Google의 DataFlow에 대해 알아보겠습니다.
Google DataFlow 알아보기
다음 내용들은 조대협님의 블로그의 내용들을 공부하면서 정리한 내용입니다.
Concept
개념
Apache Spark나 Apache Flink와 유사한 형태로 데이터를 처리하는 프레임워크로 아래와 같은 컨셉
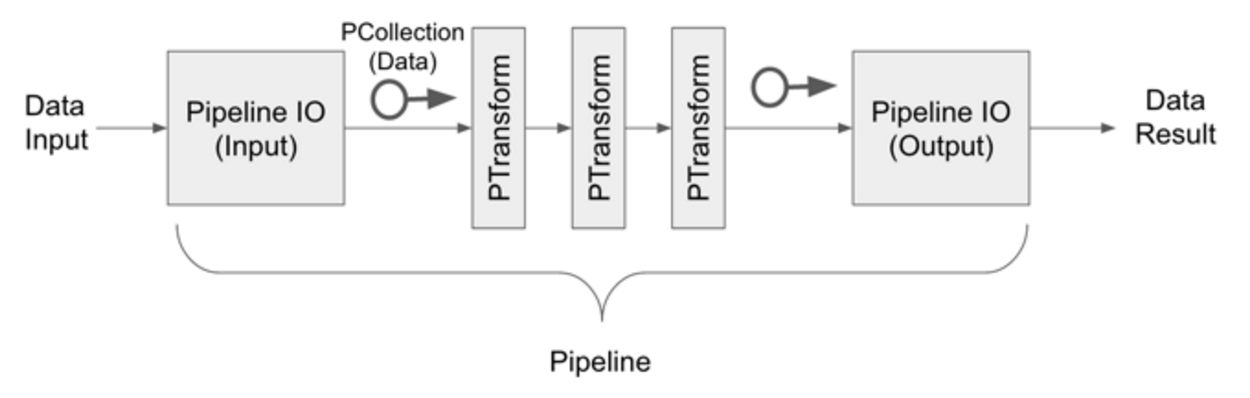
개별 Pipeline 흐름
- 데이터 입력
- Pipeline I/O에 의해서 데이터 input
- PTransform으로 변환 및 가공
- Pipeline I/O에 의해서 데이터 output
- 데이터 출력
예제
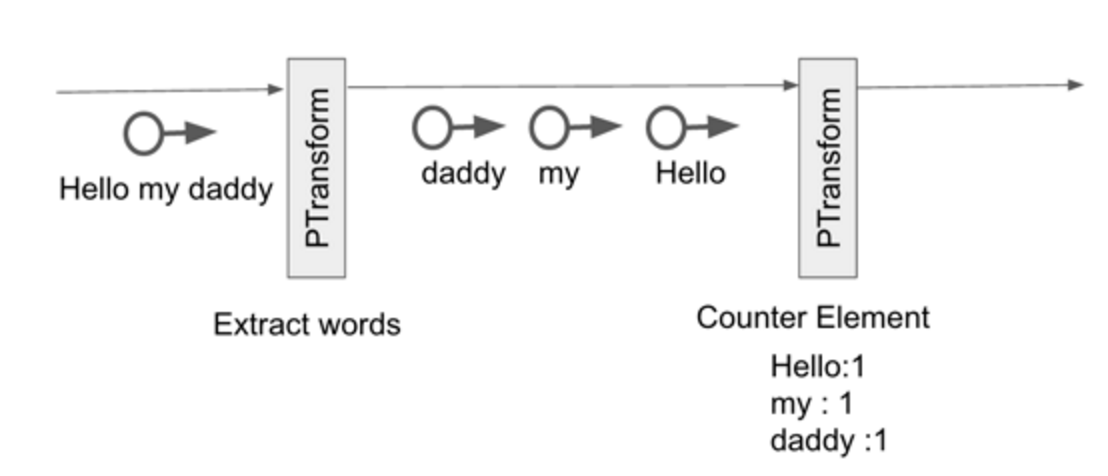
- Hello my daddy 라는 문자열 입력
- PTransform에 의해 단어를 쪼갬
- PTransform에 의해 단어 카운팅
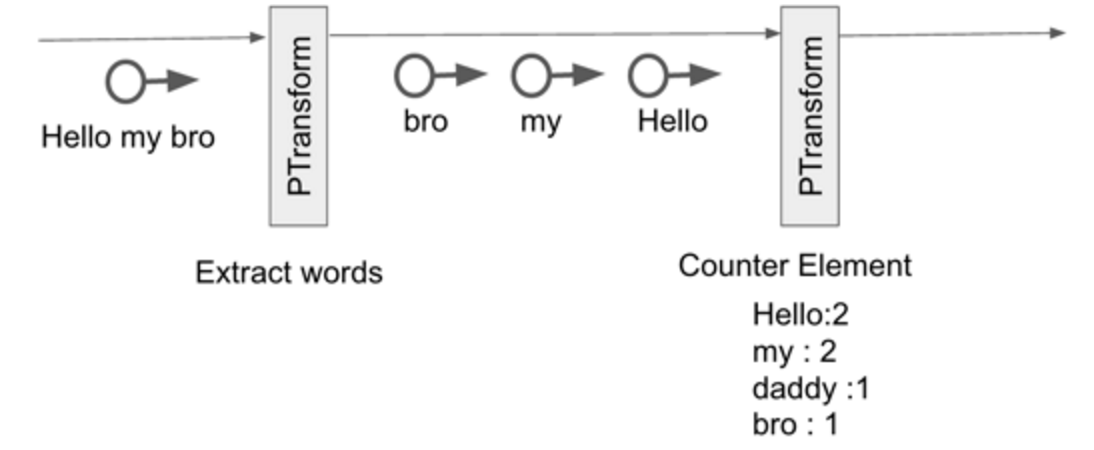
- Hello my bro라는 문자열 입력
- PTransform에 의해 단어를 쪼갬
- PTransform에 의해 단어 카운팅
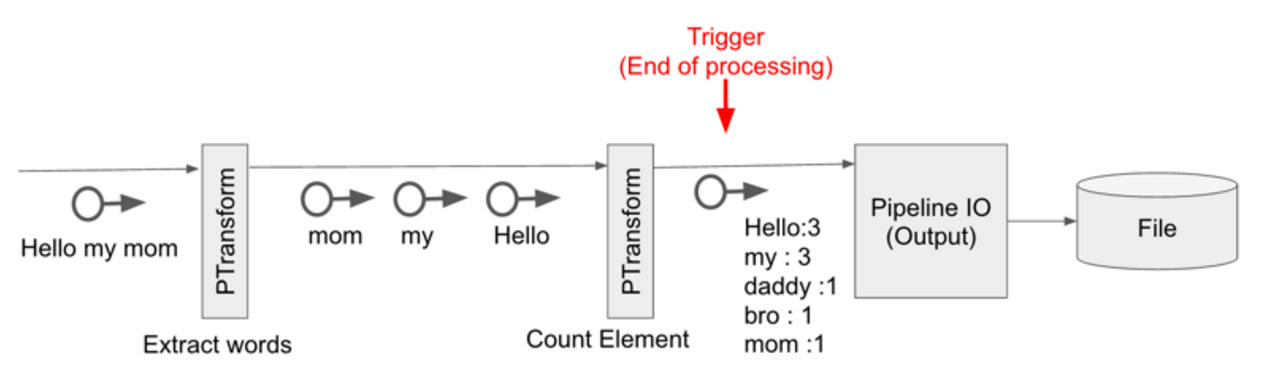
- Hello my mom라는 문자열 입력
- PTransform에 의해 단어를 쪼갬
- PTransform에 의해 단어 카운팅 및 기존의 값과 누적하여 Pipeline I/O르 통해 파일에 쓰게 됨
배치와 스트리밍 처리
