최근에 Google Cloud에 큰 관심을 가지면서 자연스럽게 BigQuery에 자연스럽게 관심을 가지게 되었습니다
그래서 이번에는 스터디를 하면서 알게된 Embulk를 통해서 BigQuery에 데이터를 넣는 방법을 포스팅 해보겠습니다
MySQL에서 BigQuery로 데이터 넣기
만약 Embulk를 처음 쓴다면 Embulk 설치 및 기본 사용법 를 확인해보고 간단한 사용법을 확인해보면 좋습니다
Embulk는 관련 플러그인을 설치하고 yml파일 에 설정만 하면 됩니다
먼저 플러그인부터 설치해보도록 하겠습니다
$ embulk gem install embulk-input-mysql # MySQL에서 데이터를 읽기 위한 플러그인
$ embulk gem install embulk-output-bigquery # BigQuery에 데이터를 넣기 위한 플러그인
Embulk 에서 BigQuery를 쓰면 데이터가 중간에 연결이 끊길수도 있고 그래서 안정성을 위해 다음과 같은 과정을 합니다
Embulk 정말 좋은거 같아요! 알아서 안정성관련된 부분까지 처리를 다 해주네요
- Embulk -> GCS(Google Cloud Storage)에 csv생성
- GCS의 csv에서 BigQuery로 임시 테이블 만듦
- 임시 테이블에서 실제 테이블로 데이터 로딩
그래서 설정에서 gcs_bucket 부분을 설정 합니다
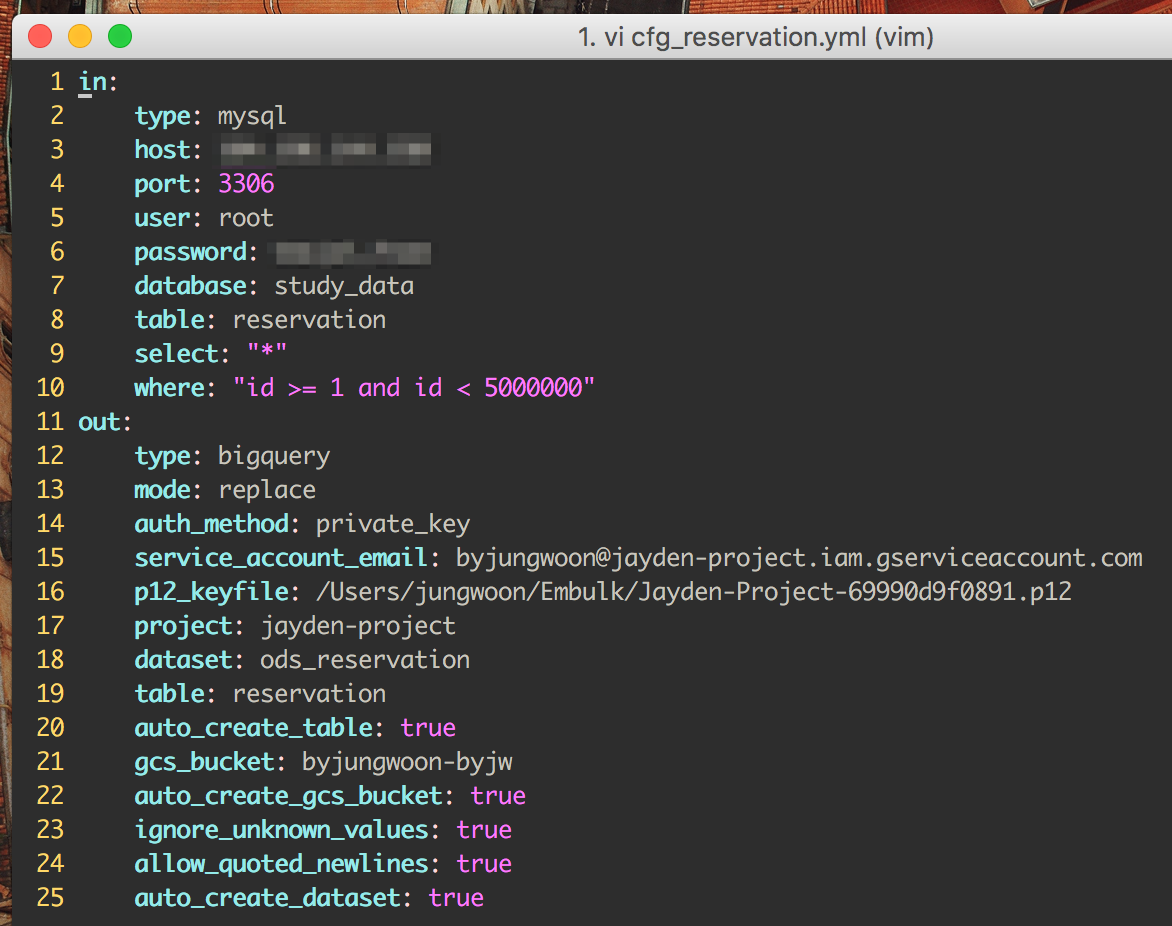
우선 완성된 yml 파일을 먼저 보여드리고 각각 하는 방법을 설명 드리겠습니다
in:
type: mysql
host: 111.111.111.111 # DB 서버 주소
port: 3306
user: root # DB 아이디
password: root # DB 비밀번호
