select: "cid,
end_at,
id,
date_add(start_at, interval 9 hour) as start_at, # UTC로 되어 있어서 한국 시간에 맞추기 위해 +9를 함
state,
used_at,
zid"
where: "start_at >= '2017-01-01 00:00:00'
and start_at < '2017-02-01 00:00:00'"
out:
type: bigquery
mode: replace # 이 부분이 replace로 되어 있어야 함
auth_method: private_key
service_account_email: byjungwoon@jayden-project.iam.gserviceaccount.com
p12_keyfile: /Users/jungwoon/GoogleCredential/key.p12
project: jayden-project
dataset: ods_partition
table: customers$20170101 # 이 부분에서 테이블 이름을 가지고 파티셔닝을 함
gcs_bucket: byjungwoon-byjw
auto_create_gcs_bucket: true
auto_create_dataset: true
auto_create_table: true
ignore_unknown_values: true
allow_quoted_newlines: true
2월 데이터 로딩용 yml (ods_feb.yml)
in:
type: mysql
host: 111.111.111.111 # IP Address
port: 3306
user: root # ID
password: root # PASSWORD
database: study_data
table: customers
select: "cid,
end_at,
id,
date_add(start_at, interval 9 hour) as start_at, # UTC로 되어 있어서 한국 시간에 맞추기 위해 +9를 함
state,
used_at,
zid"
where: "start_at >= '2017-02-01 00:00:00'
and start_at < '2017-03-01 00:00:00'"
out:
type: bigquery
mode: replace # 이 부분이 replace로 되어 있어야 함
auth_method: private_key
