Sqoop으로 MySQL 데이터 가져오는 방법에 대해 알아보겠습니다.
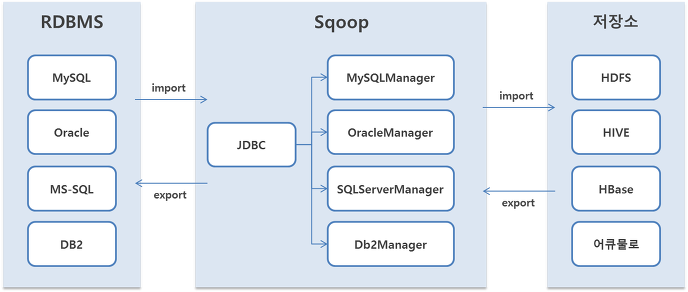
Sqoop
RDBMS에 있는 데이터를 특별한 전처리 없이 곧바로 HDFS에 적재하거나, 반대로 HDFS에 저장된 데이터를 RDBMS로 제공해야할때 도와주는 프로젝트
Sqoop의 버전
- 스쿱1 클라이언트 : CLI 기반으로 스쿱 명령을 실행하는 초기 버전
- 스쿱 2 : 스쿱 서버를 두고 스쿱 클라이언트가 API를 호출하는 방식
Sqoop 요소
- Sqoop Client : 하둡의 분산 환경에서 HDFS와 RDBMS 간의 데이터 임포트 및 익스포트 기능을 수행하기 위한 라이브러리로 구성
- Sqoop Server : 스쿱 2의 아키텍처에서 제공되며, 스쿱 1의 분산된 클라이언트 기능을 통합해 REST API로 제공
- Import/Export : 임포트 기능은 RDBMS의 데이터를 HDFS로 가져올때 사용하며, 반대로 익스포트 기능은 HDFS의 데이터를 RDBMS로 내보낼 때 사용
- Connectors 임포트 및 익스포트에서 사용될 다양한 DBMS의 접속 어댑터와 라이브러리를 제공
- Metadata : 스쿱 서버를 서비스하는 데 필요한 각종 메타 정보를 저장
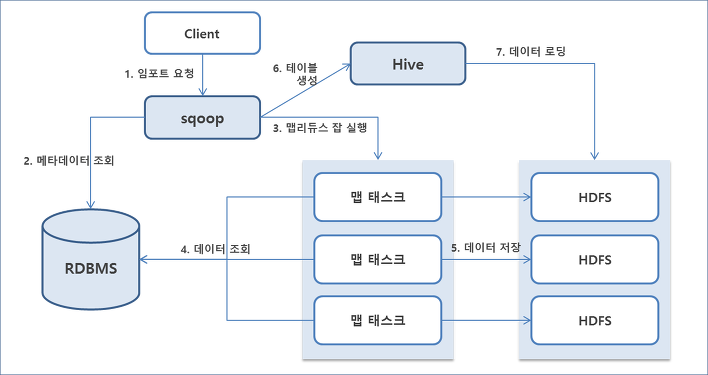
Sqoop Architecture
Sqoop Import
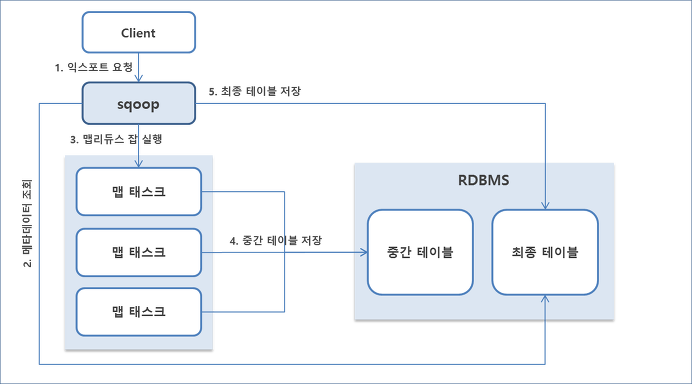
Sqoop Export
실습
목표 : 스쿱을 이용해서 MySQL로부터 가져온 데이터를 HDFS와 Hive에 Import 하기
Database Informations
Server : MySQL
IP : 111.111.111.111
Port : 3306
User Id : jungwoon
DB : HELLO_SOCIAL
TABLE
- post_info (3만 5천+)
- post_engager (1100만건)
import MySQL -> HDFS
$ sqoop import —connect jdbc:mysql://111.111.111.111:3306/HELLO_SOCIAL —username jungwoon -P — table post_info -m 1
정상적으로 가져오게 되면 아래와 같이 해당 테이블 이름으로 HDFS에 파일이 생기는것을 확인할 수 있다.