dataflow는 위에서 설명한 파이프라인의 개념을 배치와 스트리밍 처리 두 가지 개념 모두로 지원해서 처리가 가능
윈도우의 개념
스트리밍 데이터는 계속해서 들어오는데, 언제 결과를 내보내야 할까? 개별 데이터를 변환해서 저장하는 경우는 개별 데이터 처리가 끝나고 하나씩 저장하지만, 합이나 평균과 같은 처리를 하는 경우에는 어느 기간 단위로 해야할까? 이를 위해서 윈도우라는 개념을 이용한다.
예를 들어, “1시-1시 10분”까지 들어온 문자열에 대해서 단어를 카운트해서 출력해주는 기능 같이 작은 시간 기간의 단위를 가지고 계산 하는 방법이며, 이 시간 단위를 윈도우(Window)라고 한다.
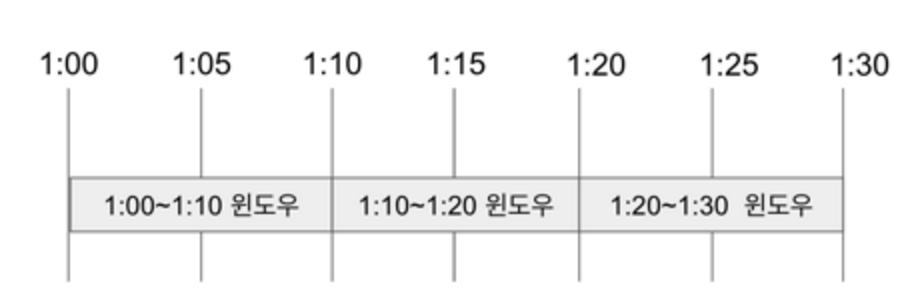
Fixed Window
“1시-1시 10분”, “1시 10분-1시 20분” 같이 고정된 크기를 가지는 윈도우 개념
Sliding Window
Fixed Window와 같이 상대적인 시간의 개념을 가지면서, 다른 윈도우들과 중첩되는 윈도우
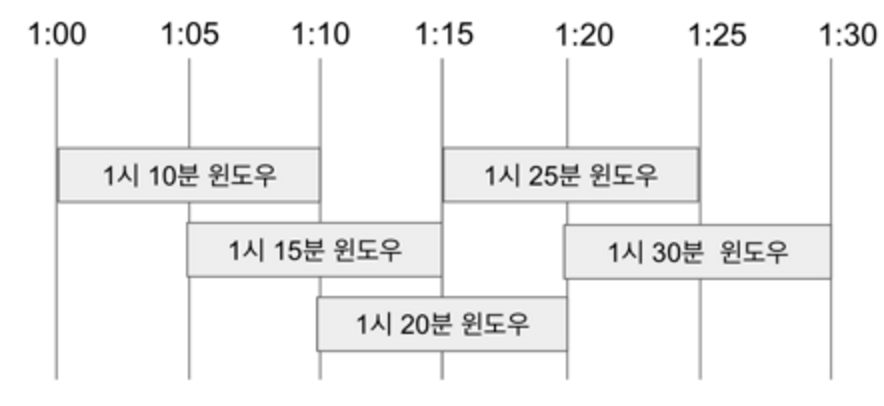
그림과 같이 1:10의 윈도우는 1:10의 10분전인 1시에서 부터, 현재 시간 까지인 1:10까지 값을 읽어서 처리하고 윈도우가 끝나는 시점인 1:10분에 그 값을 저장한다. 윈도우의 간격은 5분 단위로, 1:15에는 1:15의 10분전인 1:05부터 현재 시간인 1:15까지 들어온 데이타에 대해서 처리를 하고 그 결과 값을 1:15에 저장한다.