database: test_database # DB 이름
table: test_table # 테이블 명
select: "*" # 가져올 데이터
where: "id >= 1 and id < 5000000" # 조건식
out:
type: bigquery
mode: replace
auth_method: private_key
service_account_email: byjungwoon@jayden-project.iam.gserviceaccount.com # 구글 클라우드 서비스 계정 ID
p12_keyfile: /Users/jungwoon/Embulk/Jayden-Project-69990d9f0891.p12 # 구글 클라우드 비공개 다운받은 키 경로
project: jayden-project # 구글 클라우드 프로젝트명
dataset: reservation # 빅쿼리 데이터셋
table: reservation # 빅쿼리 테이블명
auto_create_table: true # 스키마를 안만들어져 있으면 자동으로 만들어주게끔 설정
gcs_bucket: byjungwoon-byjw # Google Cloud Storage 버킷 이름
auto_create_gcs_bucket: true # 만약 Google Cloud Storage 버킷이 없으면 생성
ignore_unknown_values: true # 알 수 없는 값이 들어왔을때 무시
allow_quoted_newlines: true # quote가 들어올때 새로운 라인 생성
auto_create_dataset: true # 빅쿼리에 미리 데이터셋이 만들어져 있지 않으면 자동으로 생성
실제 캡처 화면
이제 Google Cloud 쪽에 있는 데이터 가져오는 방법을 배우도록 하겠습니다