service_account_email: byjungwoon@jayden-project.iam.gserviceaccount.com
p12_keyfile: /Users/jungwoon/GoogleCredential/key.p12
project: jayden-project
dataset: ods_partition
table: customers$20170102 # 이 부분에서 테이블 이름을 가지고 파티셔닝을 함
gcs_bucket: byjungwoon-byjw
auto_create_gcs_bucket: true
auto_create_dataset: true
auto_create_table: true
ignore_unknown_values: true
allow_quoted_newlines: true
위에 설정파일(.yml) 설정을 끝난 뒤에 다음 명령어를 입력하여 MySQL -> BigQuery로 데이터 로딩을 합니다
$ embulk run ods_jan.yml
$ embulk run ods_feb.yml
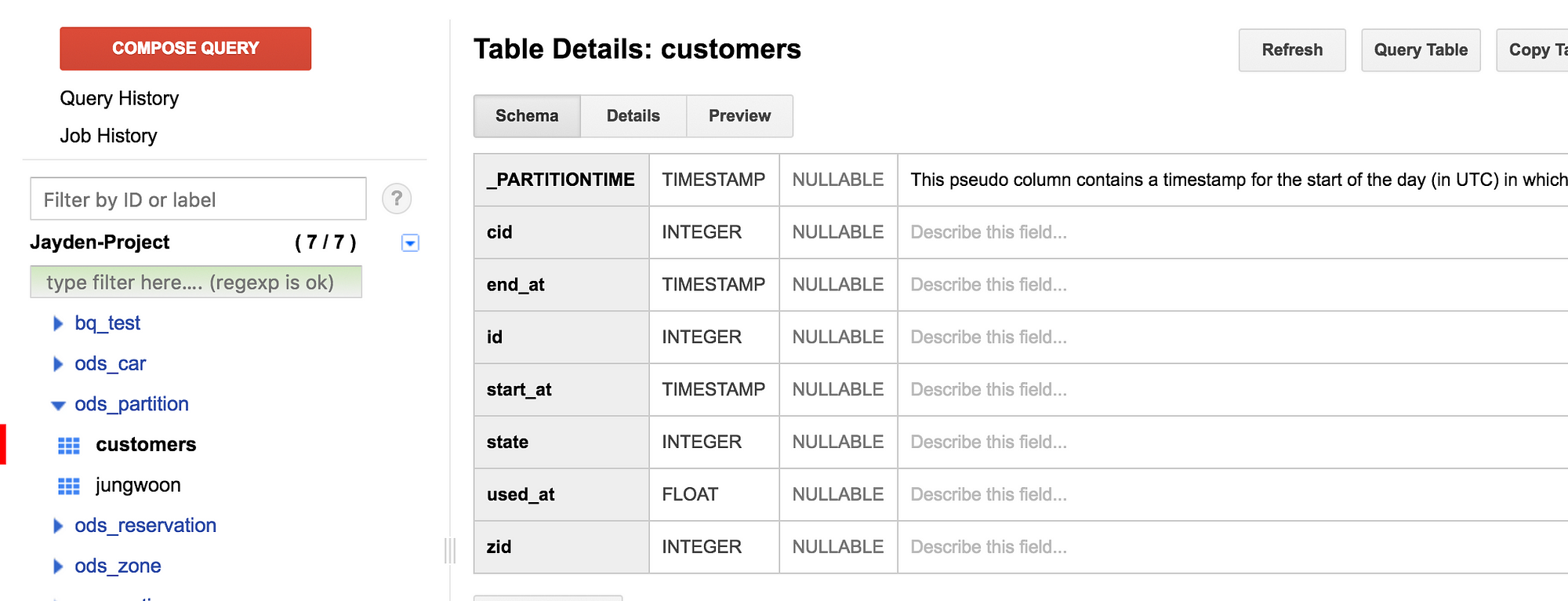
그 다음 빅쿼리에서 로드가 된 데이터를 살펴 보게 되면 아래와 같이 맨 위쪽에 _PARTITIONTIME 이라는 컬럼이 자동으로 추가된 것을 볼 수 있습니다
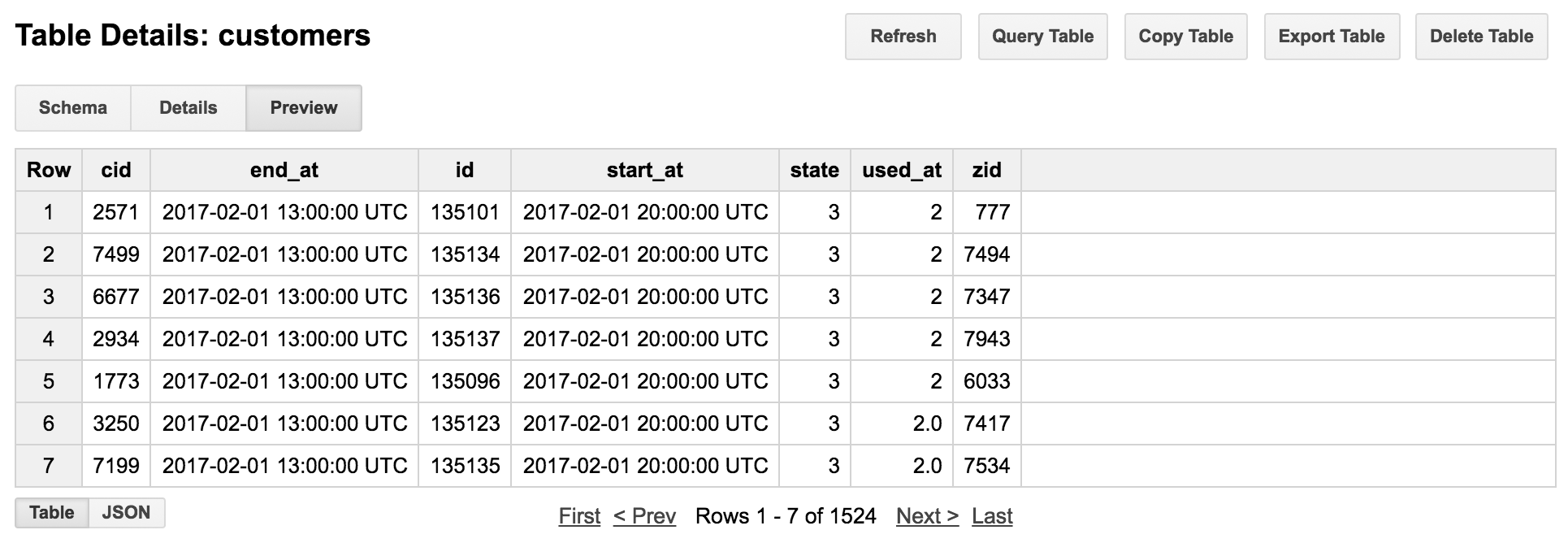
하지만 Preview를 통해서 보면 실제로는 숨겨져 있습니다
빅쿼리 내부에서 Partitioned 되어 있기 때문에 쿼리를 날릴때는 다음과 같이 날릴 수 있다
(내부에서는 파티션 되어있지만 바깥에서 봤을때는 하나의 테이블로 보임)
Tip) 날짜를 이용하여 데이터 분류하기 (위의 실습 예제 기준 월별 분류)
적절한 방법
start_at >= 2017-01-01 00:00:00
and start_at < ‘2017-02-01 00:00:00
적절하지 않은 방법 : 저 1초 사이에 데이터때문에 문제가 생길 수 있음
start_at >= 2017-01-01 00:00:00
and start_at < ‘2017-01-31 11:59:59
이 두번째 포스팅에서는 Embulk와 Shell Script 그리고 Rundeck을 이용하여 자동으로 배치 처리하고 관련하여 모니터링 할 수 있는 방법에 대해서 실습을 해 볼 예정 입니다