Session Window
세션이란 사용자가 한번 시스템을 사용한 후, 사용이 끝날때 까지의 기간을 정의한다. 세션의 종료는 데이터가 들어온 후 일정 시간동안 해당 사용자에 대한 데이터가 들어오지 않으면 세션이 종료된 것으로 판단한다.
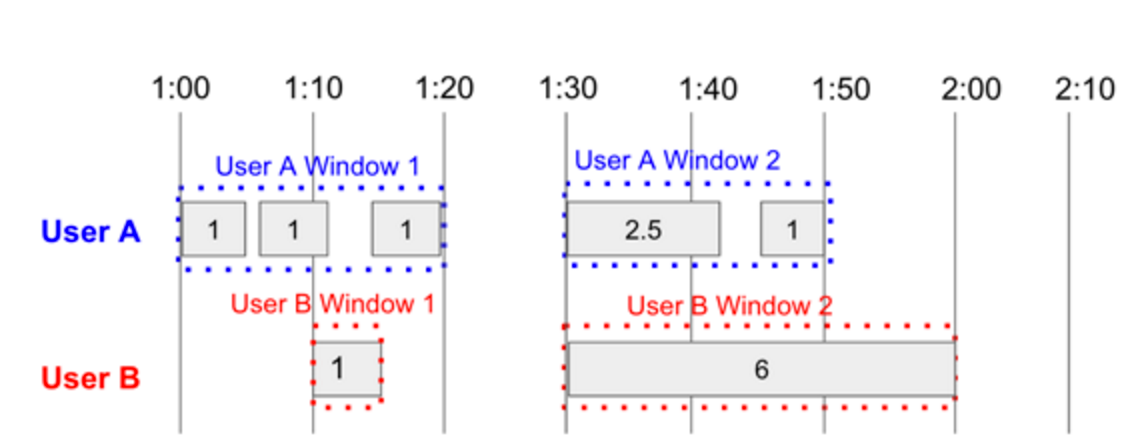
위의 예제에서는 User A와 User B의 데이터고 들어오고 있다고 가정을 하고, 세션 타임 아웃을 10분으로 정의했다.
User A는 1:00에 첫 데이터가 들어오고 1:00-1:10 사이에 두번째 데이터가 들어왔고, 1:10-1:20 사이에 세번째 데이터가 들어온 후, 네번째 데이터는 10분이 지난 후에 들어왔다. 그래서 1:00-1:20 까지가 하나의 세션이 되고, 이것이 User A의 세션 윈도우가 된다.
네번째 데이터는 새로운 윈도우로 처리가 되는데, 1:30-1:40 사이에 네번째 데이터가 들어왔고 1:40-1:50사이에 다섯번재 데이터가 들어온뒤 데이터가 들어오지 않았다. 그래서 이게 User A의 두번째 윈도우가 된다.
User B의 경우는 1:10에 하나가 들어고 10분간 들어오지 않았기 때문에 이가 하나의 윈도우가 되고 1:30-2:00 사이에 두번째 데이터가 들어오고 그 뒤로 들어오지 않았기 때문에 이가 두번째 윈도우가 된다.
Session Window는 Fixed Window나, Sliding Window와 다르게 User A, User B와 같이 사용자 단위와 같은 어떤 키에 의해서 개별적으로 위도우를 처리하기 때문에, 특정 키에 종속된 윈도우만을 갖게 된다.
Trigger
트리거는 처리중인 데이터를 언제 다음 단계로 넘길지를 결정하는 개념이다. 특히 윈도우의 개념과 같이 생각하면 좋은데, 윈도우는 일반적으로 윈도우가 종료되는 시간에 그 데이터를 다음 Transform으로 넘기게 된다.
여기서 이런 의문이 생길 수 있다.
"윈도우의 크기가 클때 (예를 들어 한시간), 한시간을 기다려야 데이터를 볼 수 있는 것인가? 그렇다면 한 시간 후에 결과를 본다면 이것을 실시간 분석이라고 할 수 있는가?"
이를 위해 트리거의 개념이 나온다. 예를 들어 윈도우가 끝나지 않더라도 현재 값을 다음 Transform으로 넘겨서 결과를 볼 수 있는 개념으로 윈도우가 종료되기 전에도 실시간으로 결과를 업데이트 할 수 있게 된다.
Trigger의 종류
- Time Trigger : 일정 시간 주기로 트리거링 해주는 트리거 ex) 윈도우 시작 후 2분 후
- Element Count Trigger : 개수 기반으로 트리거링 해주는 트리거 ex) 데이터 100번 이상마다
- Punctuations Trigger : 특정 데이터가 들어오는 순간에 트리거링 해주는 트리거
Trigger 조합
- AND : 두개의 조건이 모두 만족해야할때 이용
- OR : 둘 중 하나가 만족할때 이용
- Repeat : 반복적으로 트리거 실행시 이용
- Sequence : 등록된 트리거를 순차적으로 실행시 이용
Trigger 데이터의 누적
- Accumulating : 트리거링 할때마다 윈도우내에서 값을 누적하여 모두 리턴
- Discard : 이전 값은 더이상 리턴하지 않고 그 다음 트리거링의 값만을 리턴
데이터 지연에 대한 처리 방법
실시간 데이터 분석은 특성상 데이터의 전달 시간이 중요한데, 환경에 따라서 데이터의 실제 도달 시간이 들쭉날쭉하다. 이에따른 데이터 도착 순서나 지연등이 발생하는데, 이에 대한 처리가 필요하다.