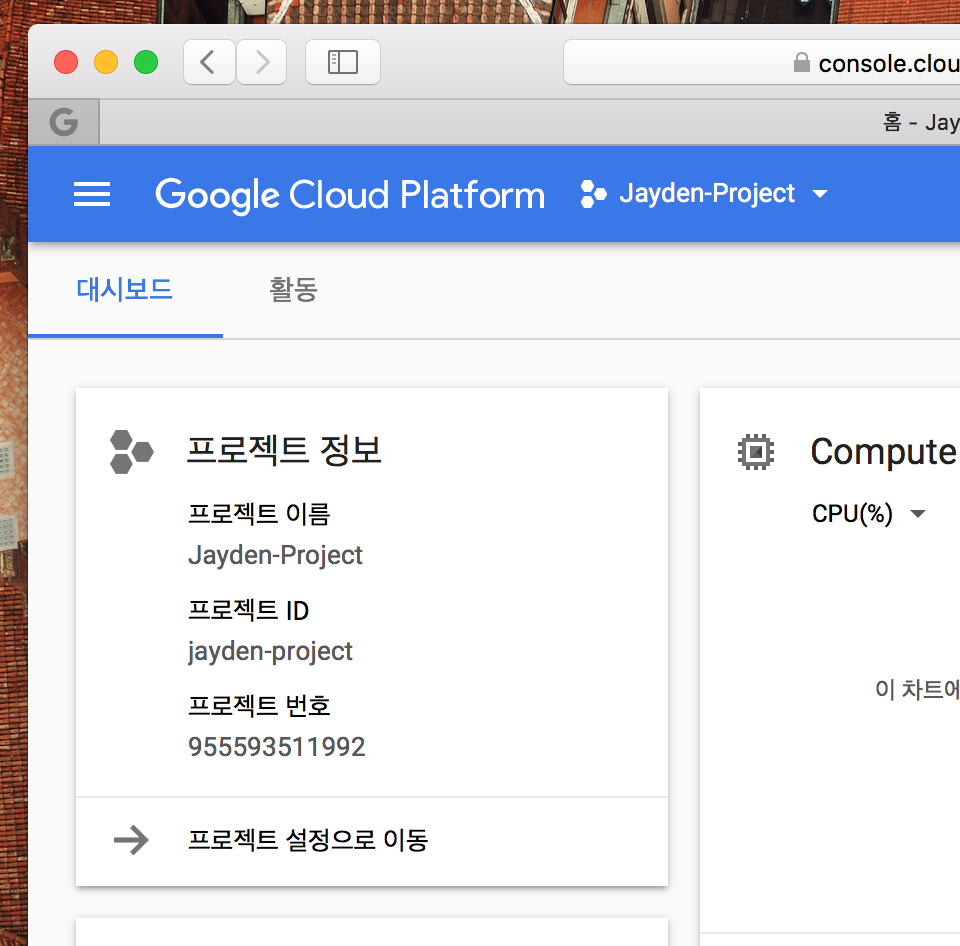
일단 정보를 가져오기 위해서 Google Cloud Platform에 들어갑니다
그럼 대시보드에서 프로젝트 ID를 알 수 있습니다
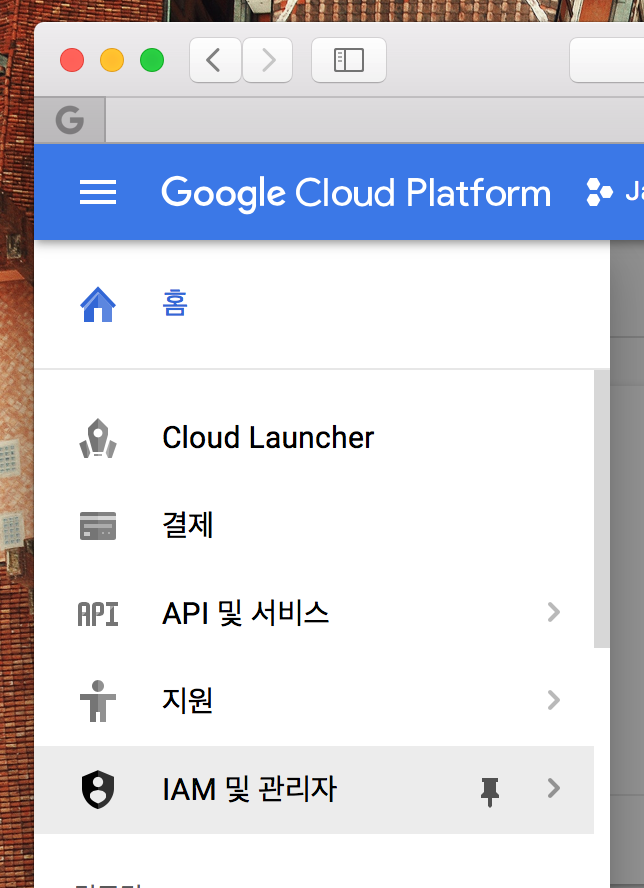
이제 서비스를 이용할 수 있는 권한을 받기 위해 좌측 상단의 메뉴를 눌러서 IAM 및 관리자로 들어갑니다
그럼 아래와 같은 화면이 나오는데 여기서 좌측의 서비스 계정에 들어갑니다
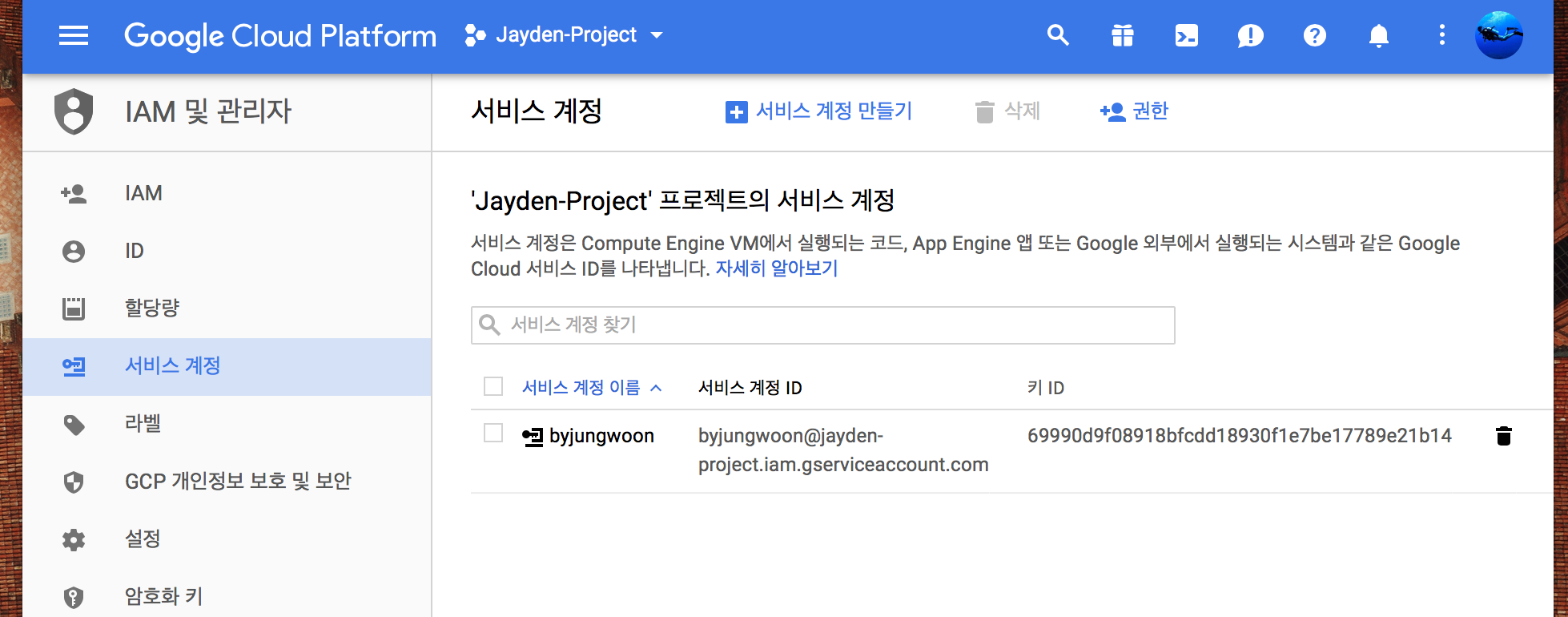
그 다음 사용할 키 만들기 를 눌러서 키를 다운로드 받습니다
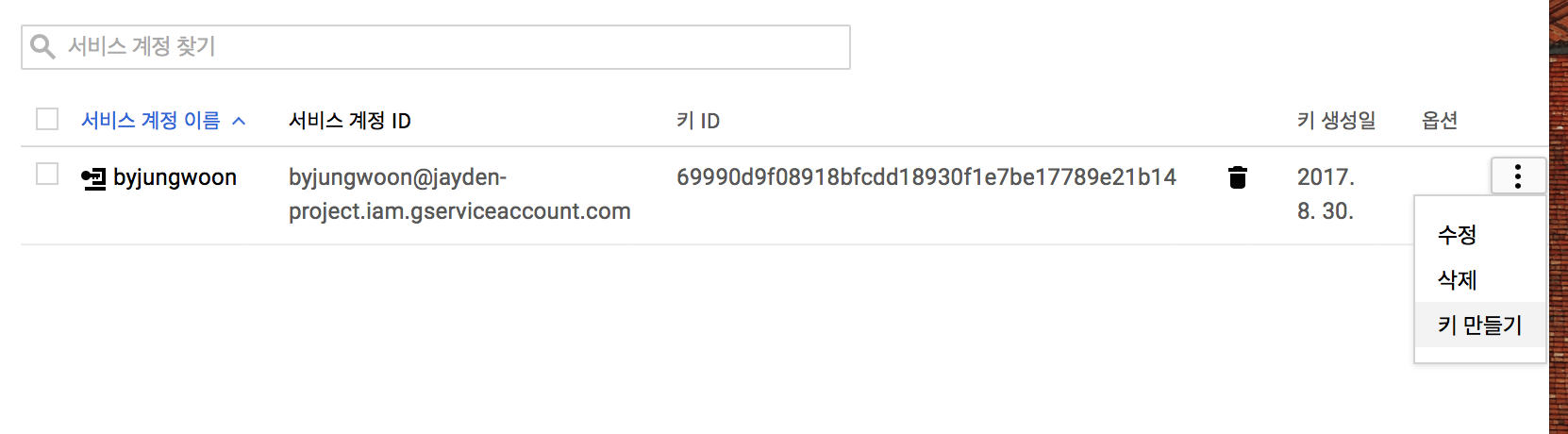
그럼 JSON으로 할건지 P12로 할건지 정하는데, 여기서는 P12로 선택합니다