import MySQL -> HIVE
$ sqoop import --connect jdbc:mysql://111.111.111.111:3306/HELLO_SOCIAL --username kclick -P —post_engager --hive-import
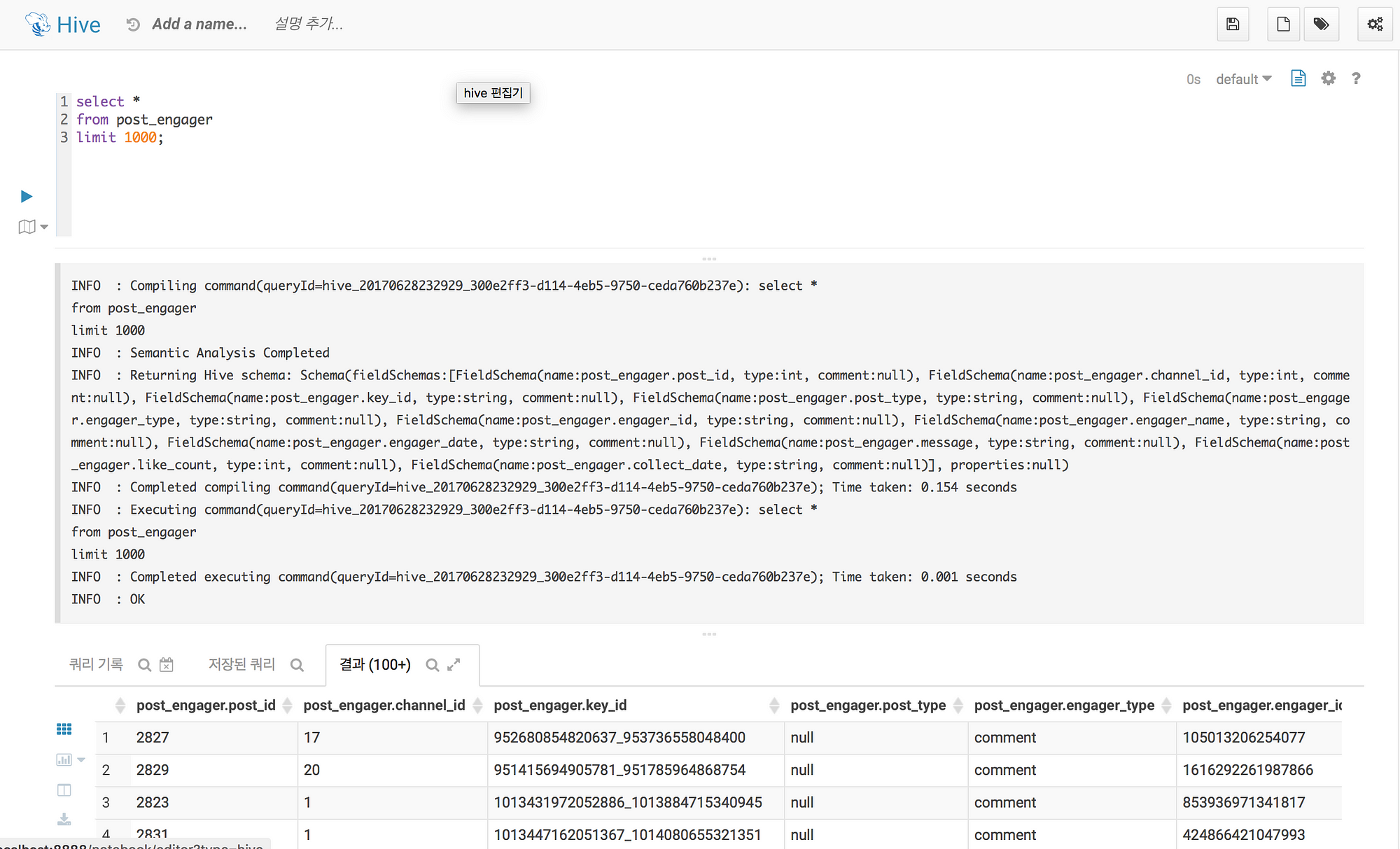
정상적으로 가져오게 되면 아래와 같이 Hue를 통해서 Hive 쿼리를 날릴 수 있다.