- Event Time : 실제 데이터가 발생한 시간
- Processing Time : 서버에 데이터가 도착한 시간
이에 따른 상관 관계를 그래프로 그려보면 다음과 같다.
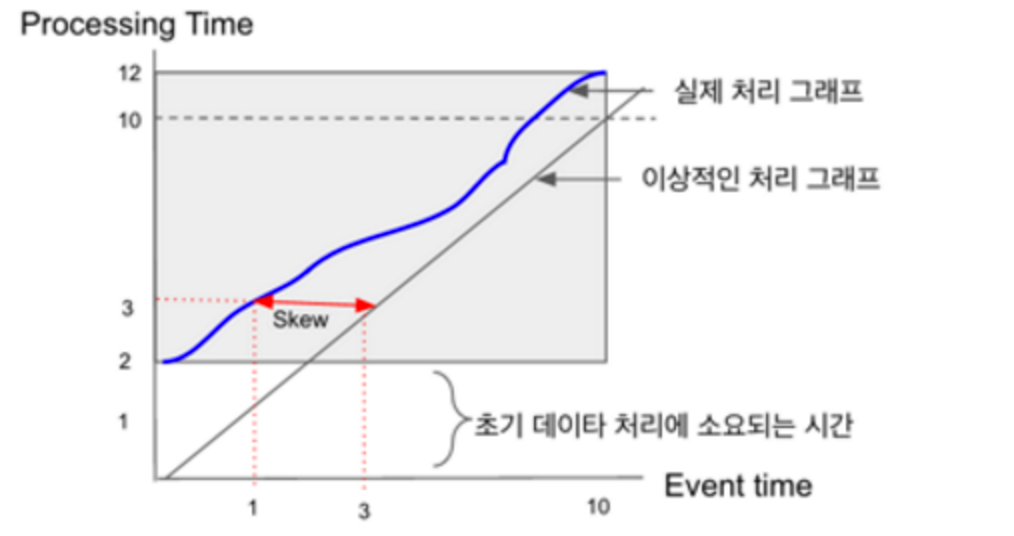
가장 이상적인 결과는 이벤트 타임과 프로세싱 타임이 동일한 것이겠지만 불가능하고, 위의 그림처럼 이벤트 타임보다 프로세싱 타임이 항상 늦게 되고, 이벤트 타임과 프로세싱 타임의 차이는 매 순간 다르게 된다. 이에 따라 도착 시간을 예측하는데 이를 Water Mark라고 한다.
Water Mark
실제 데이터가 시스템에 도착하는 시간을 예측하는 방법으로 보통 Buffering을 통해서 데이터가 들어오기 전까지 임시로 저장을 할 수 있으며, 데이터 지연을 기다리는 시간도 정의할 수 있다.
Dataflow Programming Model
구글 데이터플로우 프로그래밍 모델 컴포넌트는 다음과 같이 구성되어 있다.
- Pipeline : 전체 데이터 파이프라인을 정의
- PCollections : 데이터를 저장
- Pipeline I/O : 데이터를 외부저장소로부터 읽거나 쓰는 역할
- Transforms : 입력 데이터를 가공해서 출력해주는 역할
Transforms
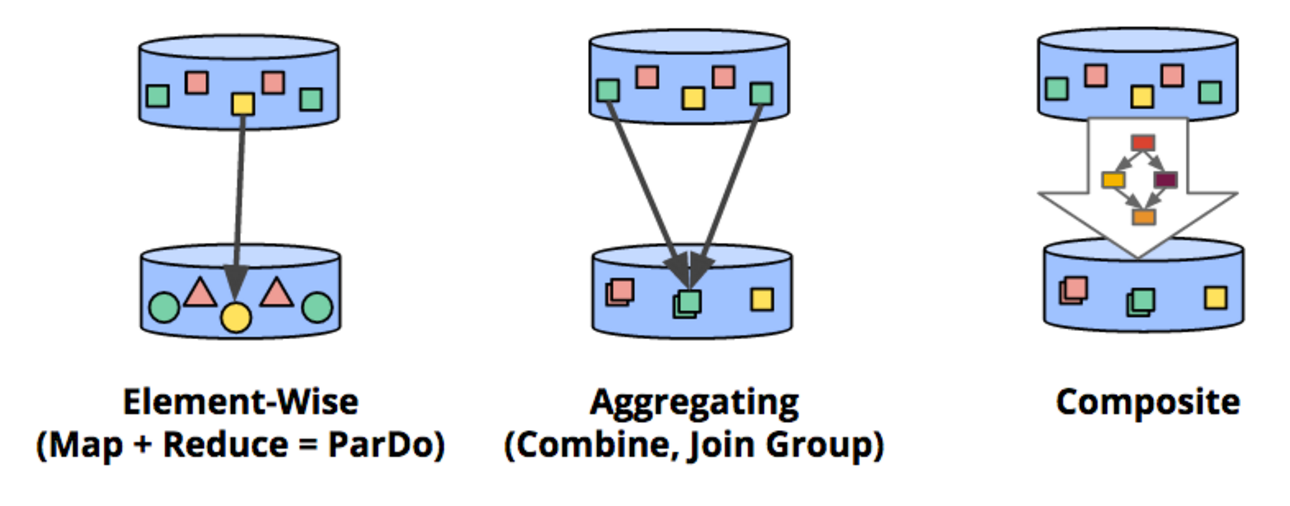
Element-Wise
개별 데이터 엘리먼트를 단위로 연산을 수행하는 것
ParDo 함수가 이에 해당하며, 하나의 데이터를 입력 받아서, 연산을 한 후, 하나의 출력을 내보내는 연산
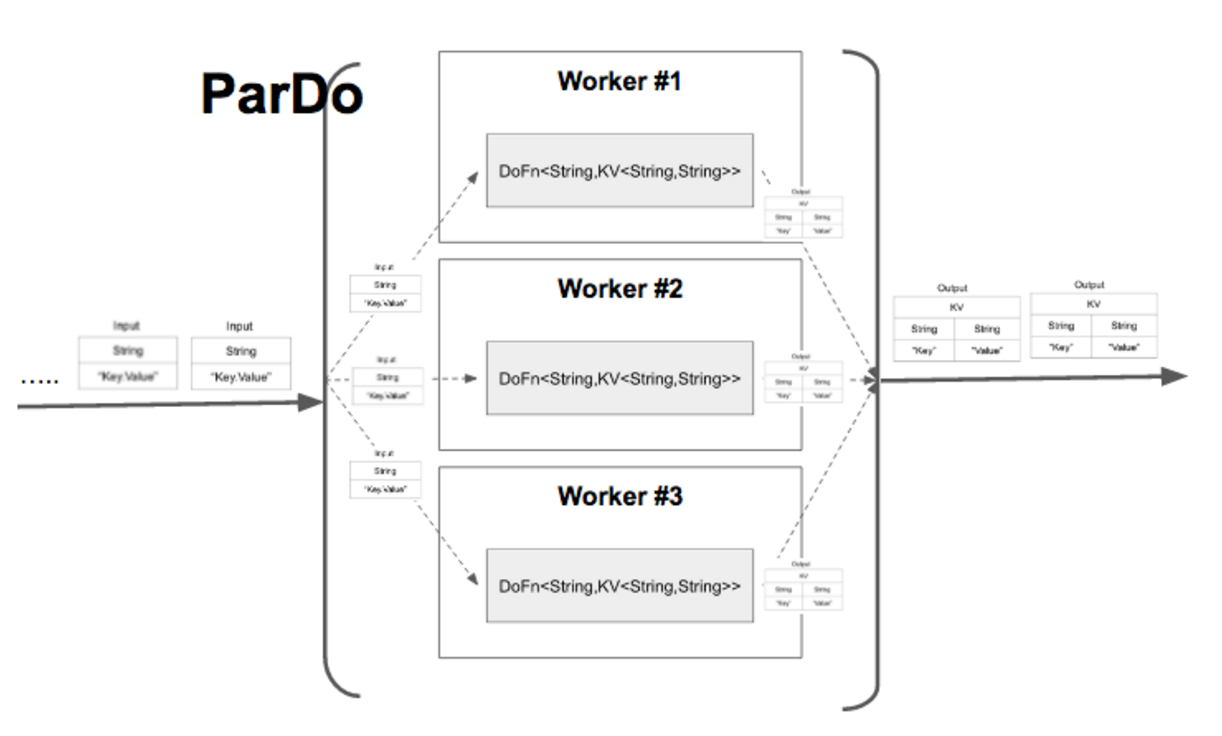