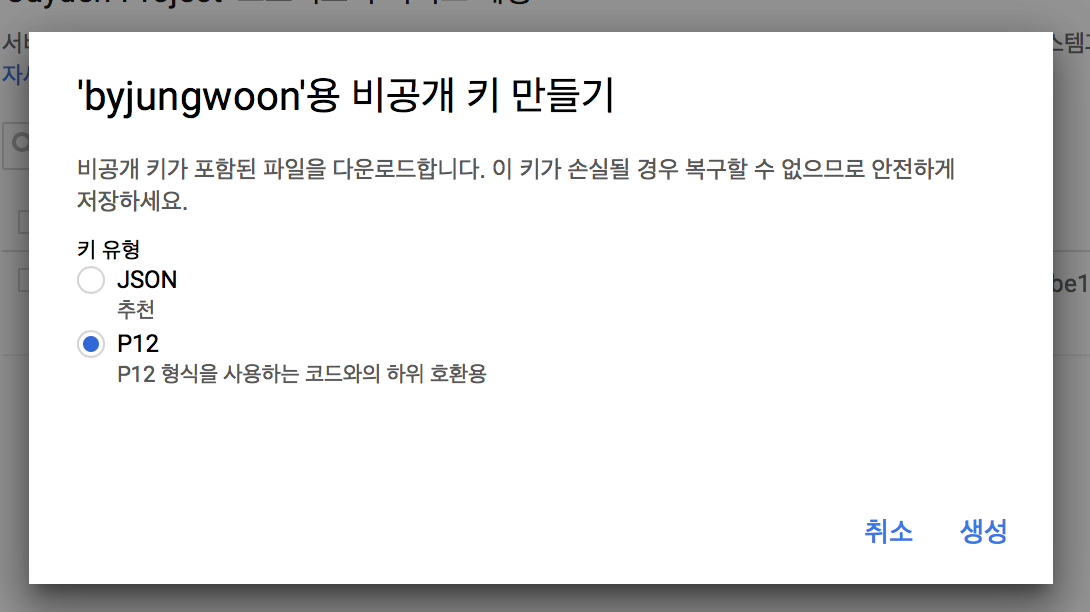
새 비공개 키를 만들건지에 대해서 나오는데 여기서는 설정없이 그냥 닫기를 누릅니다
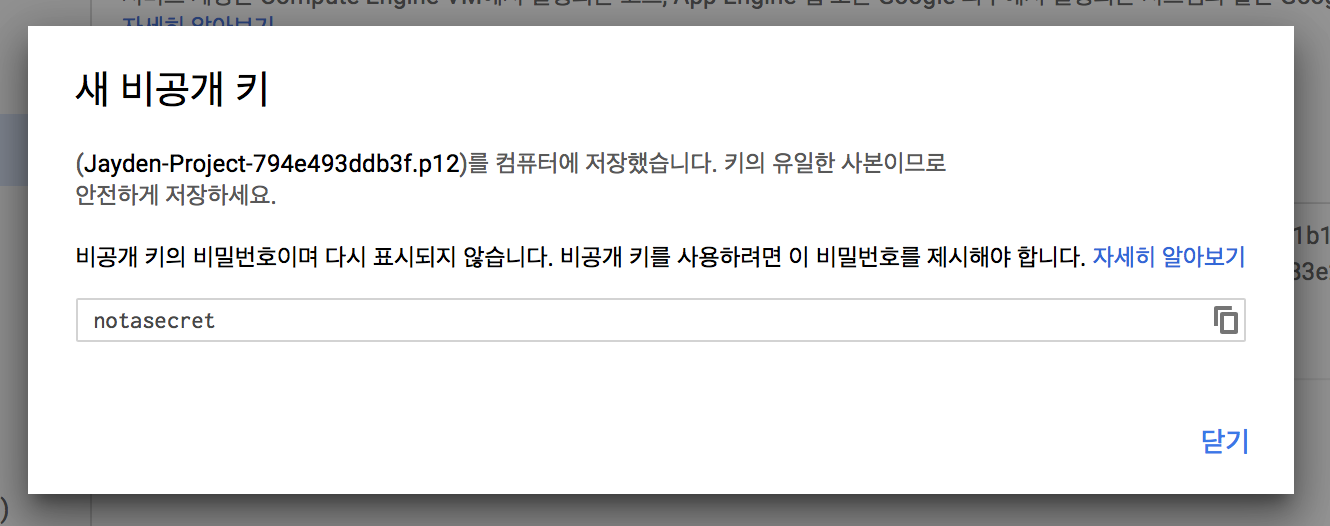
그럼 다음과 같이 p12 파일을 다운로드 받는데 이 파일의 위치를 위 빅쿼리 설정의 p12_keyfile에 넣어줍니다
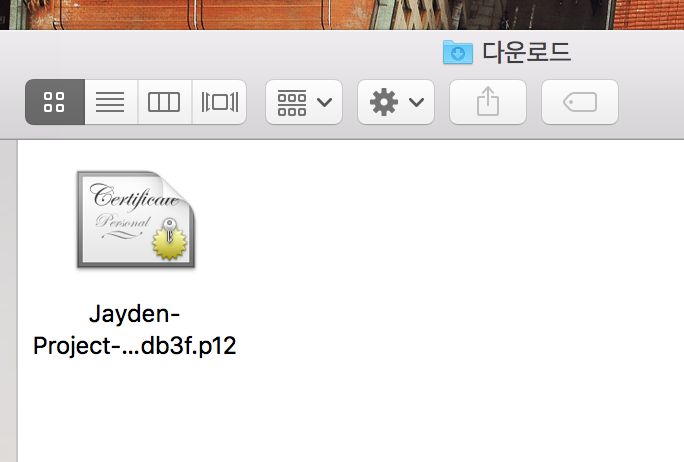
이제 빅쿼리 설정의 service_account_email 부분을 가져오겠습니다
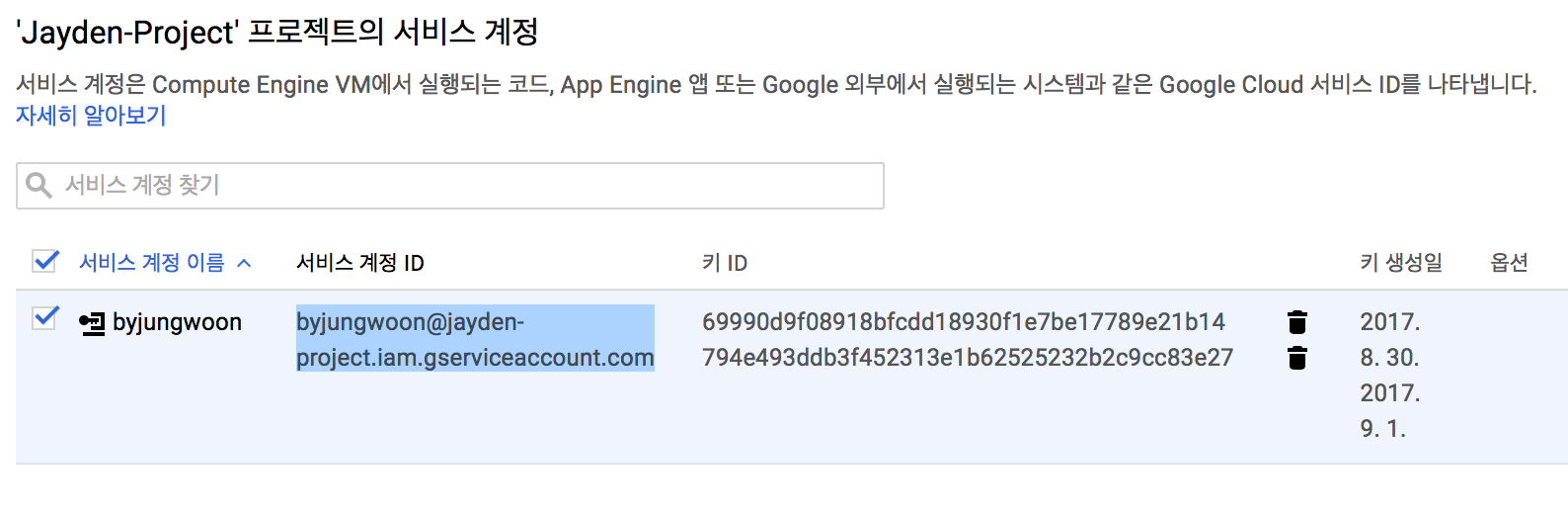
IAM 및 관리자에서 서비스 계정에 있는 서비스 계정 ID를 복사해서 설정에 넣습니다
왜 email이라 쓰여있는데 서비스 계정 ID를 쓰는지 모르겠네요
Bucket을 만들기 위해서 메뉴에서 Storage를 누릅니다