ParDo 함수는 DoFn으로 정의된 연산 로직을 병렬로 여러개의 프로세스와 스레드에서 나눠서 처리를 한다.
DoFn 클래스 포맷
static class MyFunction extends DoFn<{입력 데이터 타입},{출력 데이터 타입}> {
@Override
public void processElement(ProcessContext c) {
// do Something
}
}
DoFn 클래스를 상속 받아서 클래스를 정의하고, 클래스 정의시에 제네릭 타입으로 첫번째는 입력데이터 타입을 두번째는 출력 데이터 타입을 정의한다.
그리고 processElement 함수를 오버라이드해서 이 함수안에 연산 로직을 구현한다. 이때, ProcessContext를 인자로 받는데, 여기에는 입력 데이터를 포함하고 있다. 아래는 많이 쓰이는 메서드이다.
c.element() : 함수로 입력 데이터를 꺼낼 수 있음 c.output(결과) : 다음 파이프라인으로 넘김
이렇게 정의된 DoFn함수는 ParDo를 이용하여 파이프라인 상에서 병렬로 실행하고, ParDo는 파이프라인상에서 .apply 메서드를 이용해서 적용한다.
예제
p.apply(ParDo.named("toUpper").of(new DoFn<String, String>() {
@Override
public void processElement(ProcessContext c) {
c.output(c.element().toUpperCase());
}
}))
String 인자를 받아서 String 인자로 출력하는 DoFn 함수로 c.element()를 통해서 입력 데이터를 받아서 toUpperCase()를 이용해 대문자로 바꾸고 c.output()을 통해서 다음 파이프라인으로 넘겨주는 예제이다.
디테일한 예제
p.apply(Create.of("key1-Hello", "key2-World","key1-hello","key3-boy","key4-hello","key2-girl"))
.apply(ParDo.named("Parse").of(new DoFn<String, KV<String, String>>() {
@Override
public void processElement(ProcessContext c) {
StringTokenizer st = new StringTokenizer(c.element(),"-");
String key = st.nextToken();
String value = st.nextToken();
KV<String,String> outputValue = KV.of(key,value);
c.output(outputValue);
}
}))
Create.of를 이용하여 “Key-Value” 문자열 형태로 데이터를 생상한 후, 이 문자열을 읽어서 DoFn<String, KV<String, String> 클래스에서 이를 파싱하여 문자열을 Key Value 데이터형인 KV 데이터 형으로 변환하여 리턴하는 예제
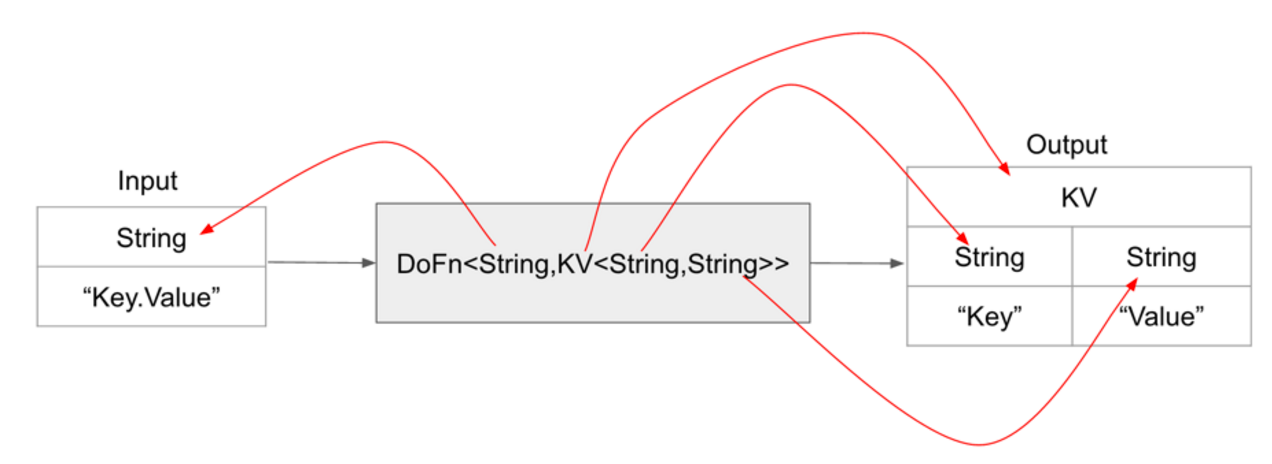
분석
- String 타입으로 “Key-Value”라는 형태의 문자열을 받음
- c.element()로 String 문자열을 꺼냄
- String Tokenizer를 이용하여 “-“를 분류 문자로 파싱
- 첫번째를 Key로 두번째를 Value로 저장
- c.output()을 이용하여 다음 파이프라인 컨포넌트로 값을 저장
시스템 내에서 수행되는 방법은 다음과 같이 ParDo에 의해서 DoFn 클래스가 여러개의 워커에 의해서 분산 처리가 된다.
Aggregation
특정 키 값을 이용하여 데이터를 그룹핑하는 개념
이러한 어그리게이션 작업은 내부적으로 셔플링(Shuffling)이라는 개념을 이용
키별로 데이터를 모으거나, 키별로 합산등의 계산을 위해서는 키별로 데이터를 모아서 특정 Worker Process에 보내야 한다.
ParDo를 이용하여 병렬 처리할 경우, 데이터가 키값에 상관 없이 여러 워커에 걸쳐서 분산되서 처리되기 때문에, 이를 재정렬해야 하는데, 이 재정렬 작업을 셔플링이라고 한다
(Hadoop의 MapReduce와 비슷한 개념)
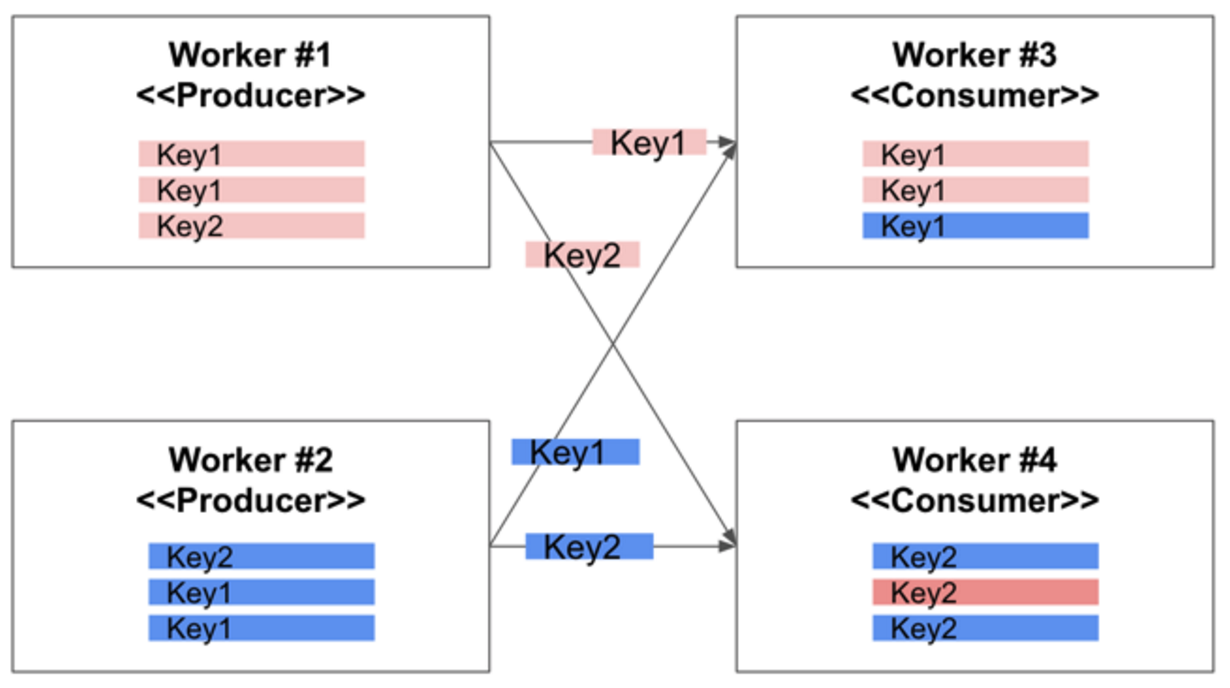
파이프라인 상에서 첫번째 프로세스를 Worker 1과 Worker 2가 처리, 결과는 Key1과 Key2를 키로 가지는 데이타라고 하자, 이를 어그리게이션 하면 아래 그림과 같이 Key1 데이타는 Worker 3로 모이고, Key 2 데이타는 Worker 4로 모인다. 이런 방식으로 셔플링이 이루어진다.