브라우저로 들어가서 상단에 버킷 생성을 누릅니다
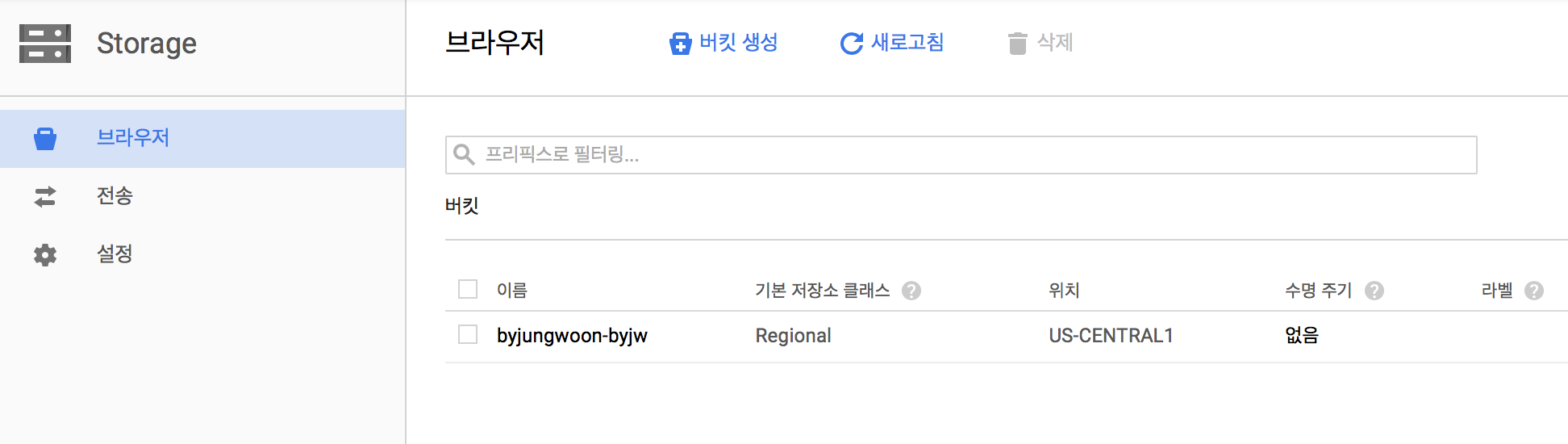
다음과 같이 나오면 이름을 넣고 기본 저장소 클래스를 선택하고 만들기 버튼을 누릅니다
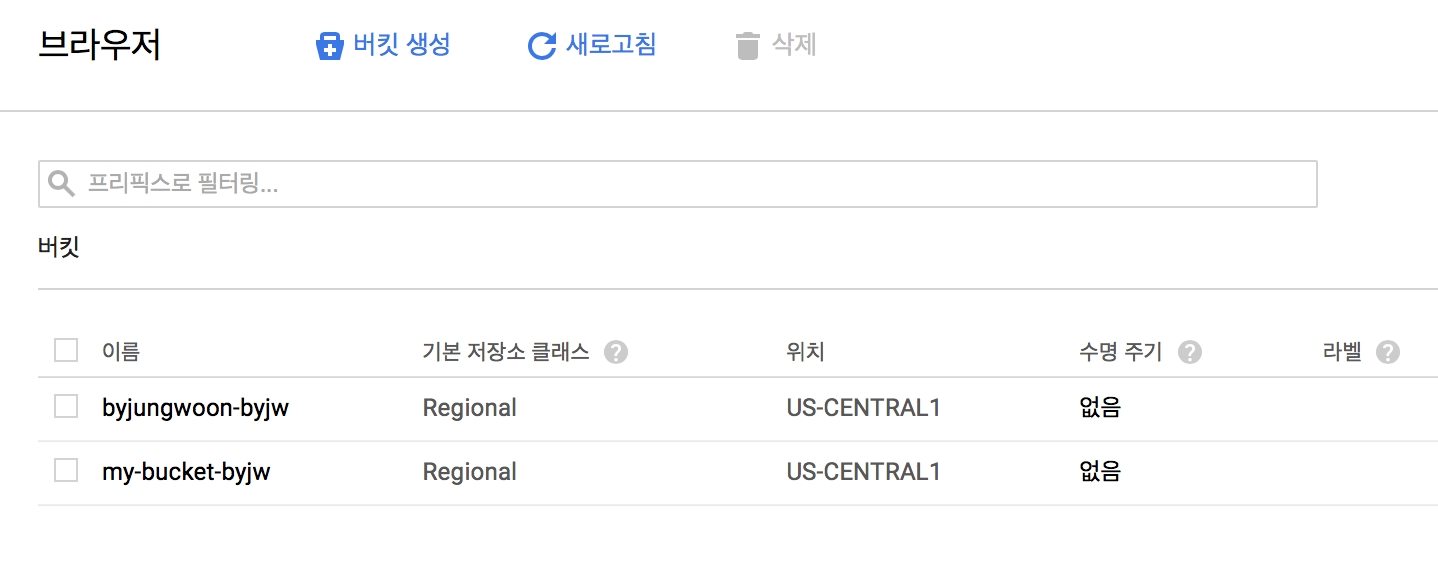
그럼 다음과 같이 생긴 리스트를 확인할 수 있습니다
이제 메뉴에서 BigQuery에 들어가서 DataSet을 만들어 보겠습니다

그럼 다음과 같이 나오는데요
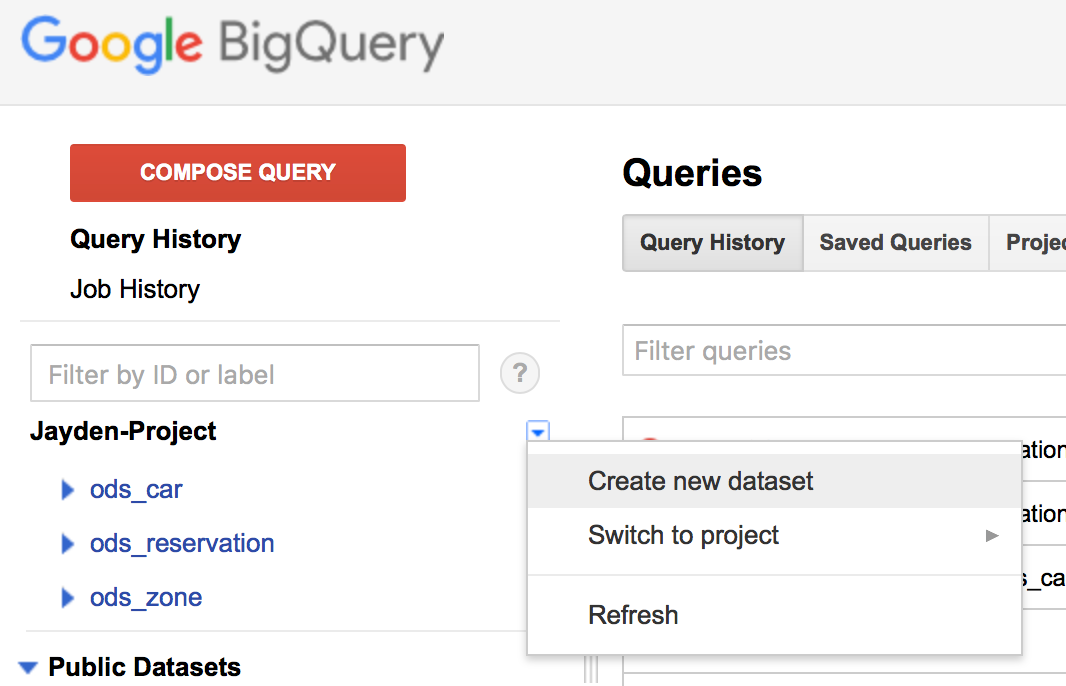
우측의 화살표를 눌러서 Create new dataset을 누릅니다
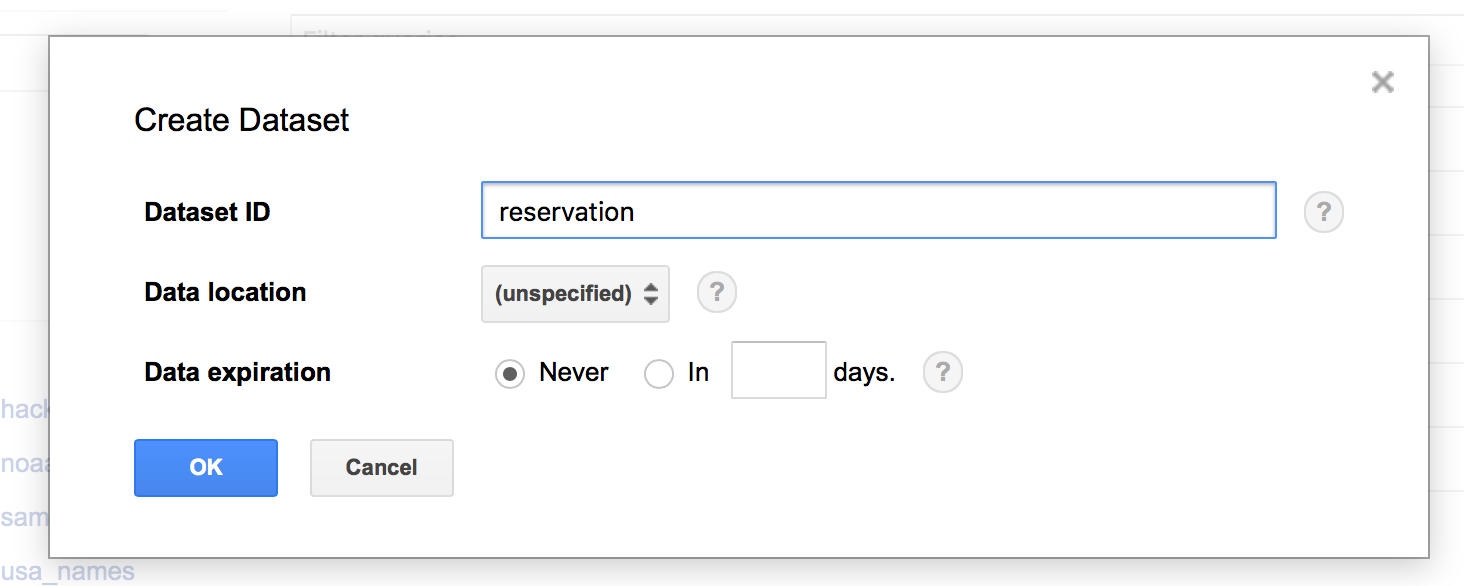
다음과 같이 나오면 Dataset ID를 넣고 OK를 누릅니다
이렇게 해서 전부 다 끝나면 다음과 같은 명령어를 입력하여 작업을 마무리 합니다