Dataflow의 Aggregation 종류
- Grouping
키 단위로 데이터를 묶어서 분류해주는 기능
PCollection<KV<String, Integer>> wordsAndLines = ...;
예제
cat, 1
dog, 5
and, 1
jump, 3
tree, 2
cat, 5
dog, 2
and, 2
cat, 9
and, 6
다음과 같이 String, Integer 페어의 KV가 있다고 했을때 GroupByKey를 사용하여 Grouping을 하게되면 아래와 같은 데이터가 나오게 된다.
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
사용 코드
PCollection<KV<String, Iterable<Integer>>> groupedWords = wordsAndLines.apply(GroupByKey.<String, Integer>create());
- Combine
키 단위로 데이터를 묶어서 연산해주는 기능
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(Combine.globally(new Sum.SumIntegerFn()));
다음 코드는 Integer로 들어오는 모든 값을 Combine에서 Sum 기능을 이용하여 모든 값을 더하는 코드이다. 전체 데이터에 적용을 했기때문에 Combine.globally()를 적용하였다.
예제
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
다음과 같은 형태의 데이터가 있을때 다음 코드를 이용해서 최소값 처리를 하게 되면 다음과 같은 결과를 가지게 된다.
PCollection<KV<String, Integer>> occurrences = ...;
PCollection<KV<String, Iterable<Integer>>> grouped = pc.apply(GroupByKey.create());
PCollection<KV<String, Integer>> firstOccurrences = pc.apply(Combine.groupedValues(new Min.MinIntegerFn()));
cat, [1]
dog, [2]
and, [1]
jump, [3]
tree, [2]
이 외에도 Transform안에 여러개의 Transform을 넣는 Composite Transform이나, 두개 이상의 데이터 스트림에서 데이터를 키에 따라 JOIN하는 기능들도 있다.
PCollection
PCollection은 데이터플로우 파이프라인 내에서 데이터를 저장하는 개념이다.
데이터는 PCollection 객체에 저장이 되어서 파이프라인을 통해서 Transform으로 넘겨진다.
PCollection은 한번 생성이 되면 그 데이터는 수정이 불가는하다.
Bounded & UnBounded PCollection
PCollection은 데이터 종류에 다라 Bounded PCollection과 Unbounded PCollection 두 가지로 나뉜다.
-
Bounded PCollection
배치 처리 처럼 데이터가 변화하지 않는 데이터로, 파일이나, 업데이트가 더 이상 발생하지 않는 테이블등을 생각하면 된다. 보통 TextI/O, BigQuery, DataStoreI/O 등을 이용해서 데이터를 읽은 경우에는 Bounded PCollection으로 처리가 된다. Bounded PCollection 데이터들은 배치 처리의 특성상 데이터를 한꺼번에 읽어서 처리한다. -
Unbounded PCollection
데이터가 계속 증가하는, 즉 스트리밍 데이터를 의미한다. 예를 들어 트위터 타임 라인이나, 스마트 폰에서 서버로 올라오는 이벤트 로그등을 들 수 있다.
이러한 Unbounded PCollection은 시간의 개념을 가지고 윈도우 처리를 해야하기 때문에, 객체내에 타임스템프가 자동으로 붙는다. Unbounded PCollection은 데이터를 BigQueryI/O 또는 Pub/Sub에서 읽을 때 생성된다.
특히 Unbounded PCollection에 Group이나 Combine등을 사용할 경우, 데이터가 파이프라인 상에서 언제 그룹핑된 데이터를 다음 Transform 컨포넌트로 넘겨야할지를 정의해야 하기 때문에, Window를 반드시 이용해야 한다.
PCollection의 데이터 타입
- 일반 데이터 타입 : PCollection
data - KV 데이터 타입 : PCollection<KV<String, Integer» data
- KV 이터레이터 타입 : PCollection<KV<String, Interable
>> data - Custom 타입 : 자바의 모델 객체의 형태로 정의 가능 이때는 어노테이션으로 @DefaultCoder(AvroCoder.class)를 정의하고 Avro 데이터 클래스임을 정의하면 된다.
@DefaultCoder(AvroCoder.class)
static class Stat{
Float sum;
Float avg;
Integer count;
Integer key;
Instant wStart; // windowStartTime
Instant wEnd; // windowEndTime
public Instant getwStart() {
return wStart;
}
public Instant getwEnd() {
return wEnd;
}
public Float getSum() {
return sum;
}
public Float getAvg() {
return avg;
}
public Integer getCount() {
return count;
}
public Integer getKey(){
return key;
}
public Stat(){}
public Stat(Integer k,Instant start,Instant end,Integer c,Float s,Float a){
this.key = k;
this.count = c;
this.sum = s;
this.avg = a;
this.wStart = start;
this.wEnd = end;
}
}
Window
스트리밍 데이터 처리를 할때 가장 중요한 개념이 윈도우이다.
특히나 Unbounded 데이터를 이용해 스트리밍 처리하는 Grouping이나 Combine시에는 반드시 윈도우를 이용해야 한다.
만약 Grouping이나 Combine과 같은 Aggregation을 하지 않으면, Unbounded data라도 윈도우 처리가 필요한다.
또한 Bounded 데이터도 데이터에 타임 스탬프를 추가하면 윈도우를 사용하여, 시간대별로 데이터를 처리할 수 있다.
Fixed Window 적용
PCollection 객체에 apply 메소드를 이용하여 Window.into 메서드를 이용하여 적용하면 된다.
PCollection<String> items = ...;
PCollection<String> fixed_windowed_items = items.apply(
Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES)));
item.apply를 이용하여 윈도우를 적용하는데, 데이터 타입이 String이기 때문에, Window.
윈도우 타입은 Fixed 윈도우이기 때문에, FixedWindows.of를 사용하였고, 윈도우 주기는 1분이라 1, TimeUnit.MINUTES를 적용하였다.
Sliding Window 적용
슬라이딩 윈도우는 윈도우의 크기(Duration)과 주기를 인자로 넘겨야 한다.
아래 코드는 5초 주기로 30분 크기의 윈도우를 생성하는 예제이다.
PCollection<String> items = ...;
PCollection<String> sliding_windowed_items = items.apply(Window.<String>into(SlidingWindows.of(Duration.standardMinutes(30)).every(Duration.standardSeconds(5))));
다음과 같이 하면 윈도우가 5초마다 생성이되고, 각 윈도우는 30분 단위의 크기를 가지게 된다.
Session Window 적용
세션 윈도우는 키별로 세션을 묶기 때문에 반드시 키가 필요하다.
userEvents.apply(Window.named("WindowIntoSessions")
.<KV<String, Integer>>into(Sessions.withGapDuration(Duration.standardMinutes(Duration.standardMinutes(10))))
.withOutputTimeFn(OutputTimeFns.outputAtEndOfWindow()))
.apply(Combine.perKey(x -> 0))
.apply("UserSessionActivity", ParDo.of(new UserSessionInfoFn()))
다른 윈도우들과 마찬가지로 Window.into를 이용하여 적용하는데, 데이터 형을 잘 보면 <KV<String, Integer» 형으로 정의된것을 확인할 수 있다. Sessions.withGapDuration으로 세션 윈도우를 정의한다.
이때 얼마간의 시간 동안 데이터가 없으면 세션으로 짜를지를 지정해줘야 하는데, Duration.standardMinutes(10)을 이용하여 10분간 해당 사용자에 대해서 데이터가 없으면 해당 사용자(=키)에 대해서 세션 윈도우를 자르도록 했다.
윈도우 시간 조회하기
윈도우를 사용하다보면, 이 윈도우의 시작과 종료 시간이 필요할때가 있다.
예) 고정크기 윈도우를 적용한 다음에, 이를 데이터베이스등에 저장할때, 이 윈도우가 언제시작해서 언제 끝난 윈도우인지를 조회하여 윈도우 시작 시간과 함께 값을 저장하고자 하는 케이스이다.
“1시에 몇 건, 1시 10분에 몇 건의 데이터가 저장되었다”와 같은 시나리오이다.
현재 윈도우에 대한 정보를 얻으려면 DoFn 클래스를 구현할때, com.google.cloud.dataflow.sdk.transforms.DoFn.RequiresWindowAccess 인터페이스를 implement 해야, 윈도우에 대한 정보를 액세스 할 수 있다.
static class StaticsDoFn extends DoFn<KV<Integer,Iterable<Twit>>, KV<Integer,Stat>> implements com.google.cloud.dataflow.sdk.transforms.DoFn.RequiresWindowAccess {
@Override
public void processElement(ProcessContext c) {
IntervalWindow w = (IntervalWindow) c.window();
Instant s = w.start();
Instant e = w.end();
DateTime sTime = s.toDateTime(org.joda.time.DateTimeZone.forID("Asia/Seoul"));
DateTime eTime = e.toDateTime(org.joda.time.DateTimeZone.forID("Asia/Seoul"));
DateTimeFormatter dtf = DateTimeFormat.forPattern("MM-dd-yyyy HH:mm:ss");
String str_stime = sTime.toString(dtf);
String str_etime = eTime.toString(dtf);
}
}
윈도우에 대한 정보는 ProcessContext c에서, c.window()를 호출하면, IntervalWindow라는 클래스로 윈도우에 대한 정보를 보내주고, 윈도우의 시작 시간과 종료 시간은 IntervalWindow 클래스의 start()와 end() 메서드를 이용해서 조회할 수 있다. 이 조회된 윈도우의 시작과 종료 시간은 org.joda.time.Instant 타입으로 리턴되는데, 조금 더 친숙한 DateTime 포맷으로 변환을 하려면, Instant.toDate() 메서드를 사용하면 되고, 이때, TimeZone 을 지정해주면 로컬 타임으로 변환을 하여, 윈도우의 시작과 종료시간을 조회할 수 있다.
타임 스탬프
윈도우는 시간을 기준으로 처리를 하기 때문에, 이 시간을 정의하는 타임스탬프를 어떻게 다루는지 이해할 필요가 있다.
-
타임 스탬프 생성
Pub/Sub을 이용하여 unbounded 데이터를 읽을 경우 타임스탬프가 Pub/Sub에 데이터가 들어간 시간을 Event time으로 하여, PCollection에 추가된다. -
타임 스탬프 지정하기
Pub/Sub에서와 같이 자동으로 타임 스탬프를 부여하는게 아니라, 모바일 디바이스에서 발생한 이벤트 타임이나, 어플리케이션에서 직접 타임스탬프를 부여할 수 있다. -
타임스탬프 부여 방법
c.output(데이터) -> c.outputWithTimestamp(데이터, 타임 스탬프)로 전달
모바일 서비스 분석등, 실제 시간에 근접한 분석을 하려면, 로그를 수집할때, 이벤트 발생 시간을 같이 REST API등을 통해서 수집하고, outputWithTimestamp를 이용하여, 수집된 이벤트 발생시간을 PCollection에 추가하는 방식으로 타임 스탬프를 반영 하는 것이 좋다.