$ embulk run config.yml
여기는 개인적으로 삽질한 부분이라 추가로 넣어봤습니다
저는 처음에 아래와 같은 에러가 발생하였습니다 그래서 그 부분의 솔루션을 다시 한번 알려드리고자 합니다
"error_description" : "Required parameter is missing: grant_type"
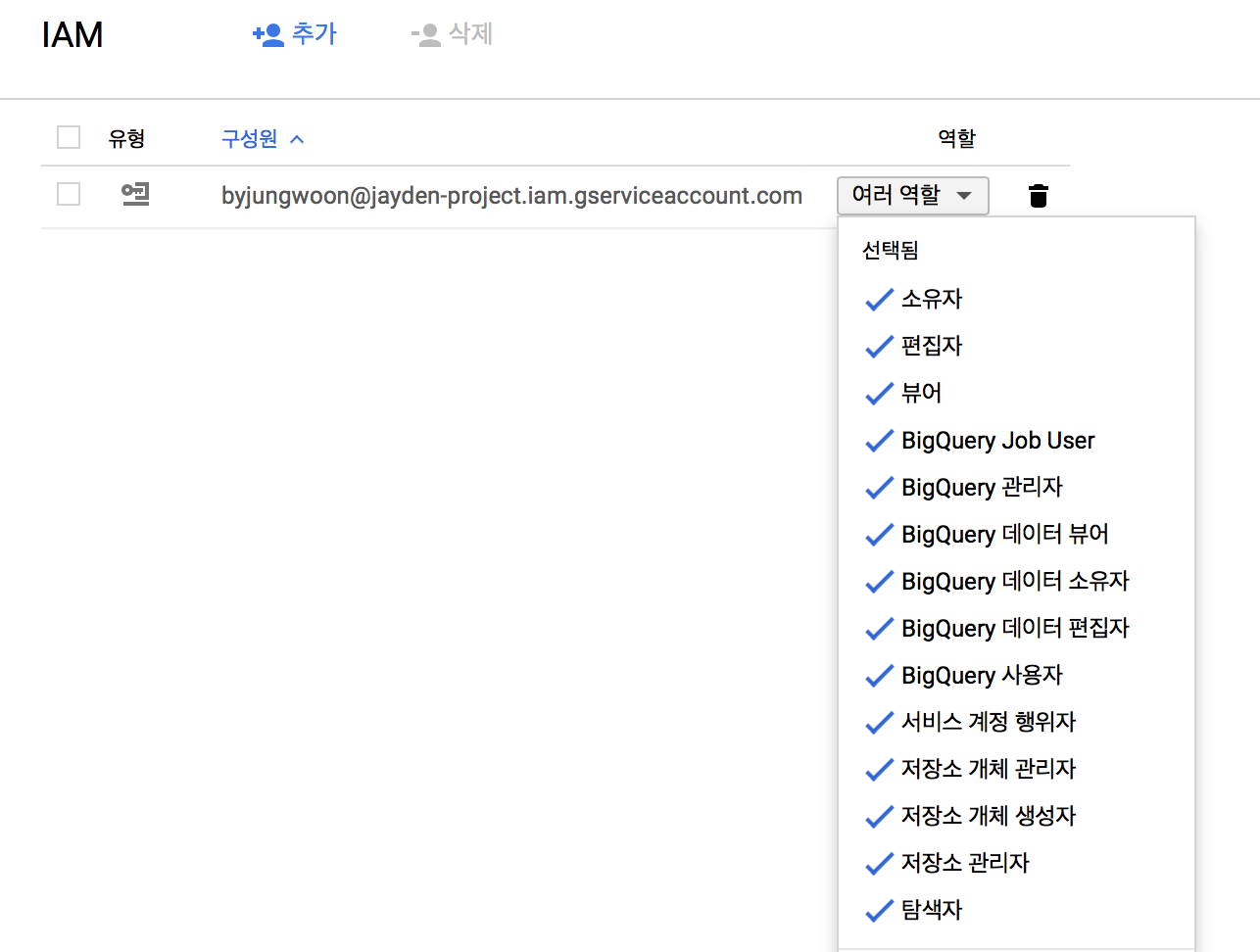
개인적으로 삽질을 했던 부분인데 권한이 없다고 Embulk 실행할때 문제가 발생할 수 있습니다 IAM 및 관리자 -> IAM 에 들어가서 서비스 계정 ID를 넣어서 검색을 합니다
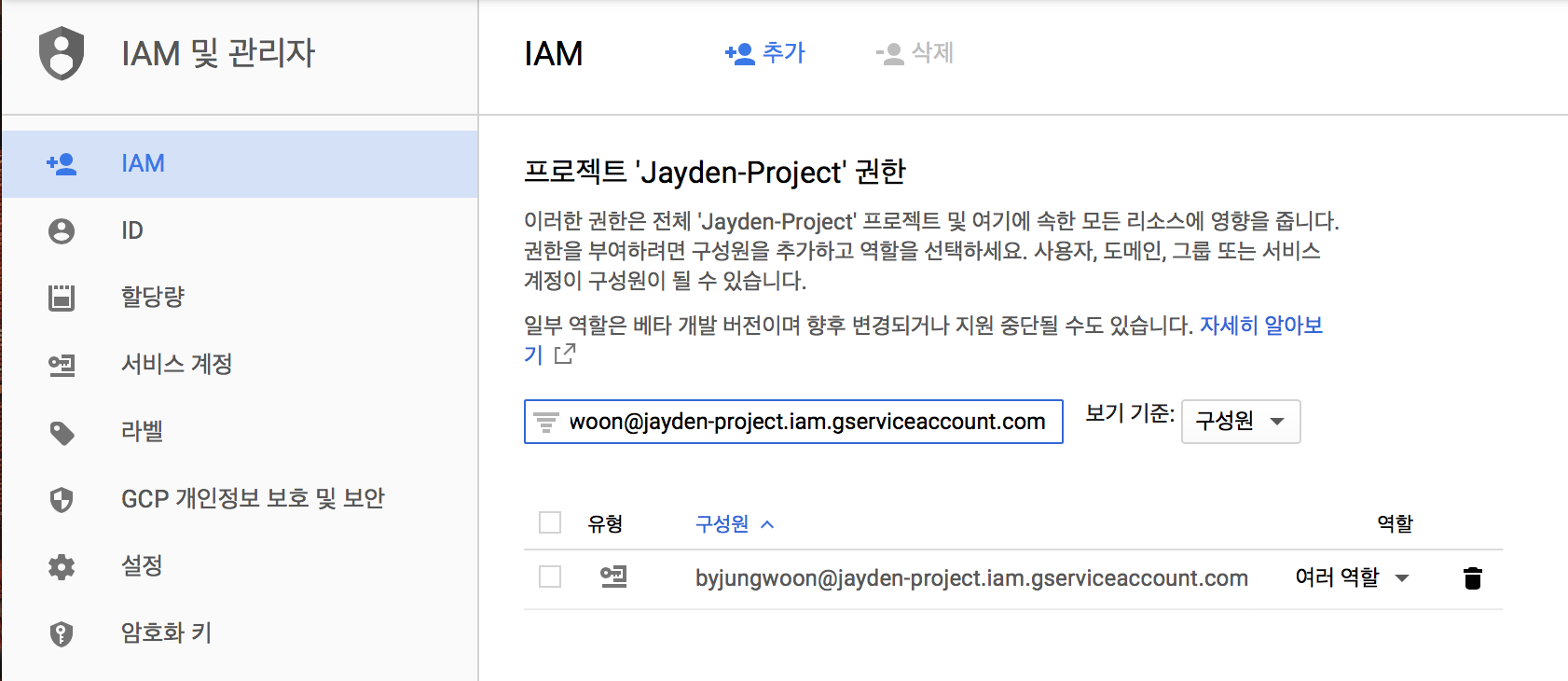
우측에 있는 역할을 눌러서 역할이 있는지 확인을 합니다 저 같은 경우는 다음과 같이 다 주니까 오류가 해결이 되었었